
【OM】京东如何在仓储库存部署时保证“啤酒尿裤”的高效履约?

编者按:作为中国最大的B2C自营线上零售商,京东商城当日达和次日达的履约比例超过90%,在行业内有着“极致体验”的口碑。在这极致体验的背后,是销量预测、库存管理、订单履约等强大数据能力的支撑。比如,消费者常常在一个订单中下单多种商品(比如咖啡机和咖啡豆)。如果我们能基于大数据,使得京东仓储的库存储备的时候,就提早的使得“经常被同一单订购的商品、一开始就库存部署在同一配送中心”,那么,这个进步,就可以避免一个订单多次配送的情况,从而得到更快的履约、以及为消费者带去“在同一个包裹就收齐了咖啡机和咖啡豆的快乐”。本文就是由京东的大数据和智能供应链部门的数据科学家和工程师撰写,讲述了京东,是如何通过“仓储库存选品”的优化,助力卓越的履约效率的。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
文章作者:京东大数据与智能供应链事业部
责任编辑:晓川
文章发表于微信公众号【运筹OR帷幄】:【OM】京东如何在仓储库存部署时保证“啤酒尿裤”的高效履约?
欢迎原链接转发,转载请私信 @留德华叫兽 获取信息,盗版必究。
敬请关注和扩散本专栏及同名公众号,会邀请全球知名学者发布运筹学、人工智能中优化理论等相关干货、知乎Live及行业动态:『运筹OR帷幄』大数据人工智能时代的运筹学
想象一下,你在网上订购了一台咖啡机和一袋咖啡,咖啡机第二天到了,但咖啡在三天后才到。一次下单同时购买多个商品,最后却被拆分成多个订单包裹陆续收货,这样的情况不知道您是否遇见过。


在这篇文章中,我们将结合在京东的实践经验,分享我们是如何通过算法优化在仓配网络中的不同节点的商品库存分配,来减少以上这样给客户带来困扰的情况。
作为中国最大的B2C自营线上零售商,相对于行业 ,京东的履约服务为消费者带来极致的体验,当日达和次日达的订单履约比例超过90%。
为了实现更快的交付速度和更好的客户购物体验,京东建立了一个多级仓配网络(图2),覆盖中国大陆99%的人口:包括区域配送中心(RDC),前置配送中心(FDC),以及我们称之为TDC的更低一级配送中心,以及其他类型的仓库等。 京东使用较低级别的配送中心,如FDC和TDC,以尽快满足中小城市的客户需求。从这样较低级别的配送中心发货的订单还可以节省额外的履约成本。
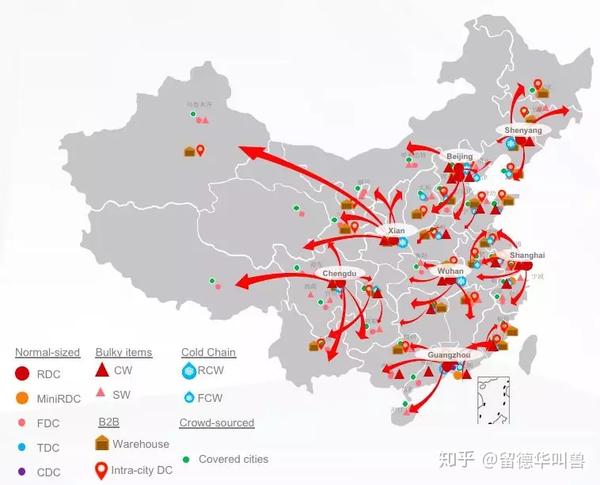

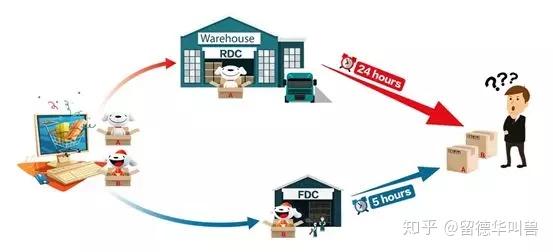
然而,FDC和TDC不能像RDC这样的大型配送中心拥有近乎全量的SKU(Stock Keeping Units)。 FDC的库存选品问题,是确定在FDC中存储哪些SKU,以更多的实现可完全从FDC履约的订单数量。如果客户下订单只包含一个SKU,则最近的FDC在有库存的情况下可以直接履约订单。如果订单中包含多个SKU,则有可能发生订单拆分。也就是说,因为最近FDC没有包含该订单所需的所有SKU,所以某些SKU需要由更高级别的配送中心(如RDC)来发出,从而导致订单拆分和可能不一致的货物送达时间(如图3所示)。

数学模型
让我们举例说明如何为单个FDC进行库存选品决策。
基于在一段时间内下达的订单历史数据,我们希望最大化仅由FDC本地库存即可满足的订单数量。假设一个订单中的所有SKU都在本地FDC中有现货库存,我们履约这样一个订单将获得1分奖励; 否则,因为订单将由多个配送中心拆分和履行,我们只能得到0分。对于在FDC内任意一种确定的库存选品组合,我们可以计算每个订单的奖励,计算出来奖励的总和即是不需要拆分履约的订单总数。然后问题变为找到最大化奖励的选品组合。然而,这种问题非常困难,因为可选的库存选品组合数量会非常大。从1000个候选SKU池中选择100个SKU形成组合可以产生6.38x10^139种可能性。而京东线上销售有数百万件商品,从中找到所有的选品组合,更是一件不可能的事。
在数学上,问题可以表述如下。我们将 I 定义为候选SKU的集合, J 定义为(唯一)订单类型的集合。每个订单类型 j∈J 与权重 v_j 相关联,权重 v_j 是它在订单集中出现的次数。我们将二元决策变量定义为 X_i ,如果在FDC商品库存中选择SKU i ,则 X_i , i∈I 为1;如果订单类型j可以仅由FDC分类满足,则 Y_j , j∈J 为1。注意到,我们假设在FDC中存放的SKU都是有足够库存的。这个决策问题的数学表达是:


其中K是可以存储在FDC中的SKU种类的总数量。
商品向量化
由于组合性质和问题的量级,完全解决上述优化问题是不切实际的。该问题在实际情况中可以包含超过1000万个决策变量,对于常规数学求解器(如CPLEX),加载如此规模的决策问题都是一件困难的事。
一种可以获得高质量答案的简易方法是使用启发式算法。最容易想到的方法,是可以通过受欢迎程度对SKU进行排名(我们在本文中将此算法称为为“贪婪排序算法”),然后按排名选择库存组合。背后的逻辑是,大部分的订单都包含热门SKU,如果库存大部分由热门SKU组成,就可以从该FDC履约更多订单。但是,因为贪婪排序算法并没有考虑哪些SKU更有可能被一起购买,所以不是足够好的解决方案。
为了获得更好的解决方案,我们真正需要的是订单级别的受欢迎程度,即最受欢迎的商品关联组合是什么?比如购买婴儿尿布的顾客是否更有可能同时购买啤酒?或某些特定品牌的婴儿小吃?
如果我们能够确定热门订单中哪些商品更有可能一起购买,并将其存放在FDC中,那么我们就有信心使得大部分订单可以由本地库存单独履约。然而,与单个商品的受欢迎度预测相比,订单模式(或商品组合)的流行度是极难预测的,因为产品之间组合的数量几乎无限大。
为了克服这一挑战,我们使用了一种名为SKU2Vec的技术来计算每个SKU的隐空间向量表示(latent vector representation)。这个想法是受Google的Word2Vec论文启发而来。该论文提出了一种无监督学习的方法,通过研究不同单词出现在一起的句子,来学习单词所表示的含义。在我们的例子中,SKU就像句子中的单词,包含多个SKU的订单,类似于包含许多单词的句子。
使用SKU2Vec,订单所隐含的背景信息被嵌入SKU隐空间向量中。如果两个SKU隐空间向量“距离”接近,我们知道它们更可能被一起购买,因此应该考虑一起存放在FDC中。


SKU2Vec方法遵循以下几个步骤。我们首先将某个包含N个商品的订单,通过把每个商品轮流从原始订单中剔除,人为转换为N-1个生成订单。其中,剔除的商品将作为该生成订单在监督模型的输入(标签)。该模型通过将生成订单中的N-1个商品作为输入,来尝试预测原始订单(N个商品)中被剔除的的商品是什么。作为输入的生成订单中的每个商品由低维向量表示,并且通过求取均值来获得这个生成订单的向量表示 – 称为订单意图向量。然后基于订单意图向量,模型会给出被剔除商品的预测。从这个意义上说,频繁出现在同一类订单中的商品应具有相似的向量表示,表明它们在订单背后所隐含信息的接近程度。
以下将某一阶段的订单交易数据作为输入进行训练后,利用TSNE,把商品的隐空间向量投影到2D空间进行可视化的示例图:
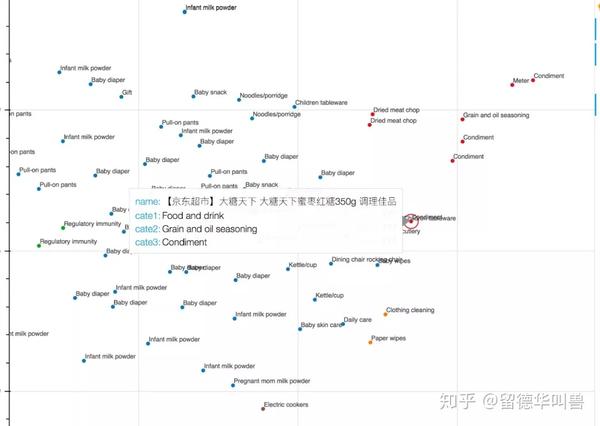

在图5中,蓝色圆点表示一堆婴儿尿布产品,右下方的红点包含几种零食产品,例如被视为产妇营养品的大枣。由于尿布是京东商城上最受欢迎的商品品种之一,几乎肯定会存放在FDC中。而通过这个可视化示例中尿布和大枣之间的密切关系表明,大枣(不是啤酒) 也应存放在该FDC,尽管大枣并不是最畅销的产品。


端到端神经网络框架
我们设计了一个端到端的神经网络框架,通过直接捕获商品之间的关联购买关系来制定库存选品策略。我们的主要创新点包括:
- 通过使用嵌入层将品类信息、SKU id等与商品相关的高维分类信息映射到可用作输入的潜在空间。
- 我们将订单拆分比率直接建模为损失函数,缩小预测和优化之间的差距。
网络架构如下所示:
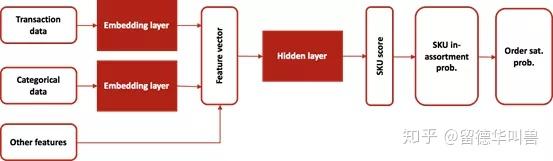

首先,我们获取所有商品层面的特征信息,如最近的销售,订单数量,页面浏览量等连续和离散特征。离散特征通过嵌入层映射到矢量,并与连续数量类信息结合。基于输入特征向量,计算每个商品属于该仓库库存选品的概率。最后,我们将原始订单中每个SKU的属于该仓选品的概率相乘,计算出该订单不被拆分的概率(整单履约率Z),即在FDC库存选品中覆盖订单中所有SKU的概率。
从这个意义上说,每当一对商品总是出现在频繁购买的相同类型的订单中时,该组合两种商品属于该仓库选品的概率应该以同步的方式接近1或0。否则,将任何一个商品包含在仓库中的好处就会消失(考虑一个产品的概率为1而另一个产品为0的情况,这导致不拆单的概率为0)。
算法表现评估
我们在三个主要区域仓库测试了SKU2Vec算法。我们如下所述以滚动的方式评估算法,其中2周的数据用作训练集,并且使用下周的订单对结果进行基准测试。

总体而言,与基准算法(“贪婪排序“算法的改进版本)相比,我们实现了约2%的订单拆分比率降低。订单拆分比率的降低意味着,原本每年需要履约的包裹数量减少200万件。这进一步意味着我们的仓库员工和送货快递员工作量的减少,以及更多的客户可以享受在同一包裹中收到咖啡机和咖啡的快乐。
目前,我们正在努力在我们的一些仓库中试用该算法并在生产系统中实施该算法。
在这篇文章中,我们展示了如何使用最先进的方法,如通过神经网络的商品嵌入算法来解决同时具有预测和优化性质的问题。这篇文章是关于存货布局问题的两个系列博客文章中的第一篇。在第二篇文章中,我们将重点关注更多以运筹优化方式,实现进一步的改进! (深度学习并不总是最好的方法,我们需要根据实际情况灵活处理。)
扫二维码关注『运筹OR帷幄』公众号:




