
使用Flask创建微信公众号

基于Python3的Flask微信公众号后台
这次先用Flask为微信公众号做个后台。微信公众号后台一般对性能各方面要求并不高,这里我们以新浪SAE为例,其他已解析域名的服务器同理。整个过程比较简单,算是个快速的小项目吧
- 部署环境为python3+pipenv+flask+uwsgi/gunicorn+supervisor+nginx 其中我们uwsgi和gunicorn我会同步对比部署,篇幅太长主题不明,主要内容留在下篇,这里先说实现的问题吧
部署服务器
可以点击链接进行注册 说起新浪SAE(SinaAppEngine)类属Paas,这个还是比较不稳定的,好在前期不花钱,自带二级域名和HTTPS,控制台直接操作ssh秘钥,不支持系统内ssh密钥相比之下很适合做测试和微信这些。
注册地址 新浪SAE有提供免费的基于GIT的Python2.7共享环境,这里不用这个,实在是太难受了,我们选择自定义一个,选择手工部署Ubuntu,倘若Centos的弄nginx这些有点烦。


新浪云的Ubuntu新建用户后是无法ssh秘钥登陆的,在控制台改ssh秘钥。就忍受着用root用户吧。其他服务器用户还是新建用户比较安全。写文章虽然用的新浪云示范,往后的代码里为了区别权限都加上sudo
如果是新浪SAE记下自定义的二级域名,等下会用到

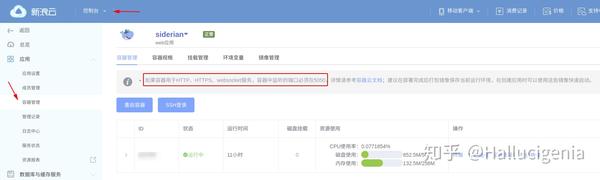
管理可以点控制台/应用/容器管理。这里我们注意框住的这句话,无论80还是443,新浪只开放了5050端口给我们。HTTPS也通用。这里后面都会用到

接入微信公众号
进入微信公众平台,如果没有公众号的话按流程申请即可,从主页中下滑,在左导航栏中最下面进入到 / 开发 / 基本配置界面。勾选协议成为开发者,
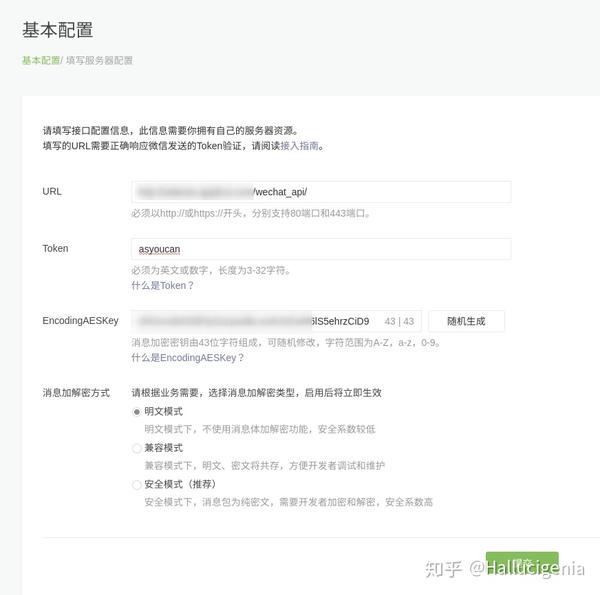

点击“修改配置”按钮,填写服务器地址(URL)、Token和EncodingAESKey,URL是与服务器通信接口的接口URL,我们填入服务器的解析域名(SAE的二级域名)后跟一个自定义路由,http和https都可以,新浪云自带有https这是没问题的。Token可由开发者自由填写,用作生成签名(该Token会和接口URL中包含的Token进行哈希值比对验证安全性)将用作消息体加解密密钥。我们点随机生成,
微信后台接受一个GET请求需要的参数如下:
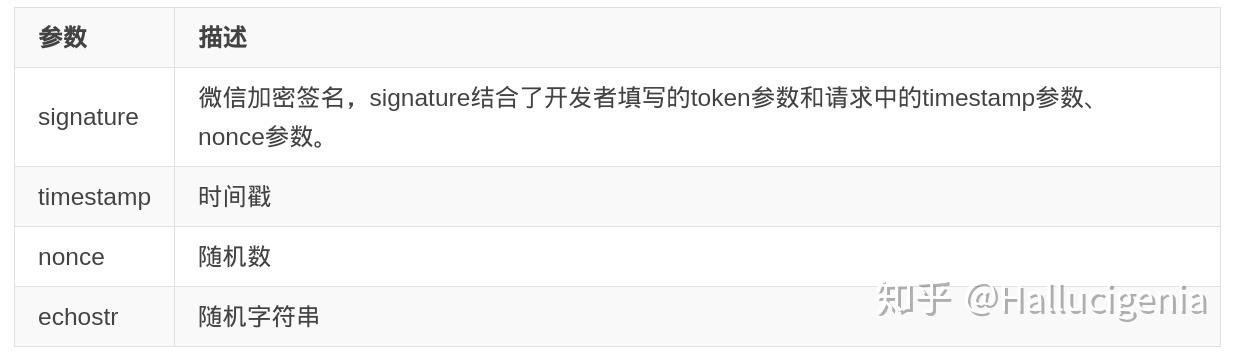

1)将token、timestamp、nonce三个参数进行字典序排序 2)将三个参数字符串拼接成一个字符串进行sha1加密 3)开发者获得加密后的字符串可与signature对比,标识该请求来源于微信
据微信的要求,我们尝试编写flask后台。先部署下基本环境
sudo apt update & upgrade
sudo apt install python3-dev python3-pip
sudo pip3 install pipenv不是新浪SAE强烈建议创建adduser新用户,并usermod -aG sudo赋予权限。创建ssh密钥登录并关闭密码登录。 创建pipenv环境并进入安装flask这些就不多说了。如果未测试的话可以先简单编写个测试
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
@app.route('/wechat_api/')
def wechat():
pass
if __name__ == "__main__":
app.run(debug=True)
# app.run(host='0.0.0.0', port=5050)新浪SAE需要指定5050端口,Flask运行app.run()是默认的127.0.0.1:5000, 我们使用注释里的指定host参数即可外网访问。这是我们输入域名进入,可以看到Hello World!即可。
创建一个接口,参考微信提供的php编写flask,填入token和自定义的路由,
base.py:
import hashlib
from flask import Flask, request, make_response
import xml.etree.ElementTree as ET
WX_TOKEN = 'fancy'
# 这里填写公众号配置的token
app = Flask(__name__)
app.debug = True
@app.route("/")
def hello():
return "Hello World!"
@app.route('/wechat_api/', methods=['GET', 'POST'])
# 定义路由地址请与URL后的保持一致
def wechat():
if request.method == 'GET':
token = WX_TOKEN
data = request.args
signature = data.get('signature', '')
timestamp = data.get('timestamp', '')
nonce = data.get('nonce', '')
echostr = data.get('echostr', '')
s = sorted([timestamp, nonce, token])
# 字典排序
s = ''.join(s)
if hashlib.sha1(s.encode('utf-8')).hexdigest() == signature:
# 判断请求来源,并对接受的请求转换为utf-8后进行sha1加密
response = make_response(echostr)
# response.headers['content-type'] = 'text'
# 新浪SAE未实名用户加上上面这句
return response
if __name__ == '__main__':
app.run()
# app.run(host='0.0.0.0', port=5050)然后回到微信服务器配置的地方选择明文模式或者兼容模式。点选提交,
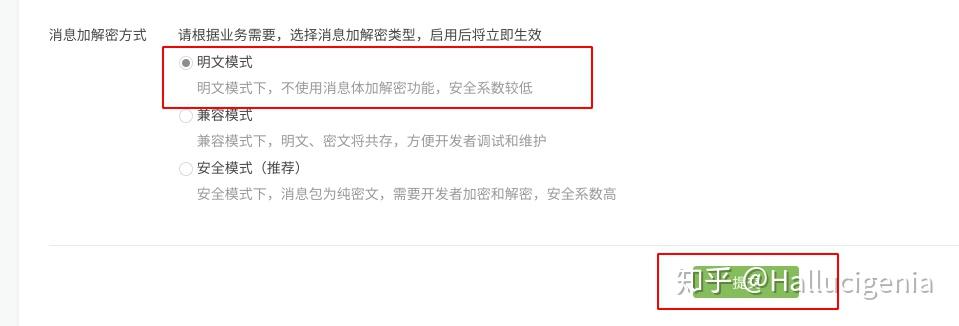

我遇到问题。由于我新浪SAE未实名还未审核通过,新郎SAE对未实名的在返回值内会带上奇怪的的html内容信息,从而导致Token验证失败。我们在返回值的头部带上'content-type' = 'text'即可。
到此,点击提交,应该就没问题了,如果显示Token验证失败,请回头再次检查一遍
接入后的应答
我们查看微信的文档,微信是这样说的:
还有一个接收事件推送,介于篇幅问题,这个留作下下次再说。 微信提供给开发者的通信接口是xml格式的,确实一直处理json,用xml还是感觉比较难受。这里使用 xml.etree.ElementTree 来解析。
分类有文本text,图片image,语音voice,视频video,小视频shortvideo,地理位置location,链接link。 这里由于没有太多硬性的功能,我希望简单化用户的操作,将功能全部先融合在输入框,根据用户输入的内容做出相应的判断,如果无法判断时或者没实际意义时,判断你可能只想聊天,再调用聊天机器人。
思路是初步判断消息类型,然后再逐个if-elif筛选下来。 - 首先判断文字模块,微信POST过来的XML数据包结构:


判断一个MsgType,主要用到的ToUserName,FromUserName,Content,我们先看如何回复文本消息:


那么好了,ToUserName,FromUserName实际在收发过程中是调转的,利用time()生成整型时间,我们先把结构起好 微信这里原来的GET请求验证不能删除,除此之外的POST我们直接else处理即可。
最开始和最后——图灵机器人
main.py:
from tuling import get_response
import xml.etree.ElementTree as ET
# ...
@app.route('/wechat_api/', methods=['GET', 'POST'])
def wechat():
if request.method == 'GET':
#...
else:
xml = ET.fromstring(request.data)
toUser = xml.find('ToUserName').text
fromUser = xml.find('FromUserName').text
msgType = xml.find("MsgType").text
if msgType == 'text':
content = xml.find('Content').text
return reply_text(
fromUser, toUser, get_response(
fromUser, content))
else:
return reply_text(fromUser, toUser, "嗯?我听不太懂")微信要求必须回复success(建议)或者空字符串防止轮询,我这里先将未分类的消息回复text这样感觉不会不理人。get_response 先判断一个text消息,接收Content再做判断是否为关键语句再针对回复。倘若没有即调用图灵机器人。 我们用的v2的api,用的是post请求一个json,json比较简单,这边不多说了,按API V2.0接入文档的示例即可
tuling.py:
import os
import json
import requests
TULING_KEY = os.getenv('TULING_KEY')
def get_response(openid, msg):
api = 'http://openapi.tuling123.com/openapi/api/v2'
dat = {
"perception": {
"inputText": {
"text": msg
},
"inputImage": {
"url": "imageUrl"
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "信息路"
}
}
},
"userInfo": {
"apiKey": TULING_KEY,
"userId": openid
}
}
dat = json.dumps(dat)
r = requests.post(api, data=dat).json()
mesage = r['results'][0]['values']['text']
print(r['results'][0]['values']['text'])
return mesage输出我们暂时只要results里的values输出值,取值范围是文本text,后期再一点点补充。 APIkey可以在这里找到
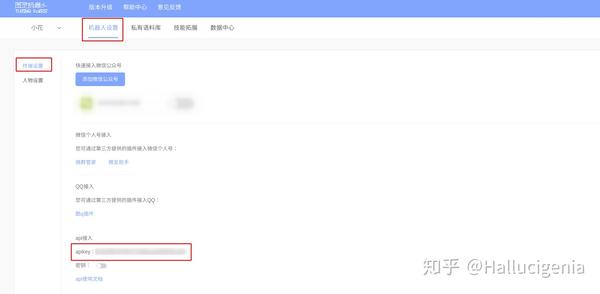

- 图灵机器人支持直接接入公众号,这件事就当我不知道 - 更新:图灵机器人支持关键词回复,可以添加各种语料库。这里目前没有回复复杂消息的需求就先简化代码。
回复微信的xml格式按照要求处理即可, main.py:
import time
from flask import make_response
# ...
def reply_text(to_user, from_user, content):
reply = """
<xml><ToUserName><![CDATA[%s]]></ToUserName>
<FromUserName><![CDATA[%s]]></FromUserName>
<CreateTime>%s</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[%s]]></Content>
<FuncFlag>0</FuncFlag></xml>
"""
response = make_response(reply % (to_user, from_user,
str(int(time.time())), content))
response.content_type = 'application/xml'
return response至此本地测试通过后用git方式什么都好推送到服务器端,运行python main.py应该手机端发送就没问题的。

附:官方提供的
这才刚刚开始,下一篇里我针对性的尝试探究下程序必须的措施pipenv+uwsgi/gunicorn+supervisor+nginx的部署,部署几次都没好好总结
下下篇里期望能将实现后续各种功能的添加诸如关注回复,查快递,语音识别,图片识别,查找附近美食,查电影听音乐这些吧,敬请持续关注。
