![炒冷饭之[NeurIPS2021 Spotlight] 一种基于自监督学习的特征解耦算法IP-IRM](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
炒冷饭之[NeurIPS2021 Spotlight] 一种基于自监督学习的特征解耦算法IP-IRM

NeurIPS2021结束以来收到了一些邮件询问IP-IRM的实现细节问题,其中很多其实写在了appendix里面【我错了,但是正文实在放不下了】。所以就想趁着刚结束老头环(划掉,过完QE),统一在这里补一个我们spotlight论文 "Self-Supervised Learning Disentangled Group Representation as Feature"【审稿得分7789】中文版的偏intuitive和实际应用的补充介绍。希望能给那些读到这篇论文的小伙伴一些帮助。
具体的方法细节以及可视化等实验结果请见正文;详细的理论证明请见appendix:
1. 从工程实现角度简要来说,IP-IRM做了什么?
IP-IRM是构建在自监督(SSL)对比损失(contrastive loss)上的一种用于特征解耦的算法。其核心设计在于:在传统的对比损失的基础上,我们加入了数据分组(data partition)。某一种数据分组实质上是反映了一个特定的语义(例如,当一堆红绿数字被分成了红色和绿色两组的时候,其实这种partition就代表了颜色这一语义)。
进而当我们约束不同分组内的对比损失之间的invariance的时候,模型必须将该特定语义分离出来并且忽略掉才能达到invariance。这一过程实质是通过invariance将蕴藏在data partition背后的语义转移到模型(feature backbone)中,这样就完成了解耦 单个 语义的目标。进一步的,为了解耦出更多语义,我们固定住feature backbone,通过反向增大loss来优化寻找一个新的partition(这一partition蕴藏着新的未被解耦的语义)。由此形成一个迭代算法。
2. 补充几点容易被忽略的实现细节/trick
1) 训练流程
整个训练过程是类似一种adversarial training的方式——两个step交替进行。第一个step过程中会固定住数据分组,打开feature backbone,通过最小化loss来优化feature backbone;
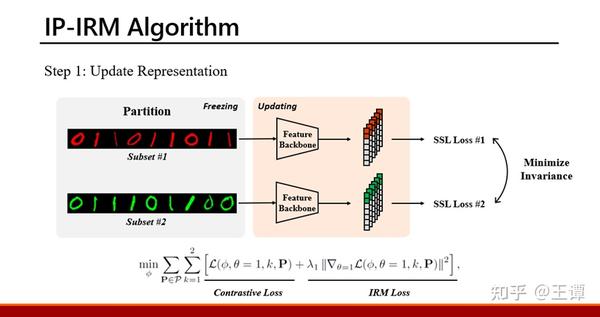

第二个step则会固定住feature backbone(因为step 2的目的是看对于现有的feature来说哪些语义仍然是entangle的)。
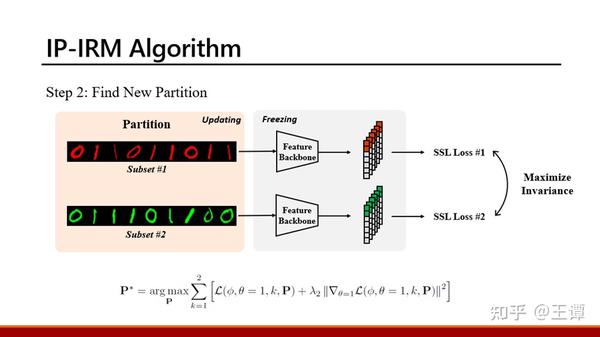

2) 如何实现step 2中对partition的更新
假设数据集里有N个样本,总共需要分成2个环境。则我们在训练初始阶段会初始化一个N*2的矩阵P用于代表每个样本属于每一个环境的概率。然后我们设计了一种soft版本的contrastive loss(详情代码实现见这里)分别计算每一个环境内部的对比损失。这里设计soft的原因在于把P直接纳入到loss的计算中。 其实也可以用gumbel softmax trick做一种hard的改进。这种设计背后其实也有一种intuitive的理解:把正样本从一群负样本中区分出来是受到负样本本身影响的(比如把一只羊从一群牛里面分出来 和 把一只羊从一堆飞机里面分出来)。
3)Partition更新(step 2)中使用offline的方式计算feature
Offline的意思是在进行step 2之前先用feature backbone过一遍数据集提取特征,然后在更新partition的时候直接使用提取好的特征作为输入即可(代码见这里)。这样做可以大大加速step 2这一过程。但是理想的情况应该是用online的方式来进行step2,因为这样可以尽可能模拟step1时候见到的真实数据。
4)Partition更新(step 2)中保持两个环境的图片大致平衡。
如果不对step 2做任何约束,学出来的partition会非常不均衡。这也非常好理解,因为contrastive loss和负样本数量非常相关,那更新partition的一种trivial解就是分给其中一个环境只有一个负样本图片,另一个则拥有剩下来的所有负样本图片。
因此在实际算法中,我们增加了一个利用entropy来控制两个环境所含图片数量大致平衡的loss(代码<a href="https://github.com/Wangt-CN/IP-IRM/blob/main/utils.py#L398">见这里)。
3. IP-IRM的缺陷(待改进的地方)
a) 虽然IP-IRM理论上可行,并且我们也给出了在toy数据集上的可视化来验证(详细分析见paper Figure 5分析)。


但是在复杂的现实数据集上就没有特别好的办法来可视化各个step的作用;以及较难判断什么时候step1/2已经完成了,可以进行下一个step了。其背后的原因在于复杂数据集的语义太丰富了,其实分出来两个组也很难通过人眼看出来背后代表的语义。
b) 在ImageNet上表现一般,我们实验过程中发现对于比较大的数据集,很难通过几次有限的迭代来实现大幅度的效果提升。一来是因为数据集越大,其背后的语义就会越多;二来是因为一次step1本身就需要几十个epoch的训练,这就导致常用的200epoch下本身可迭代的次数就不多。
4. 对于广大的research打工人来说,这篇论文能带来什么
a) 个人认为最核心的是“data partition(group)”的思想。在IP-IRM这篇论文里,数据分组其实间接定义了某一种特定的语义。例如,当一堆红绿数字被分成了红色和绿色两组的时候,其实这种partition就代表了颜色这一语义。正因此,在正文Figure 3中,我们用这种data partition的思想对传统的监督学习以及自监督学习做了一个统一(监督学习中分组对应的是不同的类别;自监督学习中分组对应的不同的图片)。那么进一步,这种分组思想也可以拓展到很多其他任务及应用中。


b) 在有了data partition的定义之后,能做的操作就更多了,比如这篇文章用到的invariance。这就引出了这两年一系列关于不变风险最小化(IRM)的文章。
c) 对真实世界的特征解耦的关注。目前对real word data的解耦仍然是非常困难的,原因是多方面的:缺少精细的图片标注,同时到底标注到多精细的层面也是一个问题;现实图片中的场景过于复杂;较难以评价等等。但是真实世界的特征解耦的前景也是非常美好的,毕竟绝大多数目前的应用都是依赖于真实图片而不是传统人造的toy数据集。
5. 其他常被问到的一些问题
a) IP-IRM和SSL方法中的基于cluster的方法(比如swav)有什么关系?总结来说就是有一定类似性但是又不完全类似。相似的地方在于,都是对数据集进行聚类or分组且每个分组内的图片具有一定的相关性。不相似的地方则是,swav这类方法是维护一组group,每个group代表了一种coarse-grained的类别,然后加上了group之间的contrastive loss。但是IP-IRM是在每个group内计算contrastive并约束group间的invariance,从这个角度来说IP-IRM更类似于一种hard negative sample挖掘的操作。
b) 所分环境的个数?这篇论文里只用了2个环境,但是和IRM类似,理论上环境数量并不会影响算法效果。但是实际使用中,环境数量会影响效果。我们发现背后原因在于环境数量越多,每个环境所分得的batch内图片就越少,进而使得负样本数量减少,最后影响contrastive效果。
6. 其他
Slides链接:
Github code:
最后附上Citation:
@article{wang2021self,
title={Self-Supervised Learning Disentangled Group Representation as Feature},
author={Wang, Tan and Yue, Zhongqi and Huang, Jianqiang and Sun, Qianru and Zhang, Hanwang},
journal={Advances in Neural Information Processing Systems},
volume={34},
year={2021}
}