YOLOv5-Lite 详解教程 | 嚼碎所有原理和思想、训练自己数据集、TensorRT部署落地应有尽有




YOLOv5 Lite在YOLOv5的基础上进行一系列消融实验,使其更轻(Flops更小,内存占用更低,参数更少),更快(加入shuffle channel,yolov5 head进行通道裁剪,在320的input_size至少能在树莓派4B上的推理速度可以达到10+FPS),更易部署(摘除Focus层和4次slice操作,让模型量化精度下降在可接受范围内)。


1输入端方法
1、Mosaic数据增强
YOLOv5 Lite的输入端采用了和YOLOv5、YOLOv4一样的Mosaic数据增强的方式。其实Mosaic数据增强的作者也是来自YOLOv5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。


为什么要进行Mosaic数据增强呢?
在平时训练模型时,一般来说小目标的AP比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。
首先看下小、中、大目标的定义:
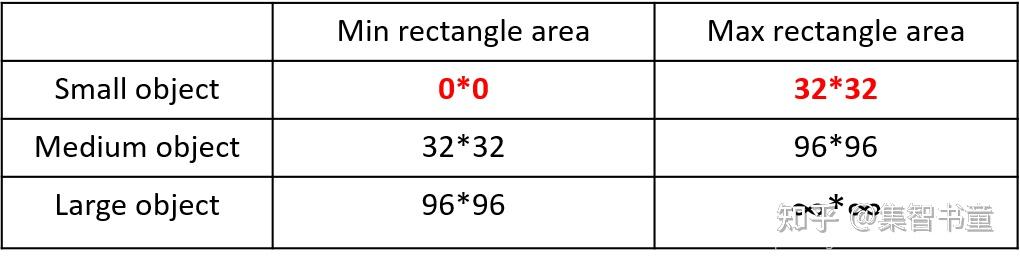

可以看到小目标的定义是目标框的长宽0×0~32×32之间的物体。


但在整体的数据集中,小、中、大目标的占比并不均衡。
如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
针对上述状况采用了Mosaic数据增强的方式,主要有几个优点:
- 丰富数据集
随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU使用
可能会有人说,随机缩放和普通的数据增强也可以做到类似的效果,在同等size的输入下,普通的数据增强只能看到一张图像,而Mosaic增强训练时可以直接计算4张图片的数据,这样即使一个GPU也可以达到比较好的效果。
2、自适应Anchor计算
YOLOv5 Lite依旧沿用YOLOv5的Anchor计算方式,我们知道,在YOLO算法之中,针对不同的数据集,都会设置固定的Anchor。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和Ground Truth进行比对,计算两者差距,再反向更新,迭代网络参数。
可以看出Anchor也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

第1行是在最大的特征图上的锚框;
第2行是在中间的特征图上的锚框;
第3行是在最小的特征图上的锚框;
自适应计算Anchor的流程如下:
- 载入数据集,得到数据集中所有数据的wh;
- 将每张图片中wh的最大值等比例缩放到指定大小img_size,较小边也相应缩放;
- 将bboxes从相对坐标改成绝对坐标(乘以缩放后的wh);
- 筛选bboxes,保留wh都大于等于两个像素的bboxes;
- 使用k-means聚类得到n个anchors(掉k-means包 涉及一个白化操作);
- 使用遗传算法随机对anchors的wh进行变异,如果变异后效果变得更好(使用anchor_fitness方法计算得到的fitness(适应度)进行评估)就将变异后的结果赋值给anchors,如果变异后效果变差就跳过,默认变异1000次;
1.3 自适应缩放图片
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如Yolo算法中常用416×416,608×608等尺寸。
但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。作者认为,在项目实际使用时,很多图片的长宽比不同。因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。


下面根据上图进行计算一下,主要是展示推理时的计算:
- 计算缩放比例
原始图像的尺寸为640×427,与640的输入尺寸计算得到2个缩放系数分别为1.0和1.499,这里选择较小的1.0参与缩放计算;
- 计算缩放后的尺寸
这里将原始尺寸乘以缩放系数1.0,可以分别得到长宽为640,427
- 计算灰边填充数值
640-427=213,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到21个像素,再除以2,即得到图片高度两端需要填充的数值(为10【向上取整】和11【向下取整】),于是得到推理结果的尺寸为640×448。
注意
只是在测试,使用模型推理时,才采用缩减灰边的方式,提高目标检测,推理的速度。 为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,以免产生尺度太小走不完stride的问题,再进行取余。
2模型架构


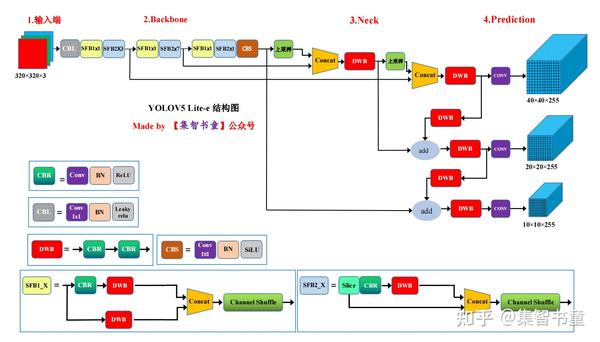
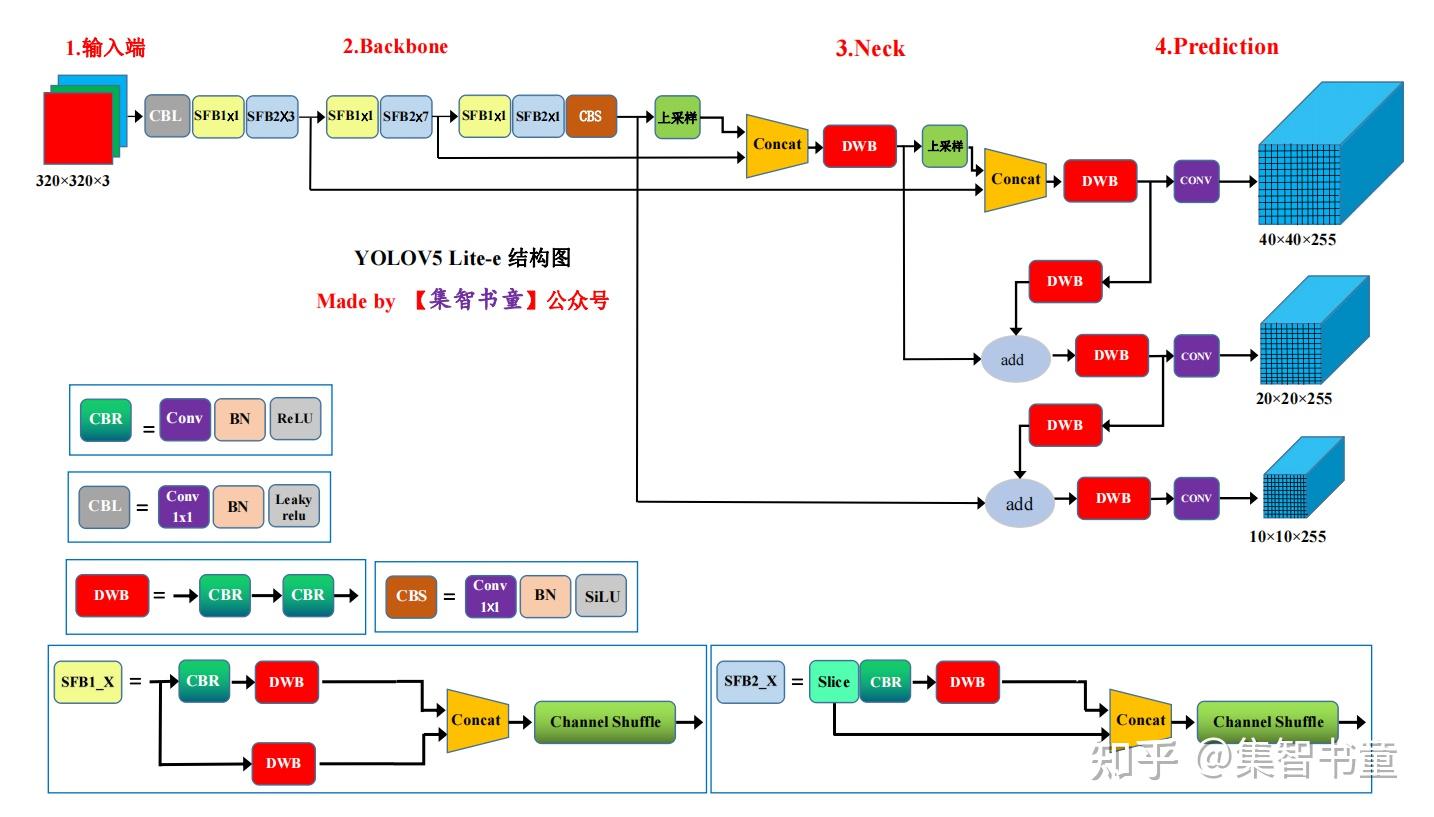
3.1 去除Focus层
为了充分理解,先来回顾一下Focus这个OP吧:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
从直观理解,其实就是将图像进行切片,类似于下采样取值,这样得到4个图像:
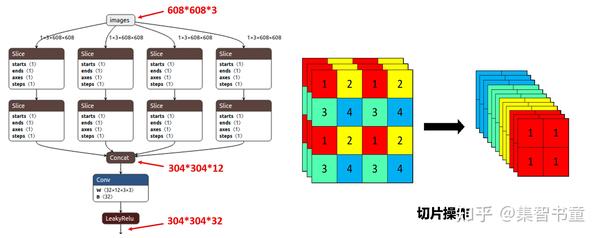

相当于是将空间信息绕到了通道信息中,cat后输入通道变成4倍,再通过conv得到新的featuremap,这样做的好处就是保持了下采样的信息没有丢失,图像的信息都保留了下来,但是在浅层中的应用,作者也表示了单纯是从计算量和参数量的角度上去设计,因为如上的所述的信息保存在浅层的意义并不大。所以后来查了下,作者的设计原因就是:为了减少浮点数和提高速度,而不是增加featuremap。
故,1个Focus可以替代更多的卷积层,而将空间信息聚焦到通道空间,这也会减少1像素的回归精度,而大部分的检测回归精度都不会接近1,这也是为什么Focus要放在输入的第1层上的原因。
一句话解释:Focus为了压缩网络层去提速。但是在YOLOv5 V6.0中,作者经过试验后,结论就是使用卷积替代Focus获得了更好的性能,且没有之前的一些局限性和副作用,因此此后的迭代中YOLO v5均去除了Focus操作。
YOLOv5 Lite也在此之前也不约而同的选择了摘除Focus层,避免多次采用slice操作,对于的芯片,特别是不含GPU、NPU加速的芯片,频繁的slice操作只会让缓存占用严重,加重计算处理的负担。同时,在芯片部署的时候,Focus层的转化对新手极度不友好。
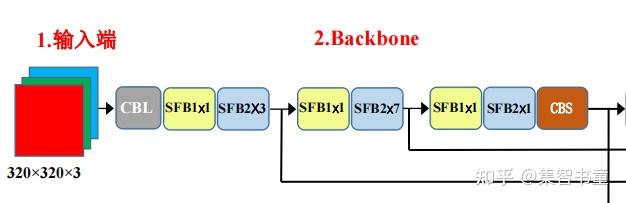
3.2 ShuffleNet Backbone
YOLOv5 Lite的Backbone选择的是ShuffleNet,为什么是ShuffleNet呢?
这里给出轻量化设计的4个准则:
- 同等通道大小可以最小化内存访问量;
- 过量使用组卷积会增加MAC;
- 网络过于碎片化(特别是多路)会降低并行度;
- 不能忽略元素级操作(比如shortcut和Add)。
同时,YOLOv5 Lite避免多次使用C3 Leyer以及高通道的C3 Layer
C3 Leyer是YOLOv5作者提出的CSPBottleneck改进版本,它更简单、更快、更轻,在近乎相似的损耗上能取得更好的结果。但C3 Layer采用多路分离卷积,测试证明,频繁使用C3 Layer以及通道数较高的C3 Layer,占用较多的缓存空间,减低运行速度。
为什么通道数越高的C3 Layer会对cpu不太友好?,主要还是因为Shufflenetv2的G1准则,通道数越高,hidden channels与c1、c2的阶跃差距更大,来个不是很恰当的比喻,想象下跳一个台阶和十个台阶,虽然跳十个台阶可以一次到达,但是你需要助跑,调整,蓄力才能跳上,可能花费的时间更久

针对ShuffleNet v2,作者首先复盘了ShuffleNetV1的问题,认为目前比较关键的问题是如何在全卷积或者分组卷积中维护大多数的卷积是平衡的。针对这个目标,作者提出了Channel Split的操作,同时构建了ShuffleNetV2。
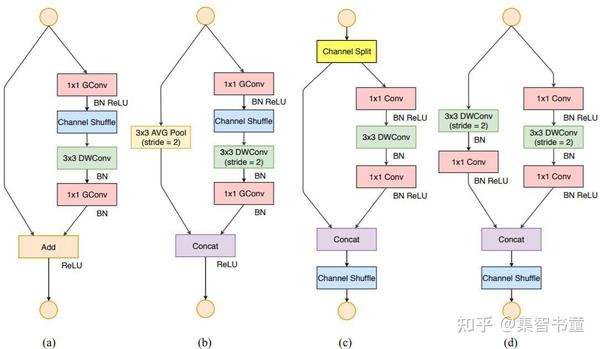
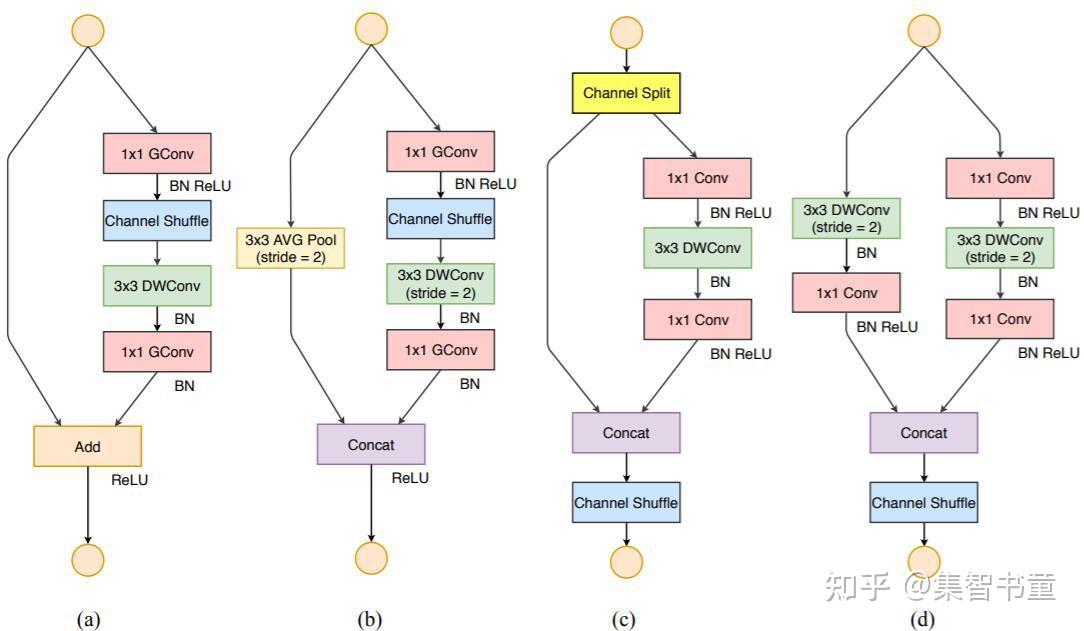
上图中(a)(b)是ShuffleNetV1的结构,而后面的(c)(d)是ShuffleNetV2的层结构,也是YOLOv5 Lite中的主要结构,分别对应的是结构图中的SFB1_X和SFB2_X


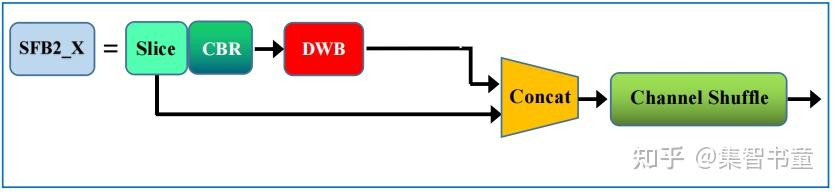

下面稍微讲一下笔者结合论文的理解:
Channel Split操作将整个特征图分为c’组(假设为A组)和c-c’(假设为B组)两个部分,主要有3个好处:
整个特征图分为2个组了,但是这样的分组又不像分组卷积一样,增加了卷积时的组数,符合准则2; 这样分开之后,将A组认为是通过short-cut通道的,而B组经过的bottleneck层的输入输出的通道数就可以保持一致,符合准则1;
同时由于最后使用的concat操作,没有用TensorAdd操作,符合准则4;
可以看到,这样一个简单的通道分离的操作带来了诸多好处;但是从理论上来说,这样的结构是否还符合short-cut的初衷(即bottleneck学到的是残差Residual部分)?这里笔者也不好妄加揣测,但是可以想到的是经过后面的Channel Shuffle的乱序之后,每个通道应该都会经过一次bottleneck结构。
上述的结构是不改变输入输出通道数和特征图大小的情况,而池化操作使用图(d)代替了,跟ShuffleNetV1类似,经过这样的结构之后,图像通道数扩张为原先的2倍。
YOLO v5 Lite在Backbone中还摘除shufflenetv2 backbone的1024 conv 和 5×5 pooling。
3.3 Neck
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。
而YOLO v5 Lite也不例外的使用了FPN+PAN的结构,但是Lite对yolov5 head进行通道剪枝,剪枝细则参考了ShuffleNet v2的设计准则,同时改进了YOLOv4中的FPN+PAN的结构,具体就是:
- 为了最优化内存的访问和使用,选择了使用相同的通道数量(e模型Neck通道为96);
- 为了进一步优化内存的使用,选择了使用原始的PANet结构,还原YOLOv4的cat操作为add操作;
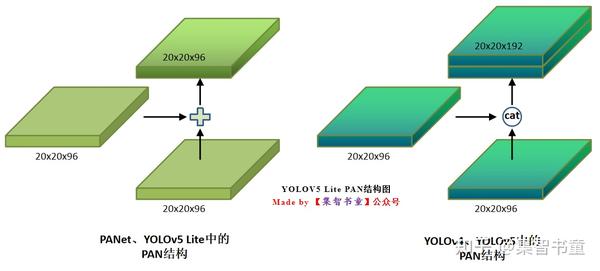



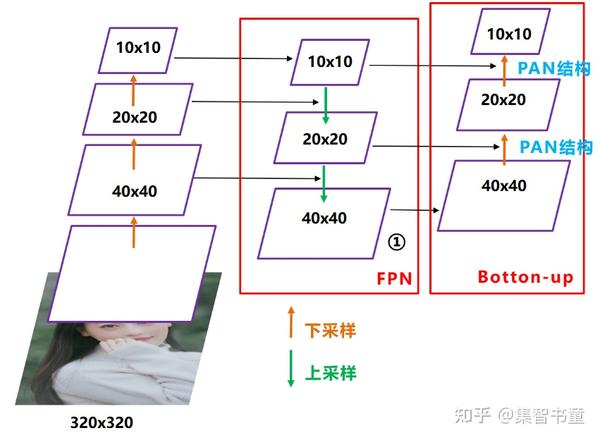

这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。


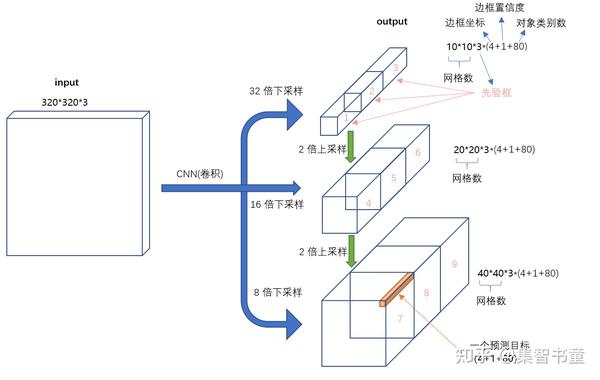
3.4 Head
对于Head部分,YOLO V5 Lite并没有对YOLOv5进行改进,所以可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255
②==>20×20×255
③==>10×10×255

3.5 Anchor机制及坐标变换
1、Anchor机制
对于YOLOv5,Anchor对应与Yolov3则恰恰相反,对于所设置的Anchor:
- 第一个Yolo层是最大的特征图40×40,对应最小的anchor box。
- 第二个Yolo层是中等的特征图20×20,对应中等的anchor box。
- 第三个Yolo层是最小的特征图10×10,对应最大的anchor box。
# anchors:
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32
2、样本匹配策略
在yolo v3&v4中,Anchor匹配策略和SSD、Faster RCNN类似:保证每个gt bbox有一个唯一的Anchor进行对应,匹配规则就是IOU最大,并且某个gt不能在三个预测层的某几层上同时进行匹配。不考虑一个gt bbox对应多个Anchor的场合,也不考虑Anchor是否设置合理。
这里先说一下YOLOv3的匹配策略:
假设一个图中有一个目标,这个被分割成三种格子的形式,分割成13×13 、26 × 26、52 × 52 。
- 这个目标中心坐标下采样8倍,(416/8=52),会落在 52 × 52 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样8倍的目标框)分别计算iou,得到3个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[0]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
- 这个目标中心坐标下采样16倍,(416/16=26),会落在 26 × 26 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样16倍的目标框)分别计算iou,得到三个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[1]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
- 这个目标中心坐标下采样32倍,(416/32=13),会落在 13 × 13 这个分支的所有格子中的某一个格子,落在的格子会产生3个anchor,3个anchor和目标(已经下采样32倍的目标框)分别计算iou,得到三个iou,凡是iou大于阈值0.3的,就记为正样本,就会将label[2]中这个iou大于0.3的anchor的相应位置 赋上真实框的值。
- 如果目标所有的anchor,9个anchor,iou全部小于阈值0.3,那么选择9个anchor中和下采样后的目标框iou最大的,作为正样本,将目标真实值赋值给相应的anchor的位置。
总的来说,就是将目标先进行3种下采样,分别和目标落在的网格产生的 9个anchor分别计算iou,大于阈值0.3的记为正样本。如果9个iou全部小于0.3,那么和目标iou最大的记为正样本。对于正样本,我们在label上 相对应的anchor位置上,赋上真实目标的值。
而yolov5采用了跨网格匹配规则,增加正样本Anchor数目的做法:
对于任何一个输出层,yolov5抛弃了Max-IOU匹配规则而采用shape匹配规则,计算标签box和当前层的anchors的宽高比,即:wb/wa,hb/ha。如果宽高比大于设定的阈值说明该box没有合适的anchor,在该预测层之间将这些box当背景过滤掉。
# r为目标wh和锚框wh的比值,比值在0.25到4之间的则采用该种锚框预测目标
r = t[:, :, 4:6] / anchors[:, None] # wh ratio:计算标签box和当前层的anchors的宽高比,即:wb/wa,hb/ha
# 将比值和预先设置的比例anchor_t对比,符合条件为True,反之False
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的2个网格,将这3个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,增加了3倍。code如下:
# Offsets
# 得到相对于以左上角为坐标原点的坐标
gxy = t[:, 2:4] # grid xy
# 得到相对于右下角为坐标原点的坐标
gxi = gain[[2, 3]] - gxy # inverse
# 这两个条件可以用来选择靠近的两个邻居网格
# jk和lm是判断gxy的中心点更偏向哪里
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
# yolov5不仅用目标中心点所在的网格预测该目标,还采用了距目标中心点的最近两个网格
# 所以有五种情况,网格本身,上下左右,这就是repeat函数第一个参数为5的原因
t = t.repeat((5, 1, 1))[j]
# 这里将t复制5个,然后使用j来过滤
# 第一个t是保留所有的gtbox,因为上一步里面增加了一个全为true的维度,
# 第二个t保留了靠近方格左边的gtbox,
# 第三个t保留了靠近方格上方的gtbox,
# 第四个t保留了靠近方格右边的gtbox,
# 第五个t保留了靠近方格下边的gtbox,
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
对于YOLOv5,不同于yolov3,yolov4的是:其gt box可以跨层预测,即有些gt box在多个预测层都算正样本;同时其gt box可匹配的anchor数可为3~9个,显著增加了正样本的数量。不再是gt box落在那个网格就只由该网格内的anchor来预测,而是根据中心点的位置增加2个邻近的网格的anchor来共同预测。
如下图所示,绿点表示该gt bbox中心,现在需要额外考虑其2个最近的邻域网格的anchor也作为该gt bbox的正样本,明显增加了正样本的数量。
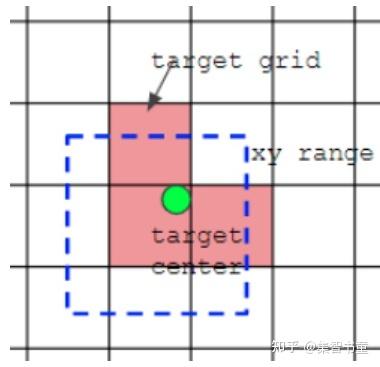
# 输入参数pred为网络的预测输出,它是一个list包含三个检测头的输出tensor。
def build_targets(self, p, targets):
'''
build_targets()函数的作用:找出与该gtbox最匹配的先验框(anchor)
'''
# 这里na为Anchor框种类数 nt为目标数 这里的na为3,nt为2
na, nt = self.na, targets.shape[0] # number of anchors, targets
# 类别 边界框 索引 锚框
tcls, tbox, indices, anch = [], [], [], []
# 利用gain来计算目标在某一个特征图上的位置信息,初始化为1
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
# 第2个维度复制nt遍
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
# targets.shape = (na, nt, 7)(3,2,7)给每个目标加上Anchor框索引
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
# 上下左右4个网格
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
], device=targets.device).float() * g # offsets
# 处理每个检测层(3个)
for i in range(self.nl):
'''
tensor([[[ 1.25000, 1.62500], #10,13, 16,30, 33,23 每一个数除以8
[ 2.00000, 3.75000],
[ 4.12500, 2.87500]],
[[ 1.87500, 3.81250], #30,61, 62,45, 59,119 每一个数除以16
[ 3.87500, 2.81250],
[ 3.68750, 7.43750]],
[[ 3.62500, 2.81250], #116,90, 156,198, 373,326 每一个数除以32
[ 4.87500, 6.18750],
[11.65625, 10.18750]]])
'''
# 3个anchors,已经除以当前特征图对应的stride
anchors = self.anchors[i]
# 将target中归一化后的xywh映射到3个尺度(80,80, 40,40, 20,20)的输出需要的放大系数
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# 将xywh映射到当前特征图,即乘以对应的特征图尺寸,targets*gain将归一化的box乘以特征图尺度,将box坐标分别投影到对应的特征图上
t = targets * gain
if nt:
# r为目标wh和锚框wh的比值,比值在0.25到4之间的则采用该种锚框预测目标
# 计算当前tartget的wh和anchor的wh比值
# 如果最大比值大于预设值model.hyp['anchor_t']=4,则当前target和anchor匹配度不高,不强制回归,而把target丢弃
r = t[:, :, 4:6] / anchors[:, None] # wh ratio:计算标签box和当前层的anchors的宽高比,即:wb/wa,hb/ha
# 筛选满足条件1/hyp['anchor_t] < target_wh / anchor_wh < hyp['anchor_t]的框
#.max(2)对第3维度的值进行max,将比值和预先设置的比例anchor_t对比,符合条件为True,反之False
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# 根据j筛选符合条件的坐标
t = t[j] # filter
# Offsets
# 得到相对于以左上角为坐标原点的坐标
gxy = t[:, 2:4] # grid xy
# 得到相对于右下角为坐标原点的坐标
gxi = gain[[2, 3]] - gxy # inverse
# 这2个条件可以用来选择靠近的2个临近网格
# jk和lm是判断gxy的中心点更偏向哪里(如果中心点的相对左上角的距离大于1,小于1.5,则满足临近选择的条件)
j, k = ((gxy % 1 < g) & (gxy > 1)).T
# jk和lm是判断gxi的中心点更偏向哪里(如果中心点的相对右下角的距离大于1,小于1.5,则满足临近选择的条件)
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
# yolov5不仅用目标中心点所在的网格预测该目标,还采用了距目标中心点的最近两个网格
# 所以有五种情况,网格本身,上下左右,这就是repeat函数第一个参数为5的原因
t = t.repeat((5, 1, 1))[j]
# 这里将t复制5个,然后使用j来过滤
# 第1个t是保留所有的gtbox,因为上一步里面增加了一个全为true的维度,
# 第2个t保留了靠近方格左边的gtbox,
# 第3个t保留了靠近方格上方的gtbox,
# 第4个t保留了靠近方格右边的gtbox,
# 第5个t保留了靠近方格下边的gtbox,
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
"""
对每个bbox找出对应的正样本anchor。
a 表示当前bbox和当前层的第几个anchor匹配
b 表示当前bbox属于batch内部的第几张图片,
c 是该bbox的类别
gi,gj 是对应的负责预测该bbox的网格坐标
gxy 负责预测网格中心点坐标xy
gwh 是对应的bbox的wh
"""
b, c = t[:, :2].long().T # image, class b表示当前bbox属于该batch内第几张图片
gxy = t[:, 2:4] # grid xy真实目标框的xy坐标
gwh = t[:, 4:6] # grid wh真实目标框的宽高
gij = (gxy - offsets).long() #取整
gi, gj = gij.T # grid xy indices (gi,gj)是计算出来的负责预测该gt box的网格的坐标
# Append
a = t[:, 6].long() # anchor indices a表示当前gt box和当前层的第几个anchor匹配上了
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # gtbox与3个负责预测的网格的坐标偏移量
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
最后返回四个列表:
- class:类别
- tbox:gtbox与3个负责预测的网格的xy坐标偏移量,gtbox的宽高
- indices:b表示当前gtbox属于该batch内第几张图片,a表示gtbox与anchors的对应关系,负责预测的网格纵坐标,负责预测的网格横坐标
- anch:最匹配的anchors
yolov5增加正样本的方法,最多可增大到原来的3倍,大大增加了正样本的数量,加速了模型的收敛。
目标检测重中之重可以理解为Anchor的匹配策略,当下流行的Anchor-Free不过换了一种匹配策略罢了。当下真正可创新之处在于更优的匹配策略。
3、正样本个数的增加策略
yolov5共有3个预测分支(FPN、PAN结构),共有9种不同大小的anchor,每个预测分支上有3种不同大小的anchor。Yolov5算法通过以下3种方法大幅增加正样本个数:
- 跨预测分支预测:假设一个ground truth框可以和2个甚至3个预测分支上的anchor匹配,则这2个或3个预测分支都可以预测该ground truth框,即一个ground truth框可以由多个预测分支来预测。
- 跨网格预测:假设一个ground truth框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据ground truth框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个ground truth框可以由3个网格来预测;
- 跨anchor预测:假设一个ground truth框落在了某个预测分支的某个网格内,该网格具有3种不同大小anchor,若ground truth可以和这3种anchor中的多种anchor匹配,则这些匹配的anchor都可以来预测该ground truth框,即一个ground truth框可以使用多种anchor来预测。
4、坐标变换
对于之前的YOLOv3和YOLOv4,使用的是如下图所示的坐标表示形式:
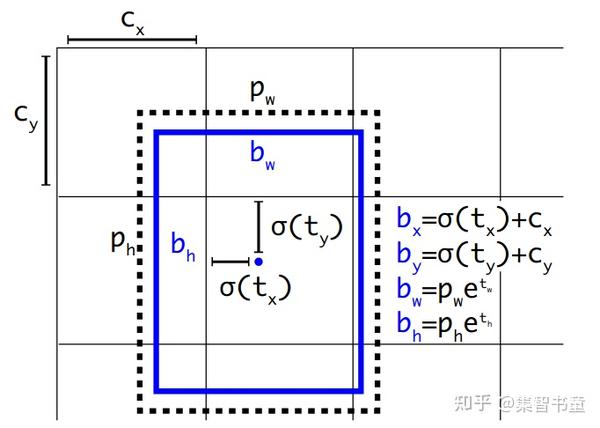

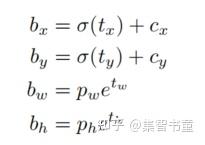
b_x、b_y、b_w、b_h分别是即边界框bbox相对于feature map的位置和宽高;
c_x和c_y分别代表feature map中grid cell的左上角坐标,在yolo中每个grid cell在feature map中的宽和高均为1;
p_w和p_y分别代表Anchor映射到feature map中的的宽和高,anchor box原本设定是相对于320\times 320坐标系下的坐标,需要除以stride如32映射到feature map坐标系中;
t_x、t_y、t_w、t_h这4个参数化坐标是网络学习的目标,其中t_x,t_y是预测的坐标偏移值,t_w和t_h是尺度缩放,sigma代表sigmoid函数。
与faster rcnn和ssd中的参数化坐标不同的是x和y的回归方式,YOLO v3&v4使用了sigmoid函数进行偏移量的规则化,而faster和ssd中对x,y除以anchor的宽和高进行规则化。
YOLOv5参数化坐标的方式和yolo v3&v4是不一样的,如下:
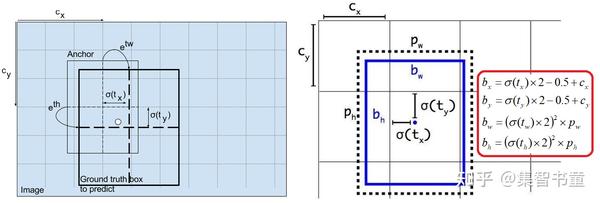

用公式表示如下:
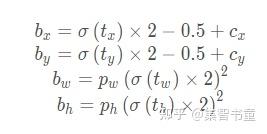
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
这样,pxy的取值范围是[-0.5,1.5],pwh的取值范围是(0,4×anchors[i]),这是因为采用了跨网格匹配规则,要跨网格预测了。
为什么这么改造呢?
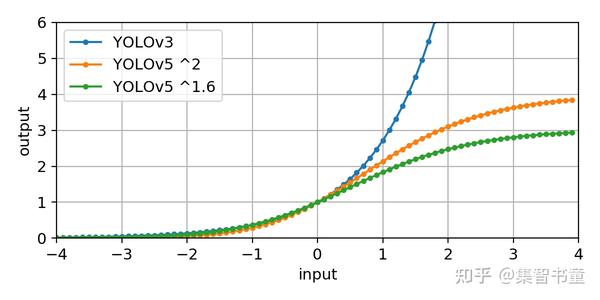

可以看出,对于不同的t_w和t_h,当他们大于零比较多时,YOLOv5的反馈更加平滑,相对于v3、v4也就更容易收敛。
5、为什么进行坐标参数化?
为什么要学习偏移而不是实际值?
Anchor已经粗略地“框住了”输入图像中的目标,明显的一个问题是,框的不够准确。因为受限于Anchor的生成方式,Anchor的坐标永远都是固定的那几个。所以,如果我们预测相对于Anchor的offset,那么,就可以通过预测的offset调整锚框位置,从而得到更精准的bounding box。
为什么要学习偏移系数而不是偏移量?
首先,对于预测的bounding box的w和h可以通过anchor进行缩放,但有一个基本的要求,就是h和w都必须为正值,而网络最后一层的预测输出是没法保证正负的,所以最简单的方法就是对预测输出求exp,这样就保证了预测值恒为正。那么反过来,对预测目标就是求log。
其次,对cx和cy除以anchor的宽和高的处理是为了做尺度归一化。例如,大的box的绝对偏移量一般较大,而小的box的绝对偏移量一般较小,除以宽和高消除这种影响。即两个框大小不一,但相对值却一致。
为什么都要进行Sigmoid计算?
yolov5需要的训练数据的label是根据原图尺寸归一化了的,这样做是因为怕大的边框的影响比小的边框影响大,因此做了归一化的操作,这样大的和小的边框都会被同等看待了,而且训练也容易收敛。所以在网络输出的部分也需要对输出进行归一化操作,因此选择了Sigmoid计算。
3输出端
4.1 优化方法
YOLO V5的作者提供了2个优化函数Adam和SGD,并都预设了与之匹配的训练超参数。默认为SGD。YOLO V4使用SGD。
YOLO V5的作者建议是,如果需要训练较小的自定义数据集,Adam是更合适的选择,尽管Adam的学习率通常比SGD低。但是如果训练大型数据集,对于YOLOV5来说SGD效果比Adam好。
实际上学术界上对于SGD和Adam哪个更好,一直没有统一的定论,取决于实际项目情况。
4.2 损失函数
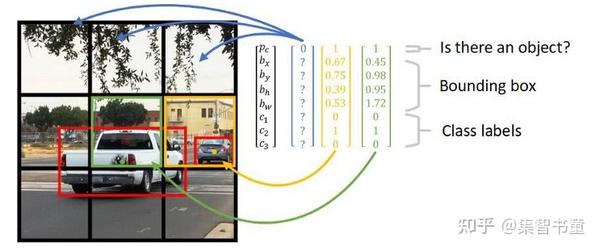

通过上图我们可以看到,对于图中的目标,都会输出class_num+4+1长度的向量,比如针对coco数据集有80个类别,就会输出长度为85的特征向量,其中所包含的内容如下图所示:
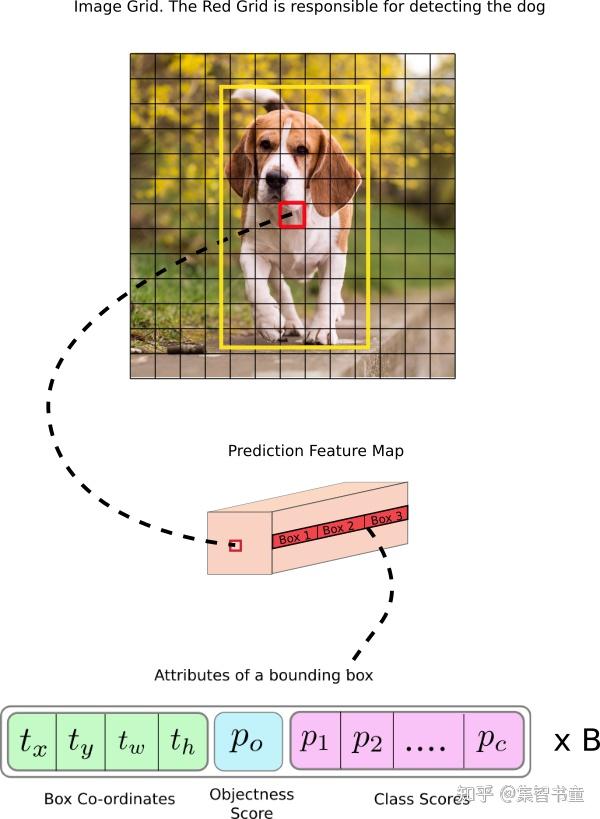

图中向量包含4个坐标信息,一个包含目标概率和80个类别得分,换句话解释就是“这个图像中是否有目标(物体出现的概率)?有的话是什么(80类的类别得分)?然后就是这个目标物体在哪里(box坐标位置)?”
其实面对上述的3个输出,也对应YOLOv5的3个分支的,其分别是obj分支、cls分支和box分支。
1、obj分支
obj分支输出的是该anchor中是否含有物体的概率,默认使用BCEWithLogits Loss。
BCEWithLogitsLoss是将BCELoss(BCE:Binary cross entropy)和sigmoid融合了,也就是说省略了sigmoid这个步骤;BCELoss的数学公式如下:
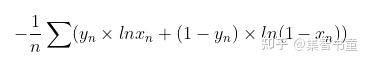
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super(BCEBlurWithLogitsLoss, self).__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
2、cls分支
cls分支输出的是该anchor属于哪一类的概率,也默认使用BCEWithLogits Loss。
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super(BCEBlurWithLogitsLoss, self).__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
例如,对于coco数据集上训练的YOLO的每个anchor的维度都是85,前5个属性是(Cx,Cy,w,h,confidence),confidence对应obj,后80个维度对应cls。
3、box分支
这里的box分支输出的便是物体的具体位置信息了,通过前面对于坐标参数化的分析可以知道,具体的输出4个值为t_x、t_y、t_w以及t_h,然后通过前面的参数化反转方式与GT进行计算loss,对于回归损失,yolov3使用的loss是smooth l1损失。Yolov5的边框(Bounding box)回归的损失函数默认使用的是CIoU,不是GIoU,不是DIoU,是CIoU。

下面用一张图粗略看一下IoU,GIoU,DIoU,CIoU:
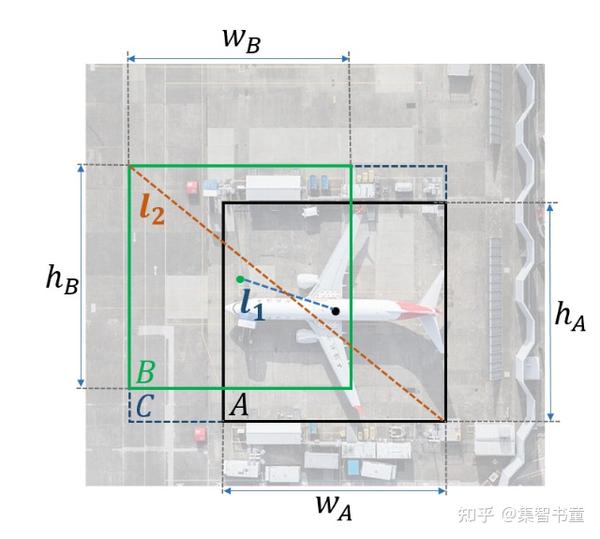



式中,x_A、y_A,x_B、y_B分别代表候选框的中心点坐标。
下面大概说一下每个IOU损失的局限性:
IoU Loss 有2个缺点:
- 当预测框和目标框不相交时,IoU(A,B)=0时,不能反映A,B距离的远近,此时损失函数不可导,IoU Loss 无法优化两个框不相交的情况。
- 假设预测框和目标框的大小都确定,只要两个框的相交值是确定的,其IoU值是相同时,IoU值不能反映两个框是如何相交的。
GIoU Loss 有1个缺点:
- 当目标框完全包裹预测框的时候,IoU和GIoU的值都一样,此时GIoU退化为IoU, 无法区分其相对位置关系;
DIoU Loss 有1个缺点:
- 当预测框的中心点的位置都一样时, DIoU无法区分候选框位置的质量;
综合IoU、GIoU、DIoU的种种局限性,总结一个好的bounding box regressor包含3个要素:
- 、Overlapping area
- 、Central point distance
- 、Aspect ratio
因此,YOLOv5使用的是CIoU Loss:


iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU
4、Loss计算
def compute_loss(p, targets, model): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = build_targets(p, targets, model) # targets
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['cls_pw']])).to(device)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['obj_pw']])).to(device)
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
cp, cn = smooth_BCE(eps=0.0)
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
。。。。。。
4.3、后处理之DIoU NMS
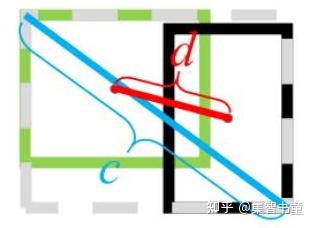
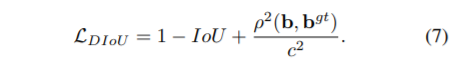



在上图重叠的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,也可以回归出来。因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
为什么不用CIoU NMS呢?
因为前面讲到的CIOU loss,是在DIOU loss的基础上,添加的影响因子,包含ground truth标注框的信息,在训练时用于回归。但在测试过程中,并没有ground truth的信息,不用考虑影响因子,因此直接用DIOU NMS即可。
4YOLOv5 Lite训练自己的数据集
5.1 git clone仓库代码
clone YOLOv5 Lite代码并下载coco的预训练权重。
$ git clone https://github.com/ppogg/YOLOv5-Lite
$ cd YOLOv5-Lite
$ pip install -r requirements.txt
5.2 处理数据集格式
这里可以直接参考coco128的数据集形式进行整理:
文件夹目录如下图所示:


5.3 配置超参数
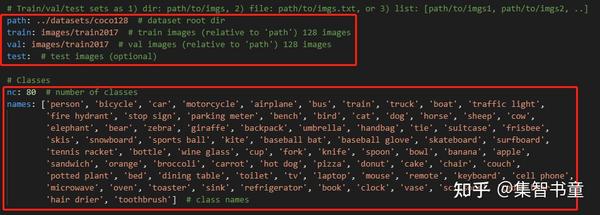
主要是配置data文件夹下的coco128.yaml中的数据集位置和种类:

5.4 配置模型
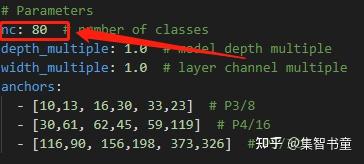
这里主要是配置models目录下的模型yaml文件,主要是进去后修改nc这个参数来进行类别的修改。
目前支持的模型种类如下所示:

5.3 训练
$ python train.py --data coco.yaml --cfg v5lite-e.yaml --weights v5lite-e.pt --batch-size 128
v5lite-s.yaml --weights v5lite-s.pt --batch-size 128
v5lite-c.yaml v5lite-c.pt 96
v5lite-g.yaml v5lite-g.pt 64
如果您是多卡进行训练,则:
$ python -m torch.distributed.launch --nproc_per_node 2 train.py
5.4 检测结果
$ python path/to/detect.py --weights v5lite-e.pt --source 0 img.jpg # image


5TensorRT部署
5.1 目标检测常见的落地形式

1、TensorRT是什么
TensorRT是推理优化器,能对训练好的模型进行优化。可以理解为只有前向传播的深度学习框架,这个框架可以将Caffe,TensorFlow的网络模型解析,然后与TensorRT中对应的层进行一一映射,把其他框架的模型统一全部转换到TensorRT中,然后在TensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。当你的网络训练完之后,可以将训练模型文件直接丢进TensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等)。
2、本文AI部署流程
先把onnx转化为TensorRT的Engine文件,然后让c++环境下的TensorRT直接加载Engine文件,从而构建engine,本文主要讲解onnx转换至Engine,然后进行基于TensorRT的C++推理检测。


转换和部署模型5个基本步骤:
- step1:获取模型
- step2:选择batchsize
- step3:选择精度
- step4:模型转换
- step5:模型部署
5.2 ONNX-TensorRT的部署流程
1、ONNX转化为TRT Engine
# 导出onnx文件
python export.py ---weights weights/v5lite-g.pt --batch-size 1 --imgsz 640 --include onnx --simplify
# 使用TensorRT官方的trtexec工具将onnx文件转换为engine
trtexec --explicitBatch --onnx=./v5lite-g.onnx --saveEngine=v5lite-g.trt --fp16
闲话不多说,这里已经拿到了trt的engine,那么如何进行推理呢?总的来说,分为3步:
- 首先load你的engine,拿到一个ICudaEngine, 这个是TensorRT推理的核心;
- 定位模型的输入和输出,有几个输入有几个输出;
- forward模型,然后拿到输出,对输出进行后处理。
当然这里最核心的东西其实就两个,一个是如何导入拿到CudaEngine,第二个是比较麻烦的后处理。
2、加载TRT Engine
bool Model::readTrtFile() {
std::string cached_engine;
std::fstream file;
std::cout << "loading filename from:" << engine_file << std::endl;
nvinfer1::IRuntime *trtRuntime;
file.open(engine_file, std::ios::binary | std::ios::in);
if (!file.is_open()) {
std::cout << "read file error: " << engine_file << std::endl;
cached_engine = "";
}
while (file.peek() != EOF) {
std::stringstream buffer;
buffer << file.rdbuf();
cached_engine.append(buffer.str());
}
file.close();
trtRuntime = nvinfer1::createInferRuntime(gLogger.getTRTLogger());
engine = trtRuntime->deserializeCudaEngine(cached_engine.data(), cached_engine.size(), nullptr);
std::cout << "deserialize done" << std::endl;
}
// 加载 TensorRT Engine
void v5Lite::LoadEngine() {
// create and load engine
std::fstream existEngine;
existEngine.open(engine_file, std::ios::in);
// 如果存在已经转换完成的TensorRT Engine文件,则直接加载
if (existEngine) {
readTrtFile(engine_file, engine);
assert(engine != nullptr);
}
// 如果不存在已经转换完成的TensorRT Engine文件,则直接加载ONNX权重进行在线生成
else {
onnxToTRTModel(onnx_file, engine_file, engine, BATCH_SIZE);
assert(engine != nullptr);
}
}
3、后处理之坐标转换
std::vector<std::vector<V5lite::DetectRes>> V5lite::postProcess(const std::vector<cv::Mat> &vec_Mat, float *output,
const int &outSize) {
std::vector<std::vector<DetectRes>> vec_result;
int index = 0;
for (const cv::Mat &src_img : vec_Mat)
{
std::vector<DetectRes> result;
float ratio = float(src_img.cols) / float(IMAGE_WIDTH) > float(src_img.rows) / float(IMAGE_HEIGHT) ? float(src_img.cols) / float(IMAGE_WIDTH) : float(src_img.rows) / float(IMAGE_HEIGHT);
float *out = output + index * outSize;
int position = 0;
for (int n = 0; n < (int)grids.size(); n++)
{
for (int c = 0; c < grids[n][0]; c++)
{
std::vector<int> anchor = anchors[n * grids[n][0] + c];
for (int h = 0; h < grids[n][1]; h++)
for (int w = 0; w < grids[n][2]; w++)
{
float *row = out + position * (CATEGORY + 5);
position++;
DetectRes box;
auto max_pos = std::max_element(row + 5, row + CATEGORY + 5);
box.prob = row[4] * row[max_pos - row];
if (box.prob < obj_threshold)
continue;
box.classes = max_pos - row - 5;
// 坐标的反参数化,和前文的坐标转换对接
box.x = (row[0] * 2 - 0.5 + w) / grids[n][2] * IMAGE_WIDTH * ratio;
box.y = (row[1] * 2 - 0.5 + h) / grids[n][1] * IMAGE_HEIGHT * ratio;
box.w = pow(row[2] * 2, 2) * anchor[0] * ratio;
box.h = pow(row[3] * 2, 2) * anchor[1] * ratio;
result.push_back(box);
}
}
}
NmsDetect(result);
vec_result.push_back(result);
index++;
}
return vec_result;
}
4、进行模型推理
// 推理整个文件夹的文件
bool YOLOv5::InferenceFolder(const std::string &folder_name) {
// 读取文件夹下面的文件,并返回为一个 string vector 迭代器
std::vector<std::string> sample_images = readFolder(folder_name);
//get context
assert(engine != nullptr);
// 创建上下文,创建一些空间来存储中间值。一个engine可以创建多个context,分别执行多个推理任务。
context = engine->createExecutionContext();
assert(context != nullptr);
// 传递给Engine的输入输出buffers指针,这里对应一个输入和一个输出
assert(engine->getNbBindings() == 2);
void *buffers[2];
std::vector<int64_t> bufferSize;
int nbBindings = engine->getNbBindings();
bufferSize.resize(nbBindings);
for (int i = 0; i < nbBindings; ++i) {
// 获取输入或输出的维度信息
nvinfer1::Dims dims = engine->getBindingDimensions(i);
// 获取输入或输出的数据类型信息
nvinfer1::DataType dtype = engine->getBindingDataType(i);
int64_t totalSize = volume(dims) * 1 * getElementSize(dtype);
bufferSize[i] = totalSize;
std::cout << "binding" << i << ": " << totalSize << std::endl;
// &buffers是双重指针 相当于改变指针本身,这里就是把输入或输出进行向量化操作
cudaMalloc(&buffers[i], totalSize);
}
//get stream
cudaStream_t stream;
// 创建 Stream
cudaStreamCreate(&stream);
int outSize = bufferSize[1] / sizeof(float) / BATCH_SIZE;
// 执行推理
EngineInference(sample_images, outSize, buffers, bufferSize, stream);
// 释放 stream 和 buffers
cudaStreamDestroy(stream);
cudaFree(buffers[0]);
cudaFree(buffers[1]);
// destroy the engine
context->destroy();
engine->destroy();
}
void YOLOv5::EngineInference(const std::vector<std::string> &image_list, const int &outSize, void **buffers,
const std::vector<int64_t> &bufferSize, cudaStream_t stream) {
int index = 0;
int batch_id = 0;
std::vector<cv::Mat> vec_Mat(BATCH_SIZE);
std::vector<std::string> vec_name(BATCH_SIZE);
float total_time = 0;
// 遍历图像路径list
for (const std::string &image_name : image_list)
{
index++;
std::cout << "Processing: " << image_name << std::endl;
// 读取图像内容到cv_mat
cv::Mat src_img = cv::imread(image_name);
// 把图像和图像名分别保存在vec_Mat和vec_name之中
if (src_img.data)
{
vec_Mat[batch_id] = src_img.clone();
vec_name[batch_id] = image_name;
batch_id++;
}
if (batch_id == BATCH_SIZE or index == image_list.size())
{
// 声明时间戳 t_start_pre
auto t_start_pre = std::chrono::high_resolution_clock::now();
std::cout << "prepareImage" << std::endl;
std::vector<float>curInput = prepareImage(vec_Mat);
auto t_end_pre = std::chrono::high_resolution_clock::now();
// 至此,prepare Image的时间已经计算完成
float total_pre = std::chrono::duration<float, std::milli>(t_end_pre - t_start_pre).count();
std::cout << "prepare image take: " << total_pre << " ms." << std::endl;
total_time += total_pre;
batch_id = 0;
if (!curInput.data()) {
std::cout << "prepare images ERROR!" << std::endl;
continue;
}
// 将数据从CPU端传送到GPU端
std::cout << "host2device" << std::endl;
cudaMemcpyAsync(buffers[0], curInput.data(), bufferSize[0], cudaMemcpyHostToDevice, stream);
// 执行推理
std::cout << "execute" << std::endl;
auto t_start = std::chrono::high_resolution_clock::now();
context->execute(BATCH_SIZE, buffers);
auto t_end = std::chrono::high_resolution_clock::now();
float total_inf = std::chrono::duration<float, std::milli>(t_end - t_start).count();
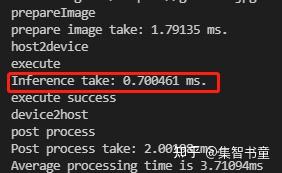
std::cout << "Inference take: " << total_inf << " ms." << std::endl;
total_time += total_inf;
std::cout << "execute success" << std::endl;
std::cout << "device2host" << std::endl;
std::cout << "post process" << std::endl;
auto r_start = std::chrono::high_resolution_clock::now();
auto *out = new float[outSize * BATCH_SIZE];
// Copy GPU端的推理结果到CPU端
cudaMemcpyAsync(out, buffers[1], bufferSize[1], cudaMemcpyDeviceToHost, stream);
// 阻塞当前程序的执行,直到所有任务都处理完毕,这样可以将计算和主机与设备之前的传输并行化,提高效率。
cudaStreamSynchronize(stream);
// 进行后处理操作
auto boxes = postProcess(vec_Mat, out, outSize);
auto r_end = std::chrono::high_resolution_clock::now();
float total_res = std::chrono::duration<float, std::milli>(r_end - r_start).count();
std::cout << "Post process take: " << total_res << " ms." << std::endl;
total_time += total_res;
for (int i = 0; i < (int)vec_Mat.size(); i++)
{
auto org_img = vec_Mat[i];
if (!org_img.data)
continue;
auto rects = boxes[i];
for(const auto &rect : rects)
{
char t[256];
sprintf(t, "%.2f", rect.prob);
std::string name = coco_labels[rect.classes] + "-" + t;
// 图书添加文字
cv::putText(org_img, name, cv::Point(rect.x - rect.w / 2, rect.y - rect.h / 2 - 5), cv::FONT_HERSHEY_COMPLEX, 0.7, class_colors[rect.classes], 2);
// 绘制矩形框
cv::Rect rst(rect.x - rect.w / 2, rect.y - rect.h / 2, rect.w, rect.h);
cv::rectangle(org_img, rst, class_colors[rect.classes], 2, cv::LINE_8, 0);
}
int pos = vec_name[i].find_last_of(".");
std::string rst_name = vec_name[i].insert(pos, "_");
std::cout << rst_name << std::endl;
// 保存检测结果
cv::imwrite(rst_name, org_img);
}
vec_Mat = std::vector<cv::Mat>(BATCH_SIZE);
delete[] out;
}
}
std::cout << "Average processing time is " << total_time / image_list.size() << "ms" << std::endl;
}
5、后处理之NMS C++实现
void V5lite::NmsDetect(std::vector<DetectRes> &detections) {
sort(detections.begin(), detections.end(), [=](const DetectRes &left, const DetectRes &right) {
return left.prob > right.prob;
});
for (int i = 0; i < (int)detections.size(); i++)
for (int j = i + 1; j < (int)detections.size(); j++)
{
if (detections[i].classes == detections[j].classes)
{ // 计算DIoU的值
float iou = IOUCalculate(detections[i], detections[j]);
if (iou > nms_threshold)
detections[j].prob = 0;
}
}
detections.erase(std::remove_if(detections.begin(), detections.end(), [](const DetectRes &det)
{ return det.prob == 0; }), detections.end());
}
// 计算 DIOU
float v5Lite::IOUCalculate(const YOLOv5::DetectRes &det_a, const YOLOv5::DetectRes &det_b) {
cv::Point2f center_a(det_a.x, det_a.y);
cv::Point2f center_b(det_b.x, det_b.y);
// 计算左上角角点坐标
cv::Point2f left_up(std::min(det_a.x - det_a.w / 2, det_b.x - det_b.w / 2),
std::min(det_a.y - det_a.h / 2, det_b.y - det_b.h / 2));
// 计算右下角角点坐标
cv::Point2f right_down(std::max(det_a.x + det_a.w / 2, det_b.x + det_b.w / 2),
std::max(det_a.y + det_a.h / 2, det_b.y + det_b.h / 2));
// 计算框的中心点距离
float distance_d = (center_a - center_b).x * (center_a - center_b).x + (center_a - center_b).y * (center_a - center_b).y;
// 计算框的角点距离
float distance_c = (left_up - right_down).x * (left_up - right_down).x + (left_up - right_down).y * (left_up - right_down).y;
float inter_l = det_a.x - det_a.w / 2 > det_b.x - det_b.w / 2 ? det_a.x - det_a.w / 2 : det_b.x - det_b.w / 2;
float inter_t = det_a.y - det_a.h / 2 > det_b.y - det_b.h / 2 ? det_a.y - det_a.h / 2 : det_b.y - det_b.h / 2;
float inter_r = det_a.x + det_a.w / 2 < det_b.x + det_b.w / 2 ? det_a.x + det_a.w / 2 : det_b.x + det_b.w / 2;
float inter_b = det_a.y + det_a.h / 2 < det_b.y + det_b.h / 2 ? det_a.y + det_a.h / 2 : det_b.y + det_b.h / 2;
if (inter_b < inter_t || inter_r < inter_l)
return 0;
// 计算交集
float inter_area = (inter_b - inter_t) * (inter_r - inter_l);
// 计算并集
float union_area = det_a.w * det_a.h + det_b.w * det_b.h - inter_area;
if (union_area == 0)
return 0;
else
return inter_area / union_area - distance_d / distance_c;
}
CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.5)
project(v5lite_trt)
set(CMAKE_CXX_STANDARD 14)
# CUDA
find_package(CUDA REQUIRED)
message(STATUS "Find CUDA include at ${CUDA_INCLUDE_DIRS}")
message(STATUS "Find CUDA libraries: ${CUDA_LIBRARIES}")
# TensorRT
set(TENSORRT_ROOT "/home/chaucer/TensorRT-8.0.1.6")
find_path(TENSORRT_INCLUDE_DIR NvInfer.h
HINTS ${TENSORRT_ROOT} PATH_SUFFIXES include/)
message(STATUS "Found TensorRT headers at ${TENSORRT_INCLUDE_DIR}")
find_library(TENSORRT_LIBRARY_INFER nvinfer
HINTS ${TENSORRT_ROOT} ${TENSORRT_BUILD} ${CUDA_TOOLKIT_ROOT_DIR}
PATH_SUFFIXES lib lib64 lib/x64)
find_library(TENSORRT_LIBRARY_ONNXPARSER nvonnxparser
HINTS ${TENSORRT_ROOT} ${TENSORRT_BUILD} ${CUDA_TOOLKIT_ROOT_DIR}
PATH_SUFFIXES lib lib64 lib/x64)
set(TENSORRT_LIBRARY ${TENSORRT_LIBRARY_INFER} ${TENSORRT_LIBRARY_ONNXPARSER})
message(STATUS "Find TensorRT libs: ${TENSORRT_LIBRARY}")
# OpenCV
find_package(OpenCV REQUIRED)
message(STATUS "Find OpenCV include at ${OpenCV_INCLUDE_DIRS}")
message(STATUS "Find OpenCV libraries: ${OpenCV_LIBRARIES}")
set(COMMON_INCLUDE ./includes/common)
set(YAML_INCLUDE ./includes/yaml-cpp/include)
set(YAML_LIB_DIR ./includes/yaml-cpp/libs)
include_directories(${CUDA_INCLUDE_DIRS} ${TENSORRT_INCLUDE_DIR} ${OpenCV_INCLUDE_DIRS} ${COMMON_INCLUDE} ${YAML_INCLUDE})
link_directories(${YAML_LIB_DIR})
add_executable(v5lite_trt main.cpp v5lite.cpp)
target_link_libraries(v5lite_trt ${OpenCV_LIBRARIES} ${CUDA_LIBRARIES} ${TENSORRT_LIBRARY} yaml-cpp)
mkdir build
cd build
cmake ..
make -j8
v5lite_trt ../config.yaml ../samples/
5、检测结果和时间