强化学习中的并行(parallel)、异步(asynchronous)与分布式(distribute)

很多强化学习的论文中并没有详细介绍算法训练的串行并行和同步异步的概念,在此做一个粗略的总结,希望和读者们交流探讨。
RL和监督学习有一个明显的区别,就是RL存在一个与环境交互收集数据的过程(不考虑offlineRL),这就意味着在训练之前需要model和环境交互来收集数据,收集完数据后model的训练又需要一次前向计算+反向传播,这就比监督学习多执行了一个环节。在实现时,通常设置actor模块负责收集数据,learner负责计算梯度,更新网络的过程由update完成,这三者如何协调运作就是串并行和异步同步的关键。
1.RL中的串行并行(parallel)与同步异步(asynchronous)
因为RL中存在actor和learner,所以RL中的串行很显然指的是actor-->learner-->update....这种交替执行的过程,即依次执行动作得到奖励,直到样本数足够训练,然后执行梯度下降并更新网络。
而并行在RL中的情况较多,大致可以分成3种:
(1)actor并行,只有一个learner(同步update)
(2)actor-learner并行(异步update)
(3)actor-learner并行,数据并行分布式训练(同步异步都支持)
同步异步是对并行情况进行区分的,且通常指的是模型参数更新过程中的同步异步。模型同步更新指的是当设立多个并行actor或者learner时,model是进行同步更新的,且多个actor和learner进程中的模型在每一时刻都保持一致;而异步指的是每个learner计算出梯度后都可以对全局模型进行异步更新,且多个actor和learner进程中的模型在每一时刻并不一定相同。
下文会对每一种情况分别介绍。
2、串行训练(一个actor、一个learner)
不论是DQN、PG、AC、PPO以及其他算法在论文中都没有详细阐述其环境跟模型的部署,很多都需要从代码中学习。通常RL论文在介绍算法时都会给人一种感觉,就是默认只有一个环境,而环境中也只有一个待训练model(不包括multi-agent RL)。这种情况下对应的就是串行计算流程,单个agent在环境中串行执行逻辑,然后收集足够的样本后进行训练。但是由于data efficiency以及数据temporal dependency的问题,如果你实际训练中只部署一个环境而且只利用一个actor收集的数据进行训练的话往往取得不了很好的效果,这时就需要各种训练的trick来帮助模型学习的更好。
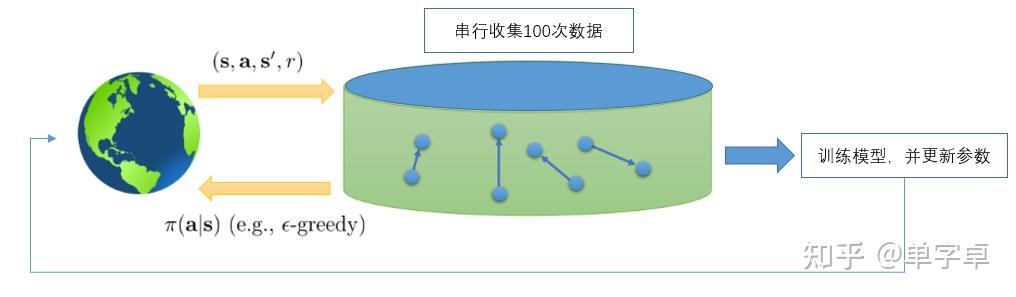

显然这种情况下最严重的问题就是数据的temporal dependency,DQN解决这个问题的方法是设置了一个replay buffer(因为DQN是off-policy的)。最原始的DQN算法同样只有一个环境和一个agent,但是在内存中开辟了存储之前数据的空间,这样在下一次训练中只需要在这个buffer中随机采样一批样本即可完成训练,既打破了时序间的依赖,又避免了网络产生局部过拟合现象(当前样本训练的很好但是遗忘了之前的样本分布)。同样DQN的后续算法、DDPG、以及单机模式的SAC算法也有相同的replay buffer设置。
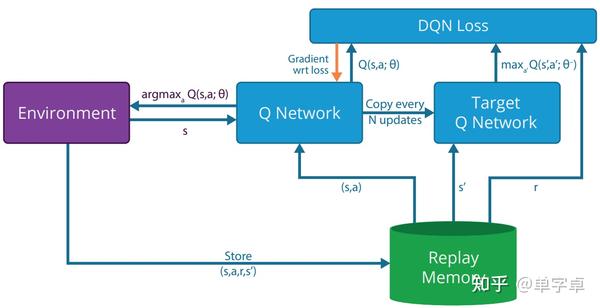

这样的配置显然适合小规模任务,即所需数据量较小,任务简单的场景,这时可以很好地实现强化学习算法的性能。但是当遇到大规模问题(multi-task)以及样本效率较低的算法(PPO等on-policy算法本身就不适合使用relay buffer)这种配置就会使得训练时间过长而且最终的效果也较为一般。
3、并行(parallel)环境(并行actor、一个learner、一个model)
对于PPO等onpolicy算法replay buffer不再适用,因此考虑设置并行化环境,然后在并行化环境中采集数据同步训练模型,最典型的环境配置就是baseline中的subproc_VecEnv,利用多个子进程来开启并行环境,进程间使用Pipe通信,然后由同一个model进行决策,得到足够的数据后同步对model进行训练,因此也只有一个learner。其具体效果如下图,在4个并行环境中分别执行动作采集数据,当到达一定数量时更新模型参数,再继续采集数据。因为设置了并行环境且样本分批随机采样进行训练,这就使得onpolicy算法的temporal dependency的问题得到了解决。
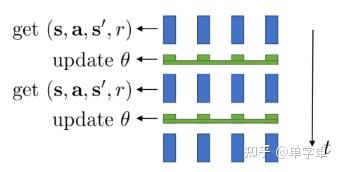
可见,每个进程中采样的actor都是利用了同一个模型,且模型参数同步更新。
4、并行(parallel)环境(并行actor-learner、一个model)
这种情况就是A3C文章中所设置的异步训练情况。具体实现时,在torch.multiprocess中设置多进程来异步采集数据并训练,利用share_model共享一个全局模型,然后在每个进程中设置一个采样actor和计算梯度的learner,在得到梯度信息之后异步对全局模型更新,然后其它进程在每个循环中同步全局模型,其简易代码如下。
if __name__ == '__main__':
env = create_atari_env(args.env_name)
#多进程间共享模型
shared_model = ActorCritic(
env.observation_space.shape[0], env.action_space)
shared_model.share_memory()
#也可以配置只有一个全局leaner
if args.no_shared:
optimizer = None
else:
optimizer = my_optim.SharedAdam(shared_model.parameters(), lr=args.lr)
optimizer.share_memory()
processes = []
#全局步数
counter = mp.Value('i', 0)
lock = mp.Lock()
p = mp.Process(target=test, args=(args.num_processes, args, shared_model, counter))
p.start()
processes.append(p)
for rank in range(0, args.num_processes):
p = mp.Process(target=train, args=(rank, args, shared_model, counter, lock, optimizer))
p.start()
processes.append(p)
for p in processes:
p.join()
def train(rank, args, shared_model, counter, lock, optimizer=None):
env = create_atari_env(args.env_name)
##初始化actor
model = ActorCritic(env.observation_space.shape[0], env.action_space)
if optimizer is None:
optimizer = optim.Adam(shared_model.parameters(), lr=args.lr)
model.train()
state = env.reset()
state = torch.from_numpy(state)
done = True
episode_length = 0
while True:
#每次循环进行全局模型同步
# Sync with the shared model
model.load_state_dict(shared_model.state_dict())
if done:
cx = torch.zeros(1, 256)
hx = torch.zeros(1, 256)
else:
cx = cx.detach()
hx = hx.detach()
values = []
log_probs = []
rewards = []
entropies = []
for step in range(args.num_steps):
episode_length += 1
value, logit, (hx, cx) = model((state.unsqueeze(0),
(hx, cx)))
prob = F.softmax(logit, dim=-1)
log_prob = F.log_softmax(logit, dim=-1)
entropy = -(log_prob * prob).sum(1, keepdim=True)
entropies.append(entropy)
action = prob.multinomial(num_samples=1).detach()
log_prob = log_prob.gather(1, action)
state, reward, done, _ = env.step(action.numpy())
done = done or episode_length >= args.max_episode_length
reward = max(min(reward, 1), -1)
with lock:
counter.value += 1
if done:
episode_length = 0
state = env.reset()
state = torch.from_numpy(state)
values.append(value)
log_probs.append(log_prob)
rewards.append(reward)
if done:
break
R = torch.zeros(1, 1)
if not done:
value, _, _ = model((state.unsqueeze(0), (hx, cx)))
R = value.detach()
values.append(R)
policy_loss = 0
value_loss = 0
gae = torch.zeros(1, 1)
for i in reversed(range(len(rewards))):
R = args.gamma * R + rewards[i]
advantage = R - values[i]
value_loss = value_loss + 0.5 * advantage.pow(2)
# Generalized Advantage Estimation
delta_t = rewards[i] + args.gamma * \
values[i + 1] - values[i]
gae = gae * args.gamma * args.gae_lambda + delta_t
policy_loss = policy_loss - \
log_probs[i] * gae.detach() - args.entropy_coef * entropies[i]
optimizer.zero_grad()
(policy_loss + args.value_loss_coef * value_loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
#梯度异步更新
ensure_shared_grads(model, shared_model)
optimizer.step()异步更新的示意图如下,3个进程中都有各自的actor-learner,然后对同一个全局model进行异步参数更新。

可见,每个进程中采样的actor都各自保存了一个模型(每一时刻并不一定相同),但是在循环开始阶段会同步全局模型参数,并且对于全局模型的参数是异步更新的。当然这种情况也可以同步更新模型,但是效率会变低,通常来讲异步更新速度更快,但是训练效果不如3中的并行同步更新,因为异步的梯度更新导致了模型收敛并不稳定。
5、分布式并行数据训练
上述3种情况通常都是在单机情况下利用多进程实现的,在小规模任务上可以很好地实现算法性能,但是对于大规模任务需要很长时间来训练,因此必须采用分布式计算资源来加快训练解决data efficiency的问题,本文重点介绍数据并行,不涉及模型并行。
Massively Parallel Methods for Deep Reinforcement Learning中验证了大规模分布式计算可以有效提高强化学习算法的性能,且大大缩短训练时间,其设计的分布式DQN 系统如下图。
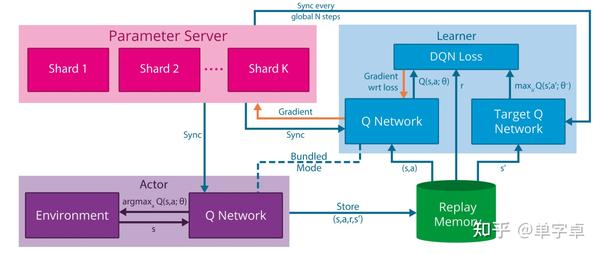
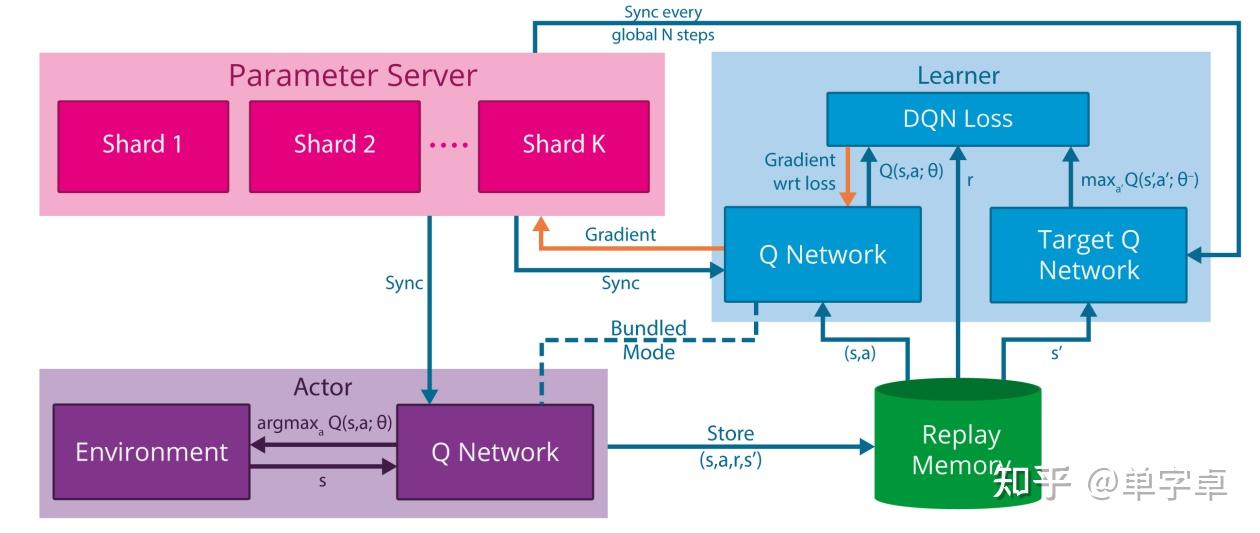
这个系统设计是仿照了DistBelief分布式计算形式,利用ps-worker的工作模式进行异步梯度更新,和4中的更新模式相似,由一个参数服务器(parameter server)统一保存全局参数并接受来自每个机器(replica)的梯度信息来异步更新全局模型,而每个机器都保存了一份自己的模型信息且通常与其他机器并不相同(异步更新导致),但每个机器都设置了定期同步全局模型的操作,这样就可以将大批量数据进行分布式训练,同时每个分布式机器中都有一个独立的进程执行actor的采样过程且有独立的replay buffer进行经验回放供learner进行梯度计算。在异步梯度更新时,还设置了保护机制,保证梯度更新的稳定性。更新间隔太久的梯度信息直接舍弃,如果当前梯度信息大于历史平均值+-方差的n倍范围也会直接舍弃。
这种actor-leaner的设计就是分布式RL算法的核心,包括之后的IMPALA等分布式算法都是仿照A3C和gorilla的形式设计actor和learner以及全局模型的更新和communication形式,使得分布式系统的吞吐量进一步提升。
Why Parallelism? An Example from Deep Reinforcement Learning
How to Train Really Large Models on Many GPUs?
PyTorch Distributed Evaluation
https://www.quora.com/What-is-synchronized-gradient-descent
