
word2vec原理解析及简单实践

前些日子,google提出的BERT可以说是nlp届新的里程碑,而Tomas Mikolov等人2013年提出的word2vec[1][2]可以说是当年的里程碑。
word2vec在nlp领域有非常广泛的应用,要想用好word2vec,最好要弄明白其中的原理,经过我这几天的研究,对word2vec有一点粗浅的理解,试图通过本篇对word2vec原理进行一个较为清楚的解析,同时有使用gensim的简单实践。
本文内容是基于网络上的资源,加上自己的理解,有错误在所难免,希望大家不吝赐教。
一、 词的表示简述
在现实应用中,文本或词的表示是非常重要的。最常用的文本表示技术有:
- Local representations
- N-grams
- Bag-of-words
- 1-of-N coding
- Continuous representions
- Latent Semantic Analysis
- Latent Dirichlet Allocation
- Distributed Representations
第一类是Local representations(局部表示)。其中,N-grams就是将文章序列通过大小为N的窗口,切割成一个个的group,然后依据这些group去做统计,得到一些文本的统计特征来作为文本的表示。 Bag-of-words,词袋模型,就是词的统计来得到词的特征,最简单的,统计个数。 1-of-N coding,就是独热(one hot)编码,来表示一个词。第二类是Continuous representations(连续表示)。方法有三种,前两种笔者也不熟悉,第三种叫做Distributed Representations(分布式表示)。word2vec就属于这一类里。
第一类的确是不错的方法,但是缺点也很明显,主要表现在几点。
- 词的意义问题。 通过词的表示,很难得知同义词之间的关系,也很难计算词之间的相似度。
- 对新词不友好。 如果出现新词,几乎不可能更新到最新的词表。
- 主观,需要人力去创造和适应。 这些特征基本上是依据人类对语言的理解去做的,从这个件角度而言,相当于加入了很多的先验知识,这就会使得表征的信息有局限性。
- 空间稀疏性。 one hot编码中,一个词的表示,除了一个1,其他都是0。人类的词汇量很大,在说话的常用词有20k个,大词汇量表有500k个,google的词汇表有13m个,过于稀疏,对于后面的存储和计算都不太友好。
简单的想法就是Continuous representions中的Distributed Representations,多位研究人员为此做出过努力和贡献,值得关注的是Bengio的2003年的paper——A neural probabilistic language model。 Distributed Representations可以基于语言模型从不同的神经网络模型中获得,有Feedforward neural net language model(前馈神经网络语言模型)和Recurrent neural net language model(循环神经网络语言模型),他们二者都是神经网络语言模型,可以简写为NNLM。
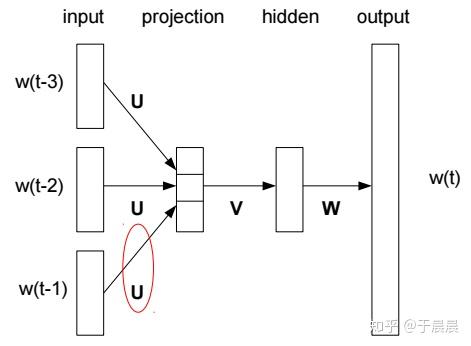
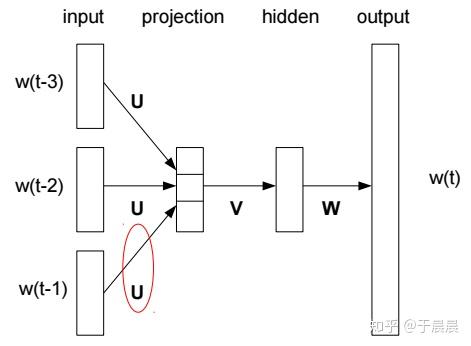
上图就是Bengio的Four-gram neural net language model架构。该模型通过随机梯度下降(SGD)和误差反向传播算法(BP)进行训练。其中,词的向量存在矩阵U中。从理解上来讲,该网络是一个神经网络,有输入,有输出。但是这是训练另一个虚假任务,因为该神经网络最终要的结果并不是去预测,而是训练后的中间产物,U矩阵。该网络的问题在于,训练的时候太消耗资源,而且,V和W等并不是想要的,却浪费了很多资源,使得数据集太大的时候,训练时长特别长,同时,获得词向量并不是非常有效。到2013年的时候,word2vec出世,word2vec的主要工作在于简化了此模型,使得大量的数据(b级别)可以在上面运行,并做了一些创新。下面将介绍word2vec。
二、 word2vec原理解析
2.1 word2vec总览
上文提到,NNLM的问题在于,训练并不有效和高效。Mikolov等人提出了以下解决方法:
- 输出层的softmax函数可以由以下方法替代:
- Hierarchical softmax (Morin and Bengio)
- Hinge loss (Collobert and Weston)
- Noise contrastive estimation (Mnih et al.)
- Negative sampling (Mikolov et al.)
- 移除了隐藏层,对于较大的模型,可以加速训练1000倍以上,同时提出了以下两种训练方法
- Continuous bag-of-words model(简称CBOW模型)
- Continuous skip-gram model(简称SG模型)
简单而言,word2vec的核心思想就是预测每个单词与其上下文单词之间的关系。
共两种算法:
- Skip-grams(SG):给定单词,去预测此词的上下文单词(位置独立)。
- Continuous Bag of Words(CBOW):从给定的上下文单词,去预测该单词。
两种(适度有效的)训练方法:
- Hierarchical softmax
- Negative sampling
下文以skip-grams算法,连接原始的softmax为例子介绍word2vec。
2.2 Skip-grams(SG)算法解析
正如前文所说,通过神经网络的方法获得词向量,其实是建立一个(虚假)任务,最终通过训练模型,我们只需要保留模型中的一部分权重参数,来获得词向量。在Skip-grams这里,要训练的任务就是给定单词,去预测该词前面m个窗口和后面m个窗口的词。如图2所示,就是说,该网络的输入是单词,目标输出是2*m个单词。 图2中,输入就是banking,这里称之为center word(中心词),turning,into,crises,as等单词叫做output context words(输出上下文单词)。


针对每个单词t=1,2,…,T,预测该单词周围“半径”为m的窗口里的单词,也就是针对每个单词,预测的目标是该单词前面m个单词及后面m个单词。所以,我们得到该训练任务的目标函数:给定当前中心词,最大化上下文单词的概率。目标函数如图3,其中,此处wtwt是表示t时刻的中心词, θθ代表我们将会优化的变量,对应于平常我们所说的权重。 我们的目标J′(θ)J′(θ)就是要在最大化每一个中心词周围的词的概率。下面的J(θ)J(θ)是对J′(θ)J′(θ)取了负号和对数。之所以这样,是因为在机器学习里,我们通常习惯于去优化最小值。J(θ)J(θ)被称之为目标函数。所以,此处我们目标就是去最小化目标函数J(θ)J(θ)。(注:在机器学习领域,目标函数等价于损失函数,也等价于代价函数)。对于目标函数的理解,也可以理解为交叉熵损失。写出交叉熵的公式,再对比,就可以明白了。


从上图3,我们可以得知,目标函数中最核心的还是概率p(wt+j|wt)p(wt+j|wt),既然如此重要,怎么计算呢?最简单的公式就是如下图4。
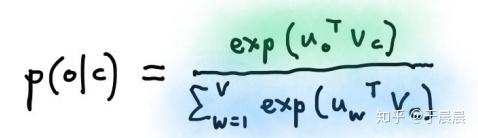

上图中,o表示输出(outside or output)单词对应的单词索引,c表示中心(center)单词索引。vcvc和uouo分别是索引为c和o的“中心”(center)和“外面”(outside)的向量。此处可能并不是太好理解,可以等看了后面,再思考这个,就很容易理解了。在此处可以做一些简单的理解,uouo和vcvc都是列向量,这没问题。然后o和c都是索引,也没问题。分母中累加的个数V是单词总个数,也就是数据集中所有不同单词的个数。其实,vcvc是索引为c的单词对应的词向量。如果为wtwt,vcvc也就变成了vtvt了。剩余的可以等后面再去理解。
softmax函数,就是使用单词c(单词索引为c的意思)去获得输出单词o的概率分布。 怎么获取概率,就是下图5和图6要讲的问题。图5就是讲点乘的计算方法,这个大家都熟悉。前文也提到u和v都是列向量,两者点乘的结果是一个实数,二者越相似,该实数越大。 于是,当w分别为1,2,…V时,uTwvuwTv就可以得出每个单词与v的相似程度了。(注:图中是w=1…W,笔者认为W应该改为V,属于图中错误)


笔者之前一直不太理解,为何sotfmax为何要这么写,看了图6就完全明白了。这么理解,给定一个数字分布,要将其中的每个数字都映射为概率,要求是每个数字越大,你要映射的概率越大。概率是什么,0到1之间的数字。所以这个数字必须先转换为正数,怎么转换呢?图中u是一个列向量,uiui是表示列向量的第i个数字,是个实数,ujuj同理,也是实数。图6就是很简单将该数字做了映射,也就是uiui映射为euieui,选择指数函数,因为首先它是递增的,同时指数函数都是大于等于0的。同时除以分母,就完成了归一化。这也是softmax之所以长这个样子的原因。


图6:Skip-gram,sotfmax是一个将实数分布映射为概率的标准操作
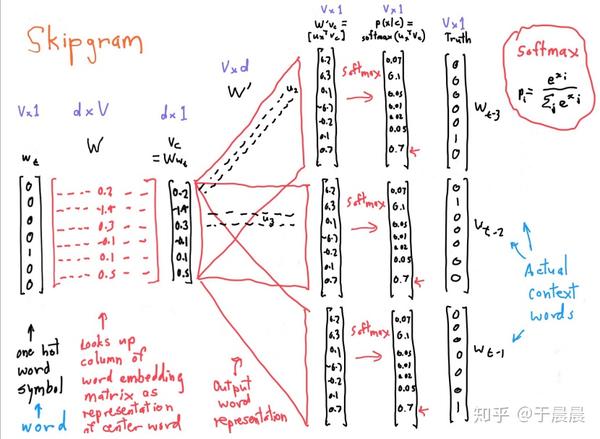
前文讲了那么多,一直没有讲到skip-grams的框架,下图7就是框架,该图非常简单明了。该图采用的是skip-gram框架,后面结了softmax层,并没有使用Hierarchical softmax或Negative sampling主要是为了方便理解。值得注意的是在word2vec的框架里,没有激活函数,也就是没有sigmoid,tanh等。输入为wtwt,输出是窗口半径为m的单词,也就是输出为wt−m,wt−m+1…,wt−1,wt+1,…,wt+m−1,wt+mwt−m,wt−m+1…,wt−1,wt+1,…,wt+m−1,wt+m,图中只画了wt−1,wt−2,wt−3wt−1,wt−2,wt−3这三个输出为例。
最左侧为输入,输入wtwt的表示是用的one hot编码。最右侧是期望的输出wt−3,wt−2,wt−1…wt−3,wt−2,wt−1…,期望的表示也用one hot编码表示。所谓one hot编码,前文也有说明,很简单,就是一个列向量,该向量长度等于(数据集中)所有词汇的个数。对于某个单词,除了该词汇对应的索引位置对应的值为1,其他的都为0。在该图中,词汇个数是V,所以wtwt的维数是v*1。图中可以看到wtwt的表示就是(0,0,0,0,1,0,0)T(0,0,0,0,1,0,0)T。输入层的下一层是映射层(projection),映射层的下一层就是输出层,到达该层后,需要再通过一个softmax函数,转成概率输出。前文有说明,中间没有激活函数。也就是说参数只有图中的两个矩阵,一个是输入层与映射层之间的权重矩阵WW,维数为d*V,一个是映射层与输出层之间的权重矩阵W′W′。所谓神经网络的训练,就是获得权重的合适值,训练完成后,权重矩阵WW就是我们所需要的词向量矩阵。为何这么讲,因为我们可以看到映射层vcvc是通过矩阵运算WwtWwt得到的,而wtwt只有一个1,也就是最终向量是W矩阵的某一列,该列就是表征了wtwt的向量。所以说WwtWwt等于vcvc。于是vcvc就是W矩阵的一列。同样的W′W′为V*d的矩阵,W′vcW′vc得到输出的(未经过softmax前的)向量。将W′W′的每一行取出来,并转换为列向量,命名为uiui,可以看到uiui和vcvc一样都是d*1的列向量。此处的u和v和前文提到的u和v是完全一样的意义,所以可以回头理解那里的u和v了。可以看到,未经过softmax前的第i个结果等价于uivcuivc。然后再经过softmax层,大家也都熟悉。然后与真实的、期望的目标对比,得到损失,就可以根据sgd进行推导和更新权重了。

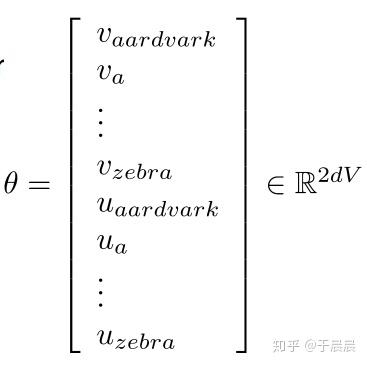
通常,我们会将模型中的所有参数都放在一起,做一个长的参数,统一叫做θθ。在这个模型中,就两个权重矩阵,也可以用v和u表示。如下图图8,vaardvark…vzebravaardvark…vzebra表示从第一个单词对应的v到最后一个单词对应的v,u同理。v和u都是维数为d*1,都是有V个,所以最终θθ的含有2dV*1维的参数列向量。
至此,Skip-grams算法框架已经讲完了。在机器学习里,训练一个网络就是更新权重,更新权重就要求导。类似于bp算法,但是因为此网络特别简单,所以推导倒数简单多了。下一节2.3节会计算梯度的导,基于此导数就可以更新权重了。如果不想费脑细胞,可以跳过2.3,直接看2.4节。
2.3 Skip-grams(SG)算法求梯度的导
所谓bp算法,不过是链式法则在神经网络计算中的应用而单独起的名字。如果叫做链式法则,大家应该就会觉得easy很多。看下图图9和图10,主要是向量求导的基本公式,其中x,ax,a二者都是列向量。该公式的推导,可以将公式展开就可以明白。至于链式法则,这个是基本内容,无需多言。
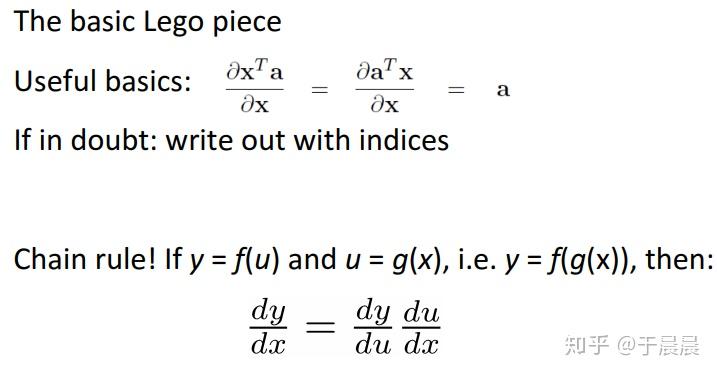



如前文所述,θθ表示模型中的所有参数,J(θ)J(θ)表示我们的目标函数。如图11, 众所周知,梯度下降的参数更下公式如下图,针对每一个θjθj,都是旧的θjθj减去步长αα乘以J(θ)J(θ)对θjθj的导数。


梯度下降的效果展示如下图12。蓝色的箭头之间是一步,红色的圈是等值线,越里面表示值越小,也就是目标函数越小。从图上来看,逐渐目标函数减至最小。

上面就是对链式法则和梯度下降的基本认识。基于此,我们需要求对参数的导数,去更新迭代参数。 通过图13,再来回顾下我们的目标函数及概率公式。目标函数是一个累加和,那么只需要关注logp(wt+j|wt)logp(wt+j|wt)的求导就可以了。依据前文p(o|c)p(o|c)的公式,得到图13中的logp(o|c)logp(o|c)的公式。(注:图13中目标函数前面少一个负号,不过不影响计算过程,读者知道就好。)


前文提到,θθ参数包含两个矩阵WW和W′W′,而WW是由v1,v2,…,vVv1,v2,…,vV等V个列向量组成,W′W′由ui,u2,…,uVui,u2,…,uV组成。 所谓求梯度,就是针对v和u进行求梯度。针对每一个输入wtwt,假定对应的索引是c,可以从图7知道,到了映射层就只剩下vcvc,也就是跟vi,i=1,…,V,i≠cvi,i=1,…,V,i≠c无关。所以每一次迭代的求导,只需要求dJ(θ)vcdJ(θ)vc及dJ(θ)ui,i=1,2,…,VdJ(θ)ui,i=1,2,…,V。我们先推导dJ(θ)vcdJ(θ)vc,然后再去推导dJ(θ)ui,i=1,2,…,VdJ(θ)ui,i=1,2,…,V。如上一段所言,求dJ(θ)vcdJ(θ)vc,最核心的就是求dlogp(o|c)dvcdlogp(o|c)dvc。
到此处,值得注意的一个问题是,这里的求梯度,更像传统的机器学习的方法,设定一个目标函数,然后求梯度,然后去优化参数。在深度学习里,通常是计算误差,然后bp算法,就是误差反向传播。所以此处,就是要去优化这个目标函数J(θ)J(θ)。好, 我们继续推导。
下图14,其实同图13是一样的。m是窗口长度,T是文本长度,就是一共有多少个词(可重复)。u和v前文已经提到, o和c是分别是输入词和输出词的索引。


dp(o|c)vcdp(o|c)vc可以分为下图15中的式子1的求导和式子2的求导。其中vcvc和uouo都是列向量,uTovcuoTvc是实数。公式1的求导就非常简单,基本公式就可以得知。


下图16,就是式子2的推导。第一步,依据链式法则,可以从第一行推导到第二行。第二行中,变量名称w变为x,这是因为不要跟前面的w混淆,前面的w是累加和,后面的x,因为后面要用到。对累加和求导等于求导后的累加和,求导可以进到里面。然后再次利用链式法则,就可以得到倒数第二行。倒数第二行利用基本公式就可以得到最后一行。


通过前面的推导,将式子1和式子2进行整理,就得到了图17。至于后面的整理,读者自己看一看就能明白。值得说明和再思考的是结果。前面时uouo,这个是列向量,是W′W′矩阵的第o行转置后的列向量。 p(x|c)p(x|c)是模型(经过softmax)的输出,是个实数,也就是输入wtwt,模型的输出,可以参看图7中的倒数第二列。所以,最后求导的结果是观察到的值uouo与给定输入输出的平均期望的差值。这一点,不理解也没关系。总之,至此,J(θ)dvcJ(θ)dvc已经求解了,然后就可以愉快的更新权重矩阵WW,也就是WW中的vcvc列向量了。


前面时J(θ)J(θ)对vcvc的求导,此处来求J(θ)J(θ)对uiui的导。这个求导应该分两种情况进行讨论求导,一个是当i=oi=o时,也就是J(θ)J(θ)对uouo的求导,另一个是当i=1,2,…,V且i≠oi=1,2,…,V且i≠o时,J(θ)J(θ)对uiui的导。 这两种情况的求导也是比较容易的。可以看图18和图19。图18对应第一种情况i=oi=o时的求导,图19对应第二种情况的求导。


图19:dp(o|c)ui,i=1,…,V且i≠odp(o|c)ui,i=1,…,V且i≠o推导
至此,目标函数对于参数的求导已经完成,可以用梯度下降法进行迭代参数了。也是至此,skip-grams算法算是解析完了。
2.4 Continuous Bag of Words(CBOW)算法
前面2.1节提到,word2vec有两种算法,一个是skip-grams算法,一个是Continuous Bag of Words(CBOW)算法。2.2节和2.3节是skip-grams的精讲。有节讲解CBOW算法,由于CBOW算法与skip-grams算法比较类似,本节只说明原理及区别。
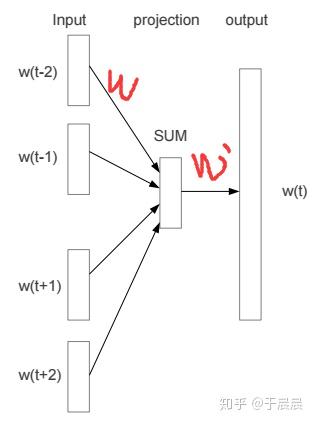
图20是skip-grams算法的框架,图21是CBOW算法的框架。我们已经很熟悉skip-grams算法了。输入层,然后是映射层,再然后是输出层。skip-grams的逻辑是,给定输入的单词wtwt,去预测该词的上下文。而CBOW则是给定某个词的上下文,去预测该词。同样的,两个模型的最终优化的都是两个权重参数矩阵WW和W′W′。CBOW多个词到映射层后,进行累加,得到映射层的向量,然后再乘以W′W′矩阵,得到输出,就这么多区别。图21中,wtwt画的长度较长,实际上,它的长度是与wt−2wt−2等是一致的,都是one hot编码后的向量。

我们再来看看,skip-grams 与 CBOW各自的优缺点,本文列举网页[11]的观点。 对于CBOW,优点是 1. 预测单词的概率是很自然的事情 2. 需要的内存少。缺点是:1. CBOW取的是上下文的平均值。比如,apple既可以是水果,也可以是公司,通过CBOW的方法会使apple的向量位于水果和公司之间。2.如果没有一个合适的优化,可能要训练很久。对于skip-grams的算法,优点是:1. skip-grams可以捕获一个单词的两种语义,比如apple,它将有两个向量,一个表示水果,一个表示公司。2. 具有negative sub-sampling的skip-grams通常泛化性能优于其他方法。
笔者认为,关于skip-grams能区分一个单词的两种语义,从模型上来看,似乎有那么些道理,但是两个向量不知道在哪里。同时关于CBOW的缺点2,我不太认可,对于神经网络而言,一般来说,一般赋予较小的随机初始值,训练都不会有太大问题。至于skip-grams效果好,这个倒是对,从Mikolov的paper的结果来看,skip-grams总体的确更好一些。
2.5 Hierarchical softmax
前文的2.2,2.3,2.4主要是讲skip-grams和CBOW两种算法。接下来的2.5,2.6,2.7节三节主要讲算法的优化方法。因为数据量的增加,对于大规模的数据集,需要提供更有效的训练方法。
我们可以注意到,在2.2节的两个参数矩阵中,我们要的是WW矩阵,而W′W′和sotfmax层都不是我们要的,它们仅在训练的时候存在。但是从2.3节的求导,发现,每一个输入wtwt,都要计算一遍W′wtW′wt,同时,也要计算一遍每个词的softmax以得到概率。这个效率是非常低的,所以这里就引入了第一个方法,用Hierarchical softmax来替代映射层之后的W′W′矩阵及sotfmax层。这里等价于说,在新的框架里是,输入层到映射层之间不变,原先映射层之后的全部替换了,映射层到输出层是一个Hierarchical softmax。映射层经过Hierarchical softmax之后就能得到前文提到的概率p(o|c)。至于怎么得到的,就是下文要讲的。
Hierarchical中文翻译叫做分级的意思,Hierarchical softmax又简称H-softmax,该方法是由Morin and Bengio在2005年的paper[13]提出的,在word2vec里,作者利用了这种方法去提高训练速度。通过使用Hierarchical softmax替换传统的softmax,可以将复杂度由之前的O(V)降低至至O(logV)。
下面是细讲。
首先,我们需要有预备知识——哈夫曼树(Huffman Tree)。我们来看一下建立哈夫曼树的过程。
输入:权重为(w1,w2,…,wn)(w1,w2,…,wn)的n个节点。
输出:对应哈夫曼树。
- 将(w1,w2,…,wn)(w1,w2,…,wn)看做n颗树的森林,每个树仅有一个节点。
- 将森林里权重最小的两棵树进行合并,得到一棵树,将这两棵树分别做为新树的左右节点,且左节点权重小于右节点,树的根节点为左右两颗树的权重之和。
- 将之前权重最小的两棵树从森林里删除,并把新树加入森林。
- 重复2-3的步骤,直至森林里只剩一棵树为止。
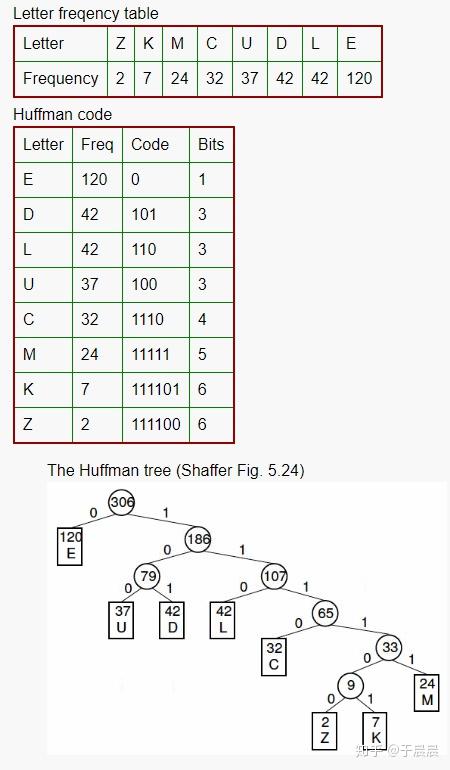
下图22,是我从网上找的一个简单的哈夫曼树例子。建立哈夫曼树的好处是什么呢?就是对其进行哈弗曼编码(Huffman encoding),左侧为0,右边为1。可以看到这种长短不一的编码,权重越高,越接近根节点,编码长度越小。这种编码的期望编码长度是最小的。

在word2vec这里怎么用的呢?首先利用统计得到的单词的频率(或叫权重)按照上面的方法建立一个哈夫曼树,如下图图23所示。可以看到这颗哈夫曼树的叶子节点就是V个单词。不同的是这棵树的每个非叶子节点都有名称n(w,j)n(w,j),且每个非叶子节点都有一个列向量v′v′(可以类比前文的uu),维数也是d*1。同前文类似,这里的模型的参数就是vv及v′v′,刚开始一样是随机初始化,然后进行梯度下降法。
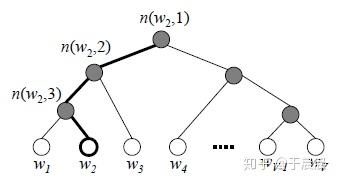
那么如何怎么计算某个叶子节点的概率呢?可以参考下图24,值得关注的是,此处的部分符号与前文有些出入。我们希望的计算p(o|c)p(o|c),σσ表示sigmoid函数,σ(x)=11+e−xσ(x)=11+e−x,h此处是wtwt到映射层的列向量,等价于前文的vcvc。σ(−u)=1−σ(u)σ(−u)=1−σ(u)这个是sigmoid函数的性质,通过展开公式就可以得到。
下图中,计算的是p(o|c)p(o|c),计算的时候就是第一个分叉为左的概率*第二个分叉为左的概率*第三个分叉为右的概率。第一个分叉的概率为左侧的概率就是σ(v′w2∗vc)σ(vw2′∗vc),其中vcvc等于图中hh,是列向量, v′v′是模型中的参数。类似于前文的softmax是天生的将实数转化为概率的方法,sigmoid函数正式二分类的实数转成概率的方法。下面的概率计算类似,最终三个概率相乘,就得到了,我们想要的p(o|c)p(o|c)。


对比,2.2和2.3节,此处的概率计算只有很少词(图24中的只有3次),而之前是要计算V次。所以,复杂度从之前的O(V)降低为O(logV)。
2.6 Negative sampling
这里是Tomas Mikolov等人提出的方法。前文提到,Hierarchical softmax和Negative sampling两种都是优化方法,这两种优化方法是二选一的,类似于skip-grams和CBOW的二选一。
以skip-grams为例,原来的sotfmax的逻辑及目标函数的逻辑,就是我们预测的wt−m,…,wt−1,wt+1,…,wt+mwt−m,…,wt−1,wt+1,…,wt+m的概率最大化,非目标词概率最小化。每一个输入wtwt,都要去改变目标词输出的权重uouo,同时也会更改非目标词的权重ui,i=1,…,V,i≠oui,i=1,…,V,i≠o。每一次都是考虑了输出词的概率,也考察了所有非输出词。我们知道,所有非输出词才是众多的(V-2m-1个)。但是,我们需要思考一个问题,所有的非输出词有必要每次都考察吗?答案,没有那个必要。如果从二分类的视角去考察,wt−m,…,wt−1,wt+1,…,wt+mwt−m,…,wt−1,wt+1,…,wt+m这些输出是正,而其他所有词都是负。可以得知,负样本是非常多,基于此,Negative sampling的核心思想,就是对负样本进行抽样,从所有负样本中只抽取几个去更新权重。
在Negative sampling的思想下,就可以替换softmax层了。目标函数如下图图25。前文提到σσ是用来转换成概率的,k是我们要用到的负样本的个数。左侧的logσ(uTovc)logσ(uoTvc)是正样本的输出,我们希望此概率越大越好。而右侧是表示要抽出k个负样本,每个负样本j都要概率符合分布P(w)P(w),然后他们的概率累加和是越小越好。sigmoid函数是单调递增函数,且恒大于零。
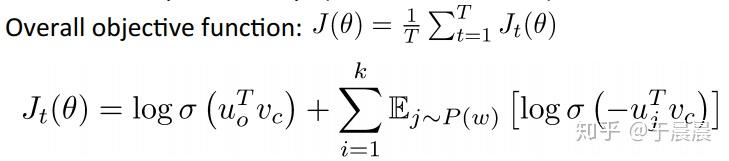

下图26中的目标函数公式更加清晰,值得关注的是,这里的目标函数是希望越大越好。如果想像以前一样,概率越小越好,前面加负号就可以了。所谓P(w)P(w)分布,就是原始单词的概率分布的概率开3/4次方,并归一化。也就是整体而言,原始样本中单词出现次数越高,越容易作为负样本进行训练。至于为何是3/4,这个是实验测的,换成其他的也没太多问题。


2.7 Subsampling of Frequent Words(高频词汇的重采样)
这一段是常用词降采样。这个更没什么好说的了。简单而言,就是不用所有的词训练。因为有次常用词,比如a、an、the等出现的次数很高,如果全部样本用来训练,可能也没太多必要。
最终,就是抽样,一个词出现频率越高,那它抽取的比例越低。这个比例怎么算呢?是采用一个公式。假定单词wtwt在训练集中出现的概率(或叫比例)是z(wt)z(wt),则我们会随机保留P(wt)P(wt)比例的wtwt样本进行训练,其他不会训练。比例的计算公式如图27。

我们可以将w(wt)w(wt)与P(wt)P(wt)转换函数画出来,如图28。可以看到,此函数是单调递减的,也就是说,单词wtwt原始比例越多,保留的比例越小。有几个重要节点,可以关注。
- z(wt)≤0.0026z(wt)≤0.0026时,P(wt)=1P(wt)=1。
- z(wt)=0.00746z(wt)=0.00746时,P(wt)=0.5P(wt)=0.5。
- z(wt)=1z(wt)=1时,P(wt)=0.033P(wt)=0.033。
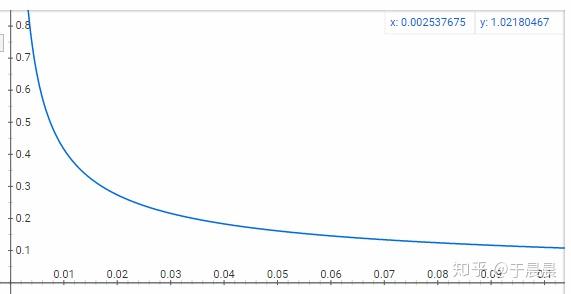

图28:w(wt)w(wt)与P(wt)P(wt)转换函数对应的图
以上就是word2vec的所有核心解析了。
2.8 word2vec效果展示
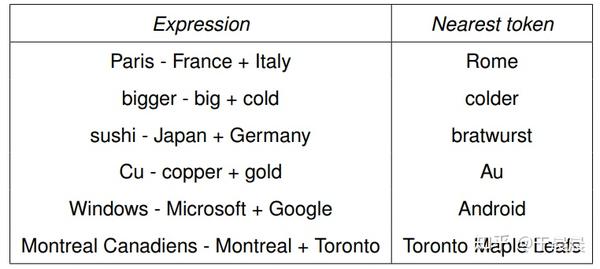
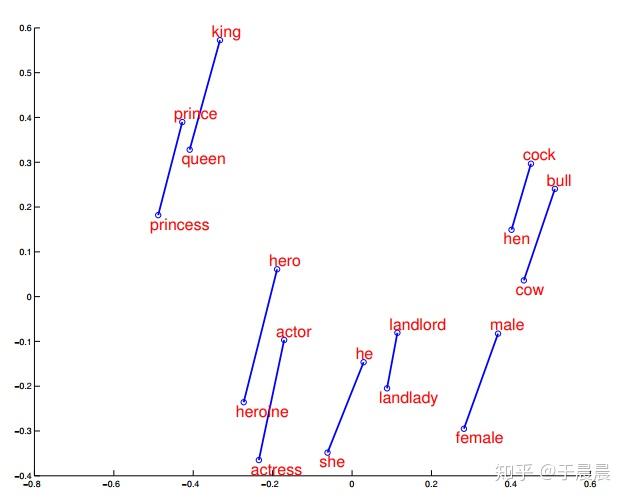
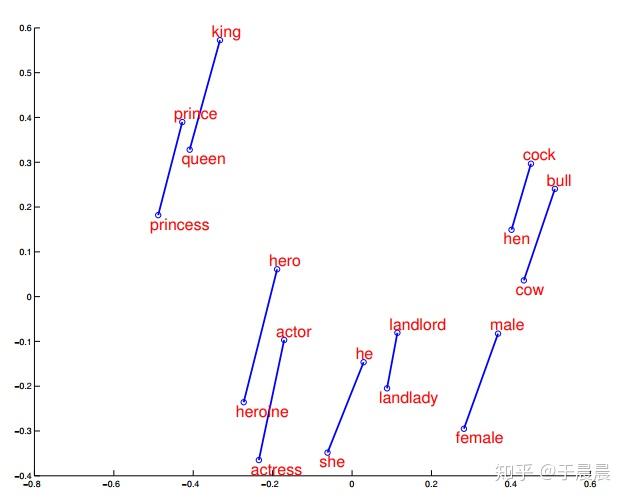
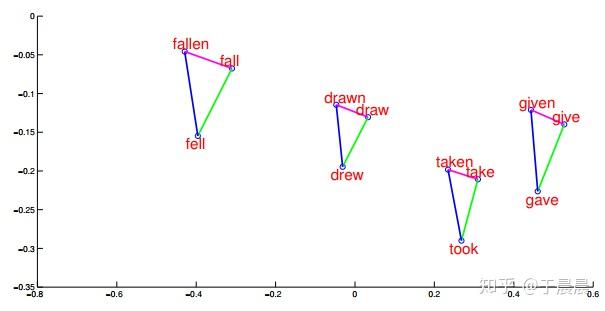
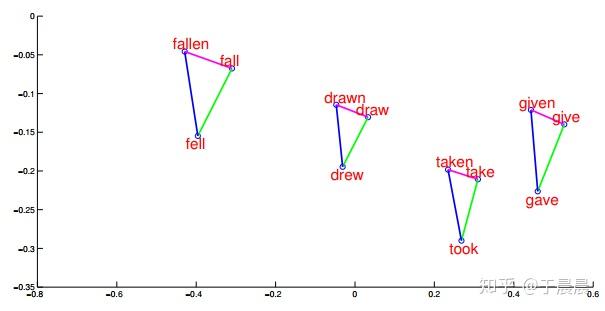
word2vec效果,大家通常喜欢讲这个公式 king−man+woman=queenking−man+woman=queen。下面图29,30,31就是一些词汇在空间中的映射降维后的展示,可以明显看到,通过word2vec可以学到词与词之间的关系。
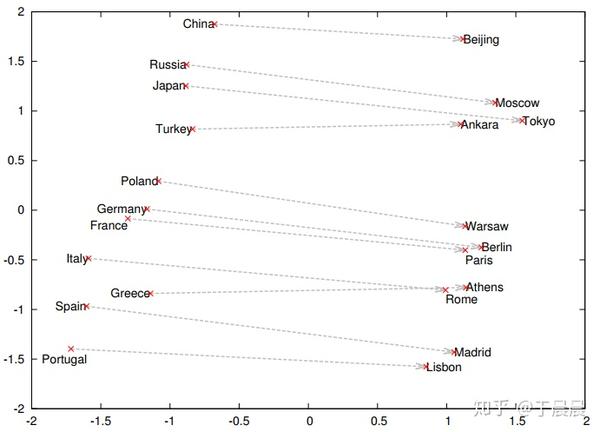
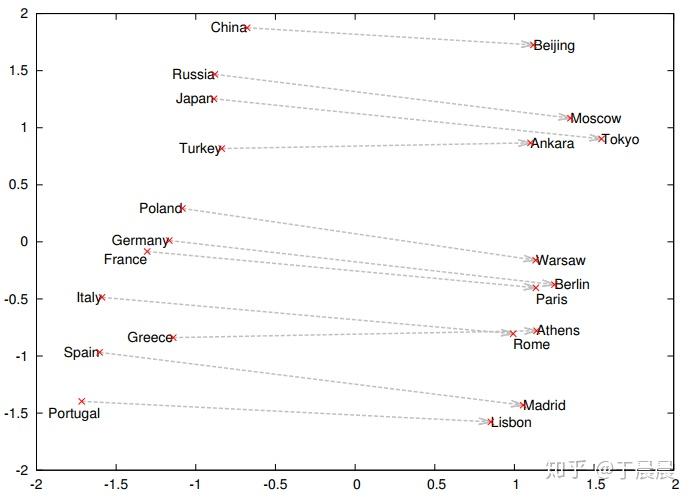
图29可以看到,word2vec学到了词语之间的矢量加法。图30表示,word2vec学会了词语之间的矢量关系,也就是内在关系。图31表示word2vec学会了词之间的过去时、过去完成时之间的转换关系。图32表示word2vec学会了国家与首都之间的矢量对应关系。

word2vec在翻译中的应用。当有了相匹配的语料进行训练时,词向量之间应该有相似的架构。在不同的语言之间,也应该保留这种相似性。下图33左侧是英文,右侧是西班牙语,经过旋转和缩放后,可以看到,相似的动物形成的词向量是很相近的。


三、 word2vec代码实践
明白了原理之后,我们就要去实践中用这些词向量了,这里是词向量的简单使用。一个是可以使用google基于google news训练好的词向量模型,一个是自己去训练词向量。推荐一个工具包gensim,使用的是python语言。下面我们会使用这个工具包进行加载google的word2vec模型,及自己训练模型。
3.1 使用google预训练好的模型
google的预训练好的模型,可以从此处[10]下载。大约1.5g,解压后3.4g。安装好gensim库后,调用就非常简单了。代码示例如下:
from gensim.models import KeyedVectors
g_w2v_model_file = 'GoogleNews-vectors-negative300.bin'
w2v_model = KeyedVectors.load_word2vec_format(get_abspath(g_w2v_model_file),
binary=True)
computer_vector = w2v_model['computer']
print(computer_vector)
print(computer_vector.shape)上面的这段代码,完成了对预训练好的模型的加载,输出了computer的词向量及维数。
值得关注的是,该模型是区分大小写的,比如computer和Computer是不同的,但是总体还是很相似的。
一些关于google预训练的模型的疑问及解答[10]。
- 它包含停用词吗?
一些停用词a、an、and、of被此模型排除在外,但是the、also、should等此被保留了下来。
- 是否包含词汇的错拼/错写?
是的。比如mispelled和misspelled两次都在里面,其中,misspelled这个词是正确拼法/写法。
- 是否有常用的成对出现的词?
是。比如包含Soviet_Union(苏联)、New_York(纽约)。
- 是否包含数字?
并不直接是。 比如,你不能找到数字 100, 但是它的确包含类似于 ###MHz_DDR2_SDRAM ,这里假设 # 可以匹配任何数字。
3.2 自己语料训练模型
使用gensim也可以根据自己的数据集训练模型,用法也非常简单。
下面是训练的方法:
from gensim.models.word2vec import Word2Vec
texts = [["hello", "world"], ["we", "are", "right"]]
w2v_size = 300 # 词向量长度
w2v_min_count = 1 # 最低计入训练的词频
w2v_model_file = 'w2v.model' # word2vec模型保存文件名称
w2v_model = Word2Vec(sentences=texts, size=w2v_size,
min_count=w2v_min_count)
w2v_model.save(w2v_model_file)下面是自己训练的模型的加载及使用方法
from gensim.models.word2vec import Word2Vec
w2v_model_file = 'w2v.model' # word2vec模型保存文件名称
w2v_model = Word2Vec.load(w2v_model_file)
we_vector = w2v_model['we']
print(we_vector)
print(we_vector.shape)通过此部分,相信你已经可以进行一些实战了。关于word2vec的更多用法,建议可以去看gensim的官方文档。关于google预训练的模型的更多问题,可以查看博客[15]的分享及代码。
参考资料
- Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
- https://docs.google.com/file/d/0B7XkCwpI5KDYRWRnd1RzWXQ2TWc/edit
- https://code.google.com/archive/p/word2vec/
- http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
- http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
- http://mccormickml.com/2016/04/27/word2vec-resources/
- https://www.youtube.com/watch?v=ERibwqs9p38&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6&index=3&t=0s
- https://www.youtube.com/watch?v=ASn7ExxLZws&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6&index=4&t=0s
- https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit?usp=sharing
- https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
- https://ronxin.github.io/wevi/
- Morin, Frederic, and Yoshua Bengio. “Hierarchical probabilistic neural network language model.” Aistats. Vol. 5. 2005.
- https://www.cnblogs.com/pinard/p/7160330.html
- http://mccormickml.com/2016/04/12/googles-pretrained-word2vec-model-in-python/