也谈激活函数Sigmoid,Tanh,ReLu,softplus,softmax

先看一下wikipedia列出来的这些函数[1]


所谓激活函数,就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。常见的激活函数包括上面列出的Sigmoid、tanh、ReLu、 softplus以及softmax函数。
这些函数有一个共同的特点那就是他们都是非线性的函数。那么我们为什么要在神经网络中引入非线性的激活函数呢?知乎上有一段很有意思的话[2]:
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。 正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
举个输入 x1, x2 的简单例子来说,如果没有激活函数,那么无论中间有多少层节点,输出总可以写成 x1,x2 的线性表达式: y=a*x1+b*x2 ,这样的网络当然作用有限。所以,引入激活函数就是为了引入非线性因素,以此解决线性模型所不能解决的问题,让神经网络功能更强大。
下面我们分别来看一下上述各个激活函数(这里摘抄了不少来自网络的说法,觉得比较有理的部分就留下来,具体可以参考后面的链接)。
Sigmoid函数
Sigmoid函数是传统神经网络中最常用的激活函数,一度被视为神经网络的核心所在。从数学上来看,Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果。 从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
tanh函数
TanHyperbolic(tanh)函数又称作双曲正切函数,其函数曲线与Sigmoid函数非常相似, 可以通过缩放平移相互变换,
f(x)=\frac{1}{1+e^{-x}}=\frac{e^{x}}{e^{x}+1}=\frac{1}{2}+\frac{1}{2} \tanh(\frac{x}{2})
不过tanh另外有两个好处,均值是0,且在原点附近更接近 y=x (identity function)的形式。均值不为0就意味着自带了一个bias,在计算时是额外的负担,这会使得收敛变得更慢[4];更接近 y=x 意味着在几何变换运算中更具有优势,比如在激活值较低时(也可以通过变换把结果normalized到[-1,1]之间,tanh在 [-1, 1]的范围内tanh和 y=x 非常非常接近),可以利用indentity function的某些性质,直接进行矩阵运算[5]-[6]。所以tanh在具体应用中比Sigmoid函数更具有优越性,训练相对容易[3]。
缺点就是,函数tanh(蓝色)和函数sigmoid(橙色)一样,在其饱和区的接近于0,都容易产生后续梯度消失、计算量大的问题。
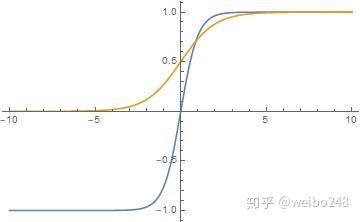
ReLU函数和softplus函数
ReLu函数的全称为Rectified Linear Units。
softplus可以看作是ReLu的平滑。根据神经科学家的相关研究,softplus和ReLu与脑神经元激活频率函数有神似的地方。也就 是说,相比于早期的激活函数,softplus和ReLU更加接近脑神经元的激活模型,而神经网络正是基于脑神经科学发展而来。
那么softplus和ReLU相比于Sigmoid的优点在哪里呢?继续采用知乎上的话,
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用 Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
第一点很好理解,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。而且有大量的研究表明,ReLU在大型网络的训练中会更快地收敛。
第二点是关键的,sigmoid 最致命的缺点,就是当输入非常大或者非常小的时候出现饱和(saturation),从上图中也可以明显看出,这时神经元的梯度接近于0。所以,使用sigmoid尤其注意参数的初始值,如果初始值很大的话,大部分神经元可能都会处在saturation的状态而把根本就没有gradient,这样的网络无疑是很难学习的。这些比较大的值如果出现在网络中间,效果相同。
相反,使用 ReLU不会出现梯度消失的问题,因为其梯度为1,当然同样也不会有梯度爆炸的问题。这也是为什么使用ReLU得到的SGD的收敛速度会比 sigmoid/tanh 快得多。
顺便说一下概念,梯度爆炸:当梯度g>1且计算次数n比较大时, g^n 有可能会变得非常大;梯度消失:当g<1且计算次数n比较大时,g^n有可能非常小,基本相当于为0。
第三点作为优点是有争议的,如果考虑稀疏性,dropout早就实现了(这里顺便提一下,自从有了ReLU+BatchNormalization, dropout的使用频率就低多了,当然也有dropout+BN一起用的,只是这种情况比较少);相反地,第三点也可以算是ReLU的弱点,因为这样容易造成神经元无效(dying relu), 当x<0时所有的值都为0了,也就是,所有越过0的那些点在以后层再也不会被激活了,0的梯度永远是0,在不少的论文中,也明确表明ReLU阻止了信息从浅层流向深层流动,如[CVPR-201808.08718 Wide Activation for Efficient and Accurate Image Super-Resolution]。可能也正是为了克服这些弱点,才会出现leaky ReLU和PReLU这样的函数,关于这两个函数,只要看一眼其表达式就不难明白!
softmax函数(也称归一化指数函数)
可以看到,Sigmoid函数实际上就是把数据映射到一个(0,1)的空间上,也就是说,Sigmoid函数如果用来分类的话,只能进行二 分类,而这里的softmax函数可以看做是Sigmoid函数的一般化,可以进行多分类。
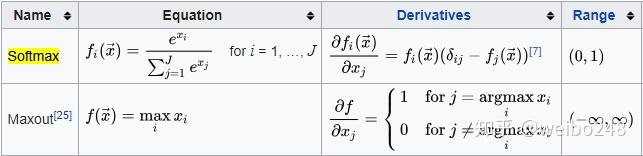
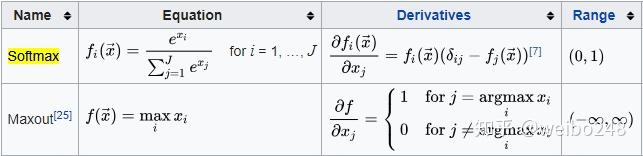
从softmax公式中可以看出,就是如果某一个xi大过其他xj,那这个映射的分量就逼近于1,其他就逼近于0,即用于多分类。也可以理解为将J维向量映射为另外一种J维向量(嗯,这让我想起one-hot矩阵)。
参考资料
[1] https://en.wikipedia.org/wiki/Activation_function
[2] https://www.zhihu.com/question/29021768
[3] https://www.zhihu.com/question/50396271?from=profile_question_card
[4] http://yann.lecun.com/exdb/publis/pdf/lecun-98b.pdf
[5] https://en.wikipedia.org/wiki/Identity_function
[6] https://dinh-hung-tu.github.io/logistic-sigmoid-tanh/
[7] https://github.com/Kulbear/deep-learning-nano-foundation/wiki/ReLU-and-Softmax-Activation-Functions
