
布隆过滤器(Bloom Filter)详解

作者:Zarten
知乎专栏:Python爬虫深入详解
知乎ID: Zarten
简介: 互联网一线工作者,尊重原创并欢迎评论留言指出不足之处,也希望多些关注和点赞是给作者最好的鼓励 !
介绍
布隆过滤器(Bloom Filter)是1970年被布隆提出来的,用于判断某个元素是否在一个集合中,优点是空间效率和查询时间都非常高,缺点是有一定的误判率和删除困难。
布隆过滤器原理
布隆过滤器实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。如下图所示:
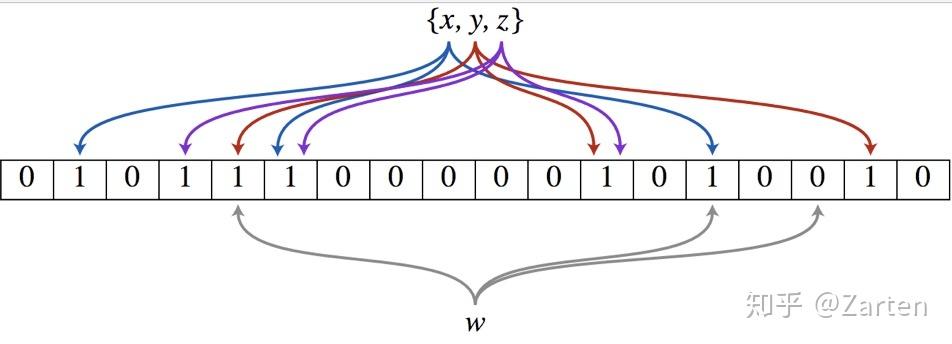

如何判断某个元素是否在这个集合中呢?
同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。就是这么简单!
优点:可以看到就是节省空间,采用位数组,2的32次方=4294967296 可以看到42亿长度的位数组占用 4294967296/8/1024/1024=512MB 只需占用512MB的内存空间
缺点:有一定的误判,有可能把不在这个集合中的误判为在这个集合中,因为另一个元素经过哈希后各个位置也可能为1,其实把这个位数组的长度缩短为很小(比如10)就很好理解了
MurmurHash哈希
MurmurHash是一种非加密型哈希算法,一般用于哈希检索操作。是Austin Appleby在2008年发明的,并出现了多个变种版本,当前版本是MurmurHash3,能够产生出32-bit或128-bit的哈希值。这种哈希算法对于随机分布特征表现更加优良,被广泛运用redis、Hadoop等。
在布隆过滤器中的哈希算法就是采用这种算法
在python包中 mmh3 这个第三方包就是MurmurHash
安装:
pip3 install mmh3这个库是c++编写的,若在windows中安装,可能会出现如下的错误:


这是因为没有c++的编译环境,解决方案是根据提示给出的url安装VS,退出cmd后重新安装,若还是不行,将VS安装路径下的cl.exe添加到环境变量中
布隆过滤器实现
import mmh3
from bitarray import bitarray
class Zarten_BloomFilter():
def __init__(self):
self.capacity = 1000
self.bit_array = bitarray(self.capacity)
self.bit_array.setall(0)
def add(self, element):
position_list = self._handle_position(element)
for position in position_list:
self.bit_array[position] = 1
def is_exist(self, element):
position_list = self._handle_position(element)
result = True
for position in position_list:
result = self.bit_array[position] and result
return result
def _handle_position(self, element):
postion_list = []
for i in range(41, 51):
index = mmh3.hash(element, i) % self.capacity
postion_list.append(index)
return postion_list
if __name__ == '__main__':
bloom = Zarten_BloomFilter()
a = ['when', 'how', 'where', 'too', 'there', 'to', 'when']
for i in a:
bloom.add(i)
b = ['when', 'xixi', 'haha']
for i in b:
if bloom.is_exist(i):
print('%s exist' % i)
else:
print('%s not exist' % i)
布隆过滤器嵌入到scrapy-redis中
思路是将布隆过滤器的位数组用redis的bitmap代替,由于redis最大申请空间为512MB,故设置位长度为: 2的32次方
主要使用redis的 setbit 和 getbit 方法,删除用redis_conn.delete(key名称)
1.将下面的bloomfilter.py放在scrapy_redis源码的目录中
import mmh3
class BloomFilter():
def __init__(self, redis_conn = None, key = 'bloomfilter', capacity = 2 ** 32):
self.capacity = capacity #512MB
self.key = key
self.redis_conn = redis_conn
def add(self, element):
position_list = self._handle_hash(element)
for position in position_list:
self.redis_conn.setbit(self.key, position, 1)
def is_exist(self, element):
position_list = self._handle_hash(element)
result = True
for position in position_list:
result = self.redis_conn.getbit(self.key, position) and result
return result
def _handle_hash(self, element):
postion_list = []
for i in range(41, 51):
index = mmh3.hash(element, i) % self.capacity
postion_list.append(index)
return postion_list
2.改写scrapy-redis源码中的dupefilter.py文件
1.依次添加
from .bloomfilter import BloomFilter2.在_init_函数中
self.bf = BloomFilter(server, key)

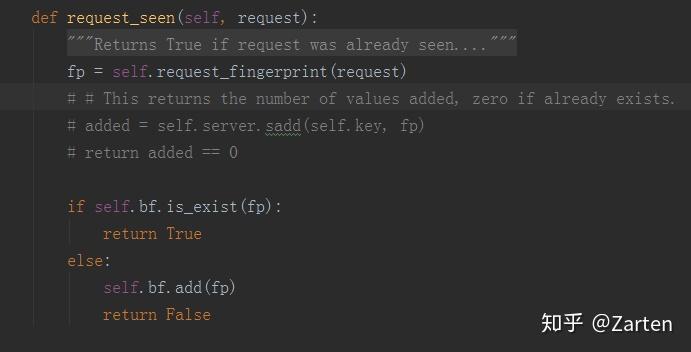
3.request_seen函数中改写过滤规则
fp = self.request_fingerprint(request)
if self.bf.is_exist(fp):
return True
else:
self.bf.add(fp)
return False

注意:这个申请的空间最后完成爬虫后会 redis_conn.delete(key名称) 掉,若是自己的额外需要过滤的元素,开始申请空间后,最后也可以redis_conn.delete(key名称)来释放掉空间。
使用scrapy_redis_bloomfilter
改写完后如何使用起来呢?
改写完后将scrapy_redis(可以自己命名)放在scrapy的项目中,如下图所示:
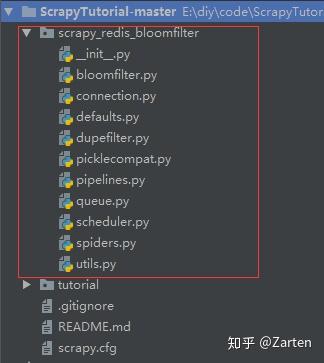
接下来跟使用scrapy-redis方法一样了,但在settings文件中换成自己的
SCHEDULER = "scrapy_redis_bloomfilter.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"



