
精读深度学习论文(32) DSSD & DSOD

人间有味是清欢
0. 前言
- 以下两篇论文都是 SSD 的改良版,简单学习一下。
- DSSD 相关资料:
- DSSD,其实就是 Deconvolutional Single Shot Detector 的缩写,本论文的其中一位一作 Wei Liu 就是SSD的一作。
- DSSD: Deconvolutional Single Shot Detector - 原文
- 知乎文章:DSSD:Deconvolutional Single Shot Detector 解析与实践:推荐。
- DSOD 相关:
- DSOD: Learning Deeply Supervised Object Detectors from Scratch - 原文
- 对于模型,不理解就看源码,轻松+愉快(当然,前提是理解SSD与DenseNet)。
- 作者本人PPT演讲
- 官方代码,非官方TF源码
1. DSSD
1.1. 素质四连
- 要解决什么问题?
- SSD 的原始版本使用的基础网络是VGG,比较古老。
- SSD 对小目标性能不够好,分析原因后,认为是在预测过程中,没有充分利用上下文信息。
- 插一句,“没有充分利用上下文信息”这句话比较玄学,个人理解是,使用浅层特征图进行预测的效果不好,使用深层特征图效果较好(至于为什么深层好,可能跟视野域有关,感觉比较玄学……)
- 用了什么方法解决?
- 使用 Ressidual-101 替代 VGG。
- 对原有的 SSD 模型进行改进(改进预测模块、增加转置卷积模块)。
- 效果如何?
- 当时在 COCO 和 VOC2007 上个数据集上,性能都达到最优。
- 还存在什么问题?
- SSD 等 one-stage 算法的优势在于速度,但该模型在已经达不到实时要求(根据论文结果,该算法精度比 Faster R-CNN 高,但FPS低于Faster R-CNN)。
1.2. 模型总体结构
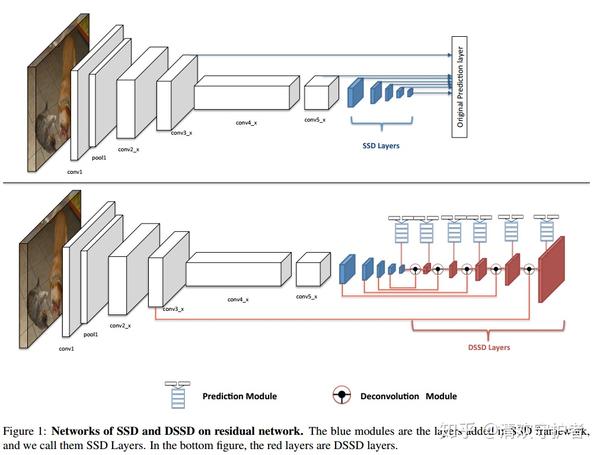
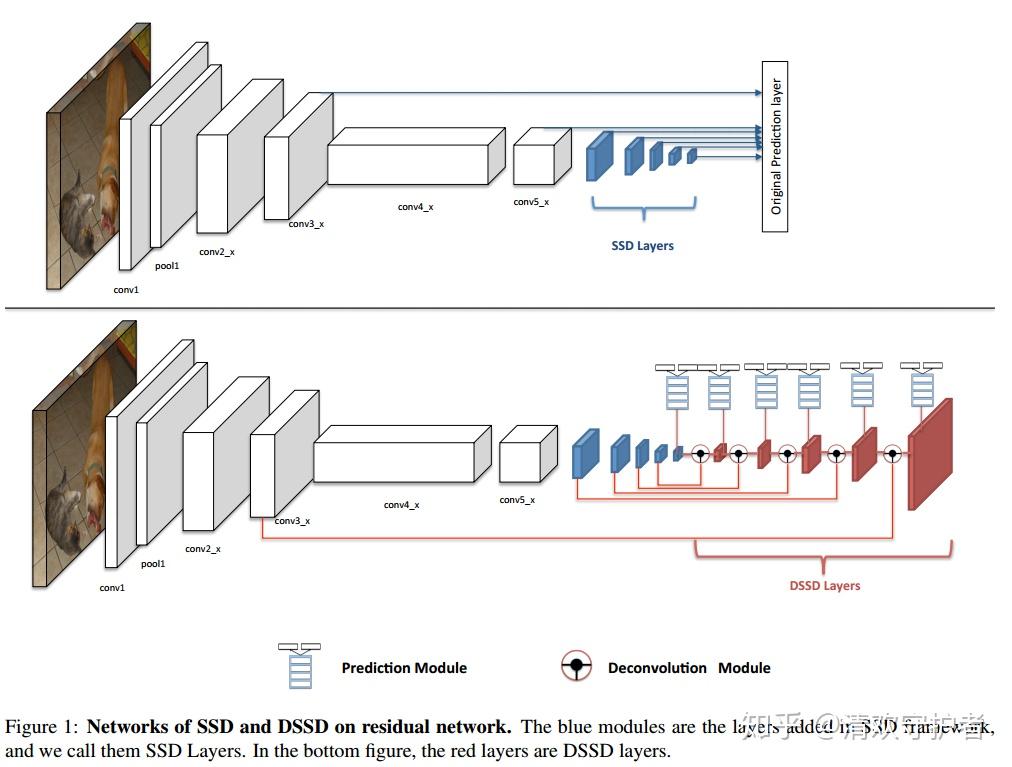
- 配图总体介绍:上方模型是原始 SSD 结构,下方模型是 DSSD 结构。
- DSSD 与 SSD 的不同之处:
- DSSD 在 SSD 后添加了 Deconvolutional Module。
- DSSD 的预测模块 prediction module 的输入与结构都与 SSD 不同。
1.3. 模型实现细节
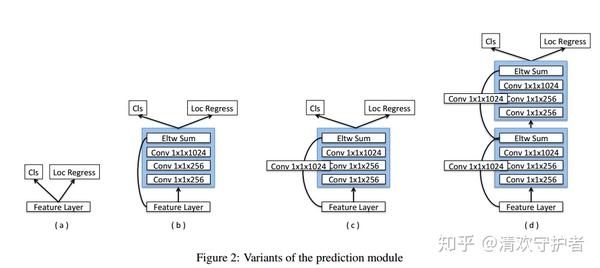
- 预测模块(Prediction Module):
- 为什么需要改变预测模块:如果直接将VGG修改为ResNet-101,并直接使用SSD的结构,那么该模型结果还不如原始模型。
- 下图中罗列了集中预测模块的实现,其中 (a) 为原始 SSD 使用的模块,效果最好的是 (c)。
- 没有为什么……实验结果……

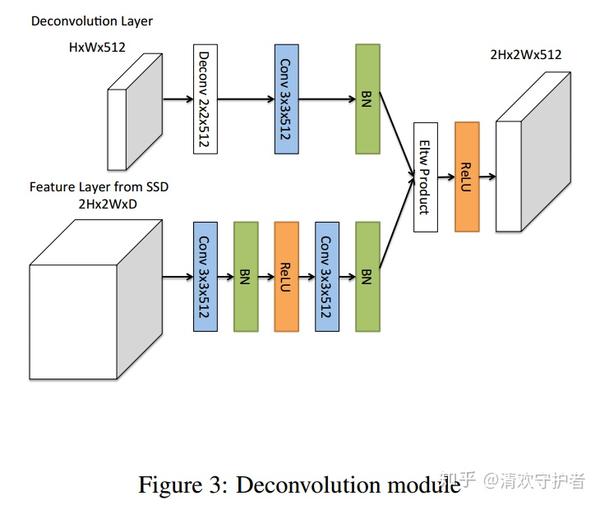
- 转置卷积模块(Deconvolution Module):
- 为什么需要新增转置卷积模块:为了综合获取之前特征图以及转置卷积层的信息(integrating information from earlier feature maps and deconvolution layers)。
- 下图为具体模型实现,注意,使用的是Element-wise product。

1.4. 其他
卷积神经网络在结构上存在固有的问题:高层网络感受野比较大,语义信息表征能力强,但是分辨率低,几何细节信息表征能力弱。低层网络感受野比较小,几何细节信息表征能力强,虽然分辨率高,但语义信息表征能力弱。SSD采用多尺度的特征图来预测物体,使用具有较大感受野的高层特征信息预测大物体,具有较小感受野的低层特征信息预测小物体。这样就带来一个问题:使用的低层网络的特征信息预测小物体时,由于缺乏高层语义特征,导致SSD对于小物体的检测效果较差。而解决这个问题的思路就是对高层语意信息和低层细节信息进行融合。
- 训练细节:
- 对 anchors 的尺寸选择进行了一些事前处理,使用聚类算则合适的bbox比例。
- 训练分为两个阶段:1)加载SSD的预训练模型,冻结参数,只训练deconvolution层。2)训练所有层。
2. DSOD
2.1. 素质四连
- 要解决什么问题?
- 之前大部分模型都使用了迁移学习,或者说,使用了其他任务(如ImageNet的图像分类任务)的预训练模型(pre-trained model),如何能够不使用 pre-trained model 训练模型?
- 用了什么方法解决?
- 将DenseNet的思想与SSD结合,提出了DSOD结构。
- 提出了不使用pre-trained model训练的几条准则。
- 效果如何?
- 在COCO, VOC数据集上性能达到最优,同时效率能够达到实时性要求。
- 还存在什么问题?
- 在这篇文章中提高,DSOD的两个问题:
- 特征金字塔中,各层相互之间没有联系。
- 当前最优的方法中的每层金字塔贡献出的监督信息是固定的。
- 当然,由于模型复杂一些,模型速度上比SSD有所下降。
2.2. pre-trained model 相关介绍
- 之前大多数物体检测模型的做法:
- 使用ImageNet上训练好的图像分类模型进行fine-tune,获得物体检测模型。
- pre-trained model 的优势:
- 模型收敛速度更快,训练更容易。
- 使用上述方法存在的缺陷:
- Limited structure design space:物体检测模型必须使用 pre-trained model 相同的模型结构,即模型灵活性差、难以改变模型网络结构。
- Learning bias:物体检测任务与图像分类任务的目标函数、标签结构都不相同,因此图像分类任务的模型不一定能完美套用于物体检测任务。
- Domain mismatch:对于不同领域的图片效果不佳,比如医学图像、深度图。
2.3. 模型设计准则
- Proposal-free:经过实验发现,从零开始训练时,有候选区的物体检测模型(R-CNN系)不容易收敛,而没没有候选区域的模型(SSD、Yolo)能够收敛。
- Deep Supervision:主要是借鉴DenseNet的思想,避免梯度消失。
- Stem Block:借鉴Inception v3 & v4 的设计,减少输入图片信息的丢失,从模型角度就是在模型的最开始添加一个conv+pool的结构。后续试验结果表明,该模块提高了模型性能。
- Dense Prediction Structure:减少了模型的参数量,特征包含更多信息。实现方式就是,用于预测bbox等信息的特征图中,有一般是通过上层特征图经过pooling+conv获取的,另一半是SSD原始结构中获取的,具体的参考其结构图,重点关注所有Concat相关结构。
2.4. 模型结构
- SSD与DSOD的对比图如下:
- 左边是原始SSD结构,右边是改良后的DSOD结构。
- SSD中,最后5个特征图都是直接从上一特征图通过卷积操作获得;DSOD中最后五个特征图,是由两路特征图拼接获得。
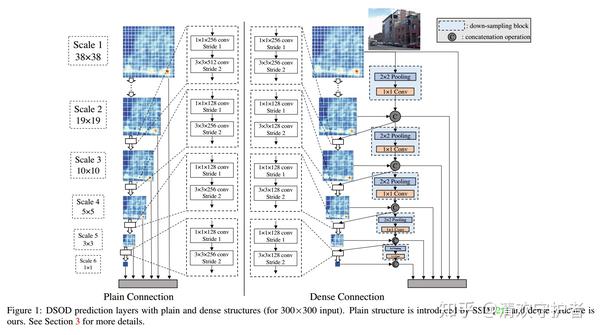
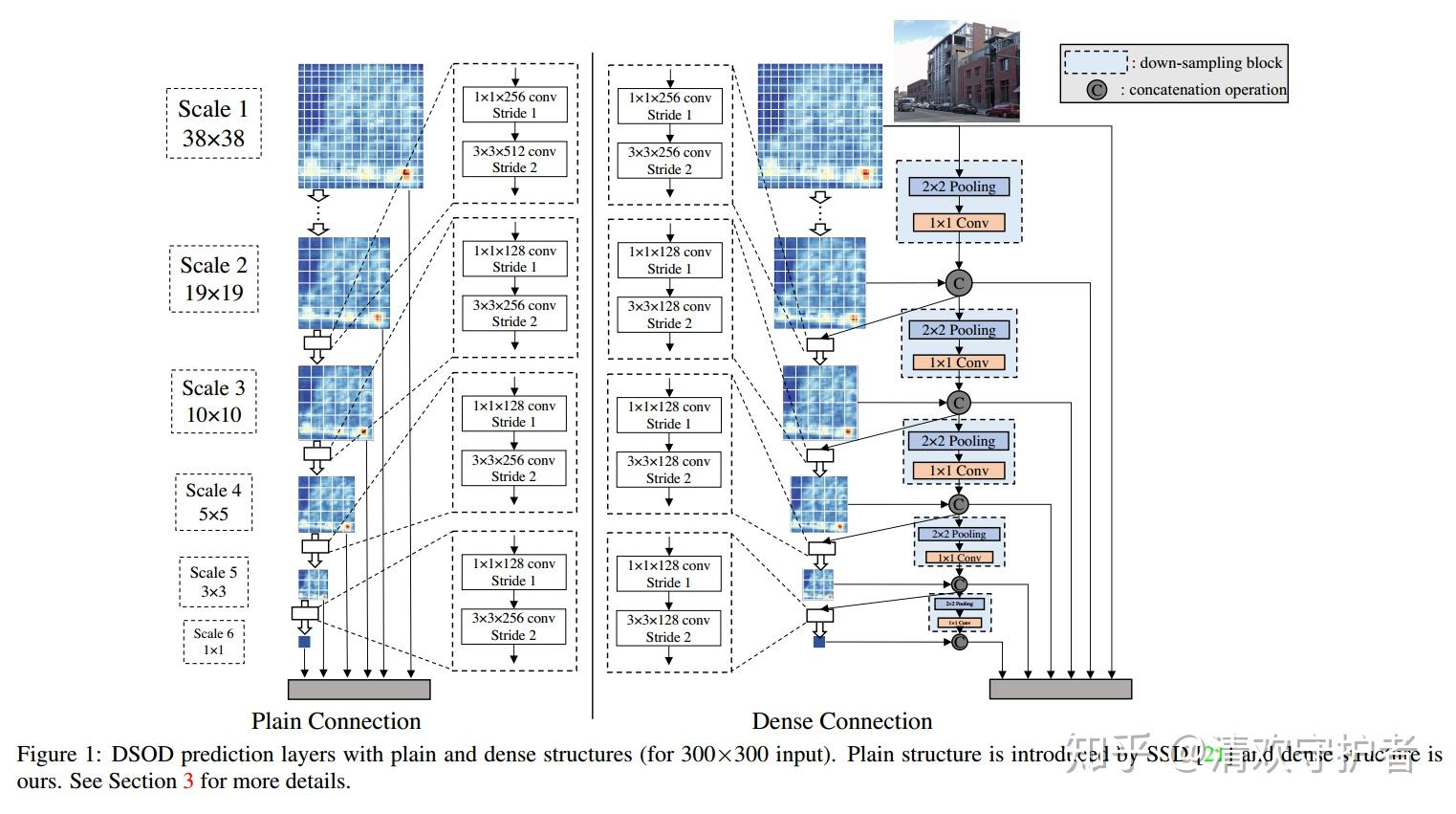
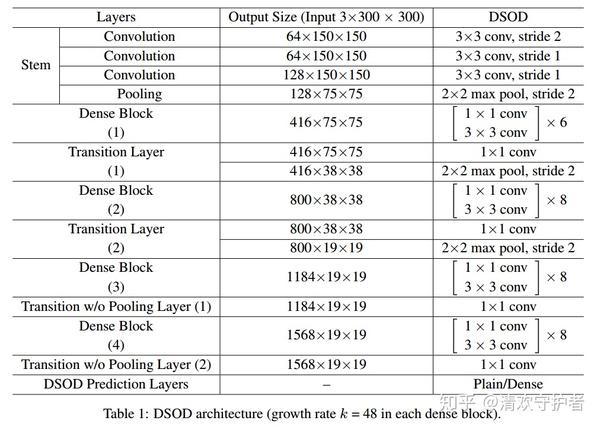
- DSOD的前半部分结构如下表所示:
- 表中不包含 Dense Prediction Structure,即上图中的结构。
- 表中最上方就是Stem Block结构。

2.5. 其他
- 训练细节大都与SSD相同。
- 更好模型与更多数据的讨论:
- 在算力充足的情况下,更多数据肯定能够提高性能。
- 一个更好的模型能,能够在数据量少的情况下,与较差模型达到相同的精度(甚至更高精度)。
发布于 2018-11-08 15:43
