
Kaggle新手银牌(21st):Airbus Ship Detection 卫星图像分割检测



0、前言
10月下旬到11月中旬大概二十天的时间,打了一个Kaggle的遥感图像分割检测比赛 Airbus Ship Detection Challenge ,airbus也就是空中客车公司,悬赏金额6万美金。
比赛已经结束了,Rank 21/884,TOP2.4%,银牌,这是我第一次打kaggle图像类的比赛,二十天时间取得的成绩不算特别好,但我还是比较满意的,因为这个过程中学到了不少东西。趁这个机会做一下竞赛过程的梳理和分享,给大家提供一个竞赛的baseline,帮助新人快速上手,为自己攒人品。
这个比赛有几个问题,需要和大家说明一下:
(1)比赛期间发生了严重的数据泄露,LB上出现大量满分成绩,主办方不得不重新制作数据集,并重置了原有成绩。因此,所有人需要根据新的数据集重新训练重新测试重新提交结果,这件事情严重打击了大家的参赛热情,最终参赛人数仅有800+,隔壁另一个图像类的比赛还有两个月结束却已经有了900+的参赛人数,差距显著。
(2)比赛的public leadboard 和 private leadboard存在显著差异,说明测试数据集的分配存在很大的问题,这在discussion区已经有人提出了,说本地交叉验证集的结果比较靠谱;
相信kaggle官方会不断完善,解决这次比赛暴露出来的问题。但是对于参赛者,名次不是最重要的,学到东西最重要,kernel和discussion区分享的资料让人获益匪浅。相比于国内的大数据竞赛平台,Kaggle不仅是竞赛平台,也是学习和分享的平台,这一点差距还是挺大的。
1、比赛介绍
(0)背景介绍
航运流量增长迅速。更多的船只增加了海上违规行为的机会,这迫使许多组织对公海进行更密切的监视。在过去的10年里,人们做了大量的工作,从卫星图像中自动提取目标,取得了显著的效果,但在实际操作中存在许多不足。现在空中客车公司与kaggle共同举办比赛,寻求更好更快的船舶自动检测方案。
(1)比赛任务:从卫星图片中找到所有的船只
比赛的名字是船只检测,但实际上要做的不是目标检测,可能更接近实例分割,参赛者需要用mask掩码来表示检测到的目标,大概就是下面这种形式:


(2)数据的描述:
在本次竞赛中,需要在图像中定位船只,许多图像不包含船只,而也有部分图片包含多个船只;这个比赛的数据集非常大,光训练集就有28G,且由于Kaggle服务器在国外,所以数据集的下载很困难,我建议用迅雷或者kaggle api,也有人建议kaggle cli;


(3)评价标准:
这个比赛的评分依据主要是不同IOU阈值下的F2-Score。对于一张图片中的某个目标,如果预测值和真实值的IOU超过预设阈值,则认为该目标识别成功。换言之,取阈值为0.5时,如果预测对象与真实值对象的交集大于0.5,则视为识别成功。该赛题的识别阈值有10个:(0.5,0.55,0.6,0.65,0.7,0.75,0.8,0.85,0.9,0.95)。单个图像的得分是每个IOU阈值上的F2得分值的平均值,最后,竞赛的最终分数是对测试数据集中每个图像的单个平均F2分数取出的平均值得。
2、敲定主体框架(Mask R-CNN in Detectron by Caffe2)
第一直觉这是个实例分割任务,首选Mask R-CNN。
当时期间Mask R-CNN有两大开源版本,一个是Matter Port的Keras版代码,另一个是Facebook官方的Caffe2版代码(即Detectron)。
据说Detectron的性能优于Matter Port 10个百分点,因此我直接选择了性能更好的Detectron。其实11月初官方又开源了Pytorch版本Mask R-CNN,如果这个早一点开源的话,首选的必定是Pytorch版,因为这样子代码能好改很多,这个就暂且不表了。
3、数据扩增
遥感图像有一个很大的特点,就是多方向性。传统数据集里面,人可以说都是站着的,应该没有人倒着的情况吧。夸张点说,说不定CNN就觉得,躯干上顶个圆球脑袋的东西就是人,万一哪天检测一个倒立的人说不定就识别不出来了。
遥感数据集的这个问题就严重,遥数据集多是俯拍,船只的朝向东南西北都有可能的,因此训练集里的朝向应当要丰富,避免学习到的模型不具有泛性。
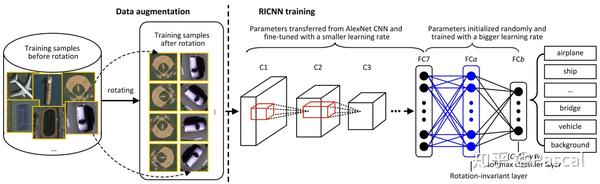

针对这个问题有很多解决方案,上面这张图是某篇论文的方法,主要改进是在模型里面增加了一个旋转不变层,以解决遥感图像多方向性问题。鉴于评论区的需求,附上论文信息:
Cheng, Gong , P. Zhou , and J. Han . "RIFD-CNN: Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection."2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)IEEE Computer Society, 2016.
抛开这篇论文,我说两个比较容易实现的方法:
(1)数据扩增:
我采取了下面几种数据增强方法:随机90°倍数旋转(P=1),水平翻转(p=0.25),随机亮度(p=0.2,limit=0.2),随机对比(p=0.1,limit=0.2)等等。
(2)TTA单图多测:
TTA阶段将待测图片翻转、旋转获取多个待测图片,然后同一个模型对这几张图片分别检测,投票产生最终检测结果,提高系统鲁棒性。
4、制作数据集
竞赛数据集是RLE格式的,具体可见这里 RLE 。
数据集的制作其实非常麻烦,我制作的是标准COCO数据集,具体参见:
{
"id": 27614,
"image_id": 14332,
"category_id": 1,
"iscrowd": 0,
"area": 3307,
"bbox": [
168.0,
65.0,
170.0,
24.0
],
"segmentation": [
[
189.0,
88.5,
168.0,
88.5,
167.5,
70.0,
336.5,
65.0,
337.0,
84.5,
189.0,
88.5
]
],
"width": 768,
"height": 768
},pascal1129/kaggle_airbus_ship_detection {
"id": 27614,
"image_id": 14332,
"category_id": 1,
"iscrowd": 0,
"area": 3307,
"bbox": [
168.0,
65.0,
170.0,
24.0
],
"segmentation": [
[
189.0,
88.5,
168.0,
88.5,
167.5,
70.0,
336.5,
65.0,
337.0,
84.5,
189.0,
88.5
]
],
"width": 768,
"height": 768
},

很多图片的标注效果很差,在数据集制作过程中已经跳过这些图片了。


比赛中,训练集共192556张图片,其中无船空图150000张(77.9%),含船图42556张(22.1%),可以看出来负样本很多。
我在制作数据集的时候暂时弃掉了无图样本,是为了提升训练速度,但是最后几个epoch要把所有的样本放进来训练,抑制假阳性。
5、模型训练
Detectron训练Mask R-CNN比较麻烦,环境我用的是官方docker容器,数据集信息需要添加进入 dataset_catalog.py,然后通过train_net.py训练模型,训练还是比较快的,印象中一天不到就有结果了。
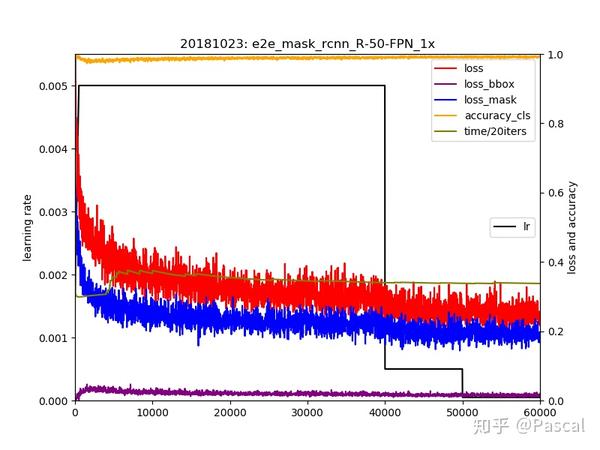

训练方法的话,可以参见这里:
6、重叠处理
训练完模型,infer得到结果提交给kaggle发现报错,应该是部分instance重叠了,这里肯定是需要处理的,简单地说就是重叠区域怎么划分,分配给哪个instance?是按面积还是信度、距离来?这里处理方法因人而异。


我的方法是这样子的,首先通过置信度降序排列候选目标,然后通过一个先【异或】后【与】的运算来解决重叠冲突,也就是(mask^bg)&mask,具体的原因大家可以自行体会一下,我就不多做解释了。
class Airbus_Submit(object):
def mask_to_rle_csv(self, img, masks,confidence):
index = np.argsort(-confidence) # index sorted by confidence: high-->low
bg = np.zeros((768,768), dtype=np.uint8) # must let dtype=uint8.Otherwise xor will be wrong
for i in index:
mask = masks[:,:,i]
if(mask is None or confidence[i]< self.thresh ): # Sometimes mask maybe None, but can't use 'mask==None', if confidence[i]<0.5 it's impossible to use
continue
mask_xor = (mask^bg)&mask
area = mask_xor.sum() # area of the mask
if(area == 0):
continue
print(confidence[i])
rle = self.rle_encode(mask_xor)
bg += mask_xor步
骤
5
和
6
写
得
少
但
工
程
量
不
小
7、Unet模型融合:解决假阳性问题
这个赛题看似是实例分割,但实际上是unet模型大行其道,排名前几的大多是unet相关的,其实主要是数据集有两个特点:
(1)图内只有一个类别的物体,不存在多类别;
(2)船只粘连不严重,重叠极少;
语义分割也就能派上用场了,一个老哥用unet-resnet34单GPU训练30epoch就12名了,让人唏嘘。
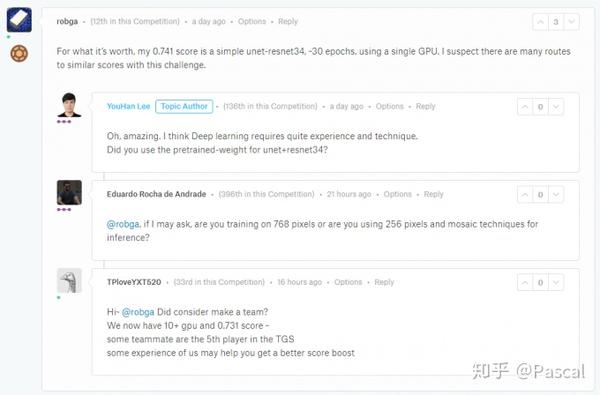

我的模型也参考了unet的结果,在detectron模型基础上融合unet结果,这一步涨分0.5个百分点。
8、TTA多模型融合
有点类似于集成学习吧,单图多scale检测投票,scale: 0.6, 0.8, 1.0, 1.2, 1.4, rotate: 90, 180, 270,都是可以尝试的,然后多模型投票取得好的结果
9、心得
(1)选择SOTA模型。kaggle比赛赛制大致上前10名金牌,前5%银牌,前10%铜牌,如果你选择一个好的baseline model,正确运行完,拿个15%是问题不大的,稍作修改拿个铜牌也不难,但是再往上提升就很难了。最艰难的时候,得分变高了,可是排名不断往下掉,心理压力挺大的;
(2)善用模型融合。这个比赛大多都是unet+maskrcnn模型融合,模型融合的策略因人而异,模型与模型之间优势互补是提分利器;
(3)善用数据扩增、TTA测试融合。
(4)相信自己本地的CV验证集。每天在kaggle的提交次数是有限的,因此要设置好离线验证集,不断探索好的参数,不要过分相信kaggle的线上得分。(备注:kaggle的线上得分和最终得分是基于不同数据集得出的,以防止部分参赛者凑结果)。数据集分配示例如下:
from sklearn.model_selection import train_test_split
#5% of data in the validation set is sufficient for model evaluation
tr_n, val_n = train_test_split(train_names, test_size=0.05, random_state=42)10、总结
虽然成绩不算特别好,但是这个过程中我还是学到了不少的东西。比赛期间恰逢我毕设开题,且这个比赛的测试数据出现了严重的数据泄露,导致分数重置等各种问题,因此参赛过程很疲惫。不管怎样能学到知识最重要。Pytorch版本的Maskrcnn已经开源了,后面准备好好研读,基于Pytorch对模型做更多改进。等kaggle大佬们开源方案了,我再继续补完分析。
11、代码开源
目前,我的代码已经在Github开源了,一个效果不错的baseline,进入TOP10%是绝对没有问题的
授权信息:
本文已授权 CVer 公众号转载(2018.11.28)
本文已授权 52CV 公众号转载(2018.12.09)


