
BERT论文翻译

原标题:BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
地址:
我翻译的不是很好,主要是自己翻译一遍理解更深刻一点,泛泛而读经常会了解大意而忽略细节,以下是基于原文的翻译,实验部分略过了。另外在阅读前最好了解一下转换器模型和OpenAI GPT模型,不然准会看着云里雾里。
Transformer:
OpenAI GPT:
BERT 语义理解深度双向转换器预训练模型
摘要
我们介绍一个叫做BERT的新的语言表示模型,它可以理解为转换器的双向解码表示。不像最近的一些语言表示模型,BERT被设计成通过在所由层联合左边和右边的上下文来做深度双向表示的预训练。预训练的BERT表示可以通过仅仅一个额外的输出层的微调,在很多诸如问答,语义推断等自然语言处理任务上达到state-of-the-art的结果,而且不需要为特定任务在结构上做很大的改动。
BERT在概念上非常简单但是在实际运用中却很有效,他在是一个自然语言处理任务上都达到了state-of-the-art的结果,包括把GLUE benchmark的准确率提升到80.4%(7.6%的绝对提升),MultiNLI的准确率达到86.7%(5.6%的绝对提升),SQuAD v1.1的问答中F1值高达93.2(1.5的绝对提升),比人类的表现高2.0.
1 介绍
语言模型预训练对很多自然语言处理任务来讲都很有效,这些任务包括句子级的任务比如自然语言推断和解析,通过全面的分析句子来预测句子之间的关系,字词级别的人物比如命名实体识别和SQuAD问答,模型需要产生在字词级别产生很好的输出。
在预训练语言表示的下游任务中有两个现有的策略:基于特征和参数微调,基于特征的方法比如ELMo使用了把图训练表示作为额外特征的任务特定的结构。参数微调的方法诸如生成式预训练转换器,介绍了最少的人物特定的参数,然后再下游任务中通过简单的微调预训练的参数来训练。再前面的工作中,两种方式在与训练时都使用同样的目标函数,用五项语言模型去学习一般的语言表示。
我们认为当前的技术手段严重的限制了预训练表示的力量,特别是微调法。最主要的限制是标准的语言模型是单向的,这限制了可以被用来做预训练的结构的选择。比如,在OpenAI GPT中,作者使用了从左至右的结构,转换其中每一个字词在自我关注层只能关注前一个字词,这种约束对于句子级的任务是一种次优的解决方案。并且当把微调方法应用到诸如SQuAD这样的问答系统中会造成很严重的错误。因为双向的相关上下文对这种系统至关重要。
本文中我们会通过BERT: Bidirectional Encoder Representations from Transformers 来提升基于参数微调的方法。BERT对前面提到的单项模型通过使用新的预训练目标:遮罩语言模型(masked language model)(MLM)来添加新的约束。遮罩语言模型随机的从输入中遮罩一些词,目标是只通过它的上下文去预测这些遮罩词的id。不同于从左至右的预训练语言模型,MLM目标允许表示ro融合左右两个方向的上下文,这让我们可以预训练深度双向转换器。除了遮罩语言模型,我们还会额外的介绍联合了预训练和文本对表示的“下句预测”任务。
本文最主要的贡献在于以下几点:
* 我们阐述了语言表示双向与训练的重要性,BERT使用遮罩语言模型来做深度双向表示预训练。
* 我们展示了预训练表示消出任务特定结构。BERT是第一个在大量句子级和字词级任务中都达到state-of-the-art结果的基于微调的表示模型,比很多任务特定结构的系统表现得更好
* BERT在11个自然语言处理任务上都得到state-of-the-art结果。我们也BERT的扩展能力,对我们模型的双向性的阐述是一个单独的新的重要贡献。预训练模型的代码地址[BERT](goo.gl/language/bert)
2 相关工作
预训练语言表示历史悠久,这一节我们将简短的回顾一下最流行的几种方法。
2.1 特征法
近十年间,学习可以广泛应用的词表示在研究领域非常活跃,包括无神经网络的和神经网络式的方法.预训练词嵌入被认为是自然语言处理系统中的一个整体,对从头开始学习的嵌入提供了显着的改进。
这些方法都是粗粒度的,比如句嵌入或者段落嵌入。和传统的词嵌入相比,这些学习到的表示在下游模型中作为特征也很有用。
ELMo把传统的词嵌入研究使用了不同的方式泛化。它提出从语言模型中提取上下文敏感的特征。在遇到使用完整的上下文做词嵌入的特定任务结构时,ELMo在几个主要的自然语言处理任务上获得了state-of-the-art结果包括SQuAD问答,情感分析,和命名实体识别。
2.2 微调法
最近的从语言模型中做转移学习的一个趋势是微调之前在目标语言模型上预训练一些模型,目标语言模型会在下游任务中做监督训练。这些方法的优势在于只有很少的参数需要学习。就这一点优势让OpenAI GPT在很多句子级的任务中获得了state-of-the-art的结果。
2.3 监督训练集的转移学习
尽管无监督的预训练的一个优势是有几乎无限多的训练数据,从大量数据集中的有监督任务的转移学习也很有效,比如自然语言推断和机器翻译.除了自然语言处理领域,计算机方面的研究也证明了从大量预训练模型中做转移学习的重要性。一个很有效的诀窍是微调在ImageNet上与训练的模型。
3 BERT
这一节我们将要介绍BERT和它的详细的实现。首先我们看一看BERT的模型结构和输入表示。接着在3.3节我们会介绍预训练任务,也就是这篇文章的核心思想。预训练和微调的细节将会分别呈现在3.4和3.5中,最后,在3.6节我们会讨论BERT和OpenAI GPT的不同点。
3.1 模型结构
BERT的模型结构是一个多层双向转换器。因为最近转换器的使用越来越普遍,而且我们的实现和原始的实现基本相同,所以我们将省略掉这一部分的详细描述。
(译者注:在阅读这部分之前最好先搞清楚转换器是什么东西,因为有很多专有名词,不太好翻译,但是看了转换器模型基本上就明白了)
在这个模型中,我们用 L 代表层数, H 代表隐藏层的大小,self-attention heads用 A 表示,在所有的应用中,我们把前馈层的大小设置为 4H ,也就是说当 H=768 时前馈层大小为3072, H=1024 时,前馈层大小为4096,我们主要会介绍两种尺寸的模型:
* \rm BERT_{BASE}:L=12,H=768,Total Parameters=100M
* \rm BERT_{LARGE}:L=24,H=1024,A=16,Total Parameters=340M
\rm BERT_{BASE} 选择了和OpenAI GPT相同的模型大小方便对比。然而严格意义上来讲,BERT转换器使用了双向的自我注意机制,而GPT转换器使用的自我注意约束中每一个字词只注意了它左边的上下文。在这里需要指出的是,在文献中,双向的转换器经常被用来作为“编码转换器”,而只依赖于左边上下文的被称为“编码转换器”,因为他能用于文本生成。BERT,OpenAI GPT和ELMo之前的对比如下图所示。


3.2 输入表示
我们的输入表示可以用一个标记序列明确的表示单个文本和成对的语句(如[问题,答案])。对于一个给定的标记,它的输入由它对应的标记,片段和位置的嵌入来表示,如下图所示

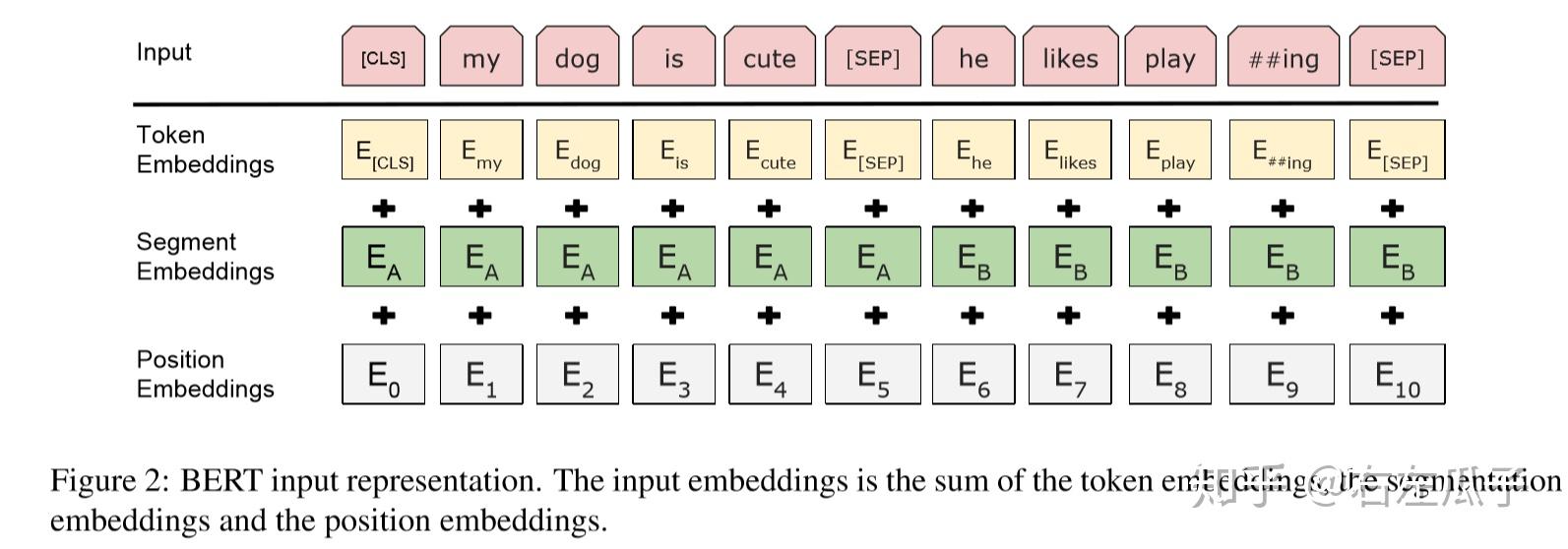
我们的标注的特点在于:
* 我们在30000个词上使用了WordPiece嵌入,把拆分的词片段(word pieces)用"##"标注(译者注:见图中"playing"-"play ##ing")
* 我们使用了学习过的位置嵌入,支持序列长度达512的标记
* 每一句的句首使用了特殊的分类嵌入([CLS])。这个标记。在最终的隐藏层中(也就是转换器的输出)对应的是分类任务中序列标识的聚合表示。非分类任务中这一标记将被忽略
* 句子对被打包在一起作为一个句子。我们用两种方法区别他们,首先,我们把他们用特殊的标记([SEP])区分开,然后我们会给第一句的每一个标记添加一个学习到的句子 A 的嵌入,给第二句的每个标记添加一个学习到的句子 B 的嵌入
* 对于单个句子输入我们只使用句子 A 的嵌入
(译者注:翻译的比较糟糕,直接看图会比较明白)
3.3 预训练任务
我们没有使用传统的从左至右或者从右至左的语言模型去预训练BERT,而是用了两个新的无监督的预测任务,将在这一节详细的描述
3.3.1 Tast #1: Masked LM
直觉上,我们相信深度的双向模型会比从左至右模型或者浅层次的从右至左和从左至右的连结要更强大。然而,标准的条件语言模型只能从左至右训练或者从右至左训练,因为双向的条件会让每个词都可以通过多层的上下文看到他自己。
为了训练深度双向表示我们使用了直接随机的遮盖住一定比例的输入标记,然后仅仅预测这些遮住的输入标记。我们把这种方式称为"masked LM"(MLM)。在这种情况下,被遮盖的标记对应的最终的隐藏向量被当作softmax的关于该词的一个输出,和其他标准语言模型中相同。在我们所有的实验中,我们在每一个序列中随机的遮盖了15%的WordPiece标记,和denoising auto-encoders(Vincent et al.,2008)相反,我们只预测被遮盖的词语,而不是重构整个输入。
虽然这允许我们做双向的与训练模型,但是这种方法仍然有两个弊端。第一个是这种方法会让预训练模型和调参法不能相互匹配,因为[MASK]标记在调参法中是不存在的。为了消除这个弊端,我们并不总是把遮盖的词用[MASK]表示,而是在训练数据中对随机的产生15%的标记用[MASK]表示,比如,在句子"my dog is hairy"中选择"hairy",然后通过以下的方式产生标记:
* 并不总是用[MASK]替换选择的词,数据通过如下方式产生:
* 80%的情况下:把选择的词替换成[MASK],比如:"my dog is hairy" → "my dog is [MASK]"
* 10%的情况下替换选中的词为随机词,比如:"my dog is hairy" → "my dog is apple"
* 10% 的情况下保持原词不变,比如:"my dog is hairy" → "my dog is hairy"。目的是把表示纠正为实际上观察到的词,所以它被清治的去保留每一个输入标记的分布式上下文表示。除此之外,因为随机的替换仅发生在1.5%的标记上(10% * 15%),所以这不会折损模型的语言理解能力。
第二个弊端是使用一个MLM意味着每个batch中只有15%的标记会被预测,所以在与训练的时候收敛需要更多步。在5.3中我们会阐述MLM的收敛速度比从左至右的模型(预测每一个标记)慢,但是和MLM带来的巨大提升相比,这么做是值得的。
3.3.2 Task #2:Next Sentence Prediction
很多重要的下游任务如问答和自然语言推断(NLI)是基于两个句子之间的理解的,语言模型并不能直接捕获到这种关系。为了徐连可以理解句子关系的模型,我们预训练了一个可以从任何单语语料库中轻松产生的二值化的下句预测任务。特别的,当为每个预训练模型选择句子A和句子B时,50%的情况B就是A的下一句,50%的情况下时预料中随机选择的句子。比如:
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Lable = IsNext
Input = [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight ##less birds [SEP]
Lable = NotNext
我们对于NotNext的句子的选择时完全随机的,并且最终预训练模型在这个任务中会达到97%-98%的准确率。除了简单的优点外,我们将会在5.1中阐述这种任务的预训练模型对QA和NLI任务都很有好处。
3.4 预训练程序
预训练程序主要遵循现有的语言模型与训练文献。对于预训练语料我们把BooksCorpus(800M words)和EnglishWikipedia(2500M words)加在一起使用。对于维基的数据我们仅仅提取了文章部分忽略了列表,表格和头部信息。对于提取长的连续性序列,和使用句子级的文本如Billion Word Benchmark比使用篇章级的文本至关重要。
为了产生每一个训练的输入序列,我们从训练语料中采样了两个spans的文本,我们称之为"sentence",虽然一般情况下它比单个句子长的多。第一个句子嵌入为A,第二个句子嵌入B。50%的情况下B刚好是A的下一句,另外50%的情况下他是一个随机的句子。这样下局预测的任务就完成了。最终他们被采样总长度小于等于512的标记。LM遮盖被应用于WordPiece的标记化之后,标准的遮盖率是15%,对于不完整的词部m欸有特别考虑。
我们训练的batchsize是256个句子(256 sequence*512 tokens = 128000 token/batch),训练1,000,000步差不多是40个epochs超过3.3 billion的预料数据。我们使用了Adam优化器,学习率是1e-4, \beta_1=0.9,\beta_2=0.999 ,L2权重衰减是0.01,在前10,000步中学习率warmup,学习率是线性衰减的。所有层的dropout都是0.1,和OpenAI GPT一样,激活函数选择了gelu而不是标准的relu。训练的损失函数是mask LM的似然的平均值加上下据预测的似然。
BERT_{BASE} 的训练是在4个Pod配置的云TPU(总共16个TPU片)上进行的,每一词预训练花费4天完成。
3.5 调参法程序
对于序列级别的分类任务,BERT的调参是直接进行的,为了获得固定维度的输入序列表示,我们对输入的第一个标记使用了最终的隐藏状态(也就是转换器的输出),为了和特殊的[CLS]嵌入做匹配。我们把这个向量记住 C \in \mathbb{R}^{H} ,在调参过程中唯一的新加的参数是给分类层的 W \in \mathbb{R}^{K \times H} ,其中 K 是分类标签的数量。标签的概率 P \in \mathbb{R}^K 使用标准的softmax来计算, P = \rm softmax(\it CW^T) 。BERT所有的参数和W都或通过最大化正确标签的对数概率来调整。对于span-level和token-level的预测任务,上述的过程需要做轻微的修改,我们将在第四节给出详细的说明。
对于调参法,大部分模型的超参数在与训练模型中都是相同的,同样的batchsize,同样的learning rate,以及epochs数量。dropout的概率一直保持在0.1,超参数的优化是任务特定的,但我们发现以下的值在所有任务种豆表现得很好:
* Batch size: 16,32
* Learning rate(Adam):5e-5,3e-5,2e-5
* Number of epochs: 3, 4
我们也观察到在大的数据集中(比如100k+的标注训练数据)对超参数的选择的敏感度远低于小的训练集。参数调整非常快,所以去通过尽量的用更多的参数配置去选择在开发集上表现最好的模型是合理的。
3.6 BERT和OpenAI GPT的对比
现有的和BERT最有可比性的模型是OpenAI GPT,它在一个大的语料数据上使用了从左至右的Transformer LM。实际上,BERT很多设计上的决定都有意的选择的尽量和GPT相近仪表与两种方法可以最小限度的做对比。这里我们的核心观点是3.3节中提到的这两个新的预训练任务都使用了大量的经验上的提升,大师我们还是注意到这两者之间在如何训练上由一些其他的区别:
* GPT 是在BooksCorpus(800M words)上训练的,而BERT是在BookCorpus和Wikipedia上训练的
* GPT只在调参的时候引入了句子分隔符[SEP]和分类符[CLS],而BERT在与训练的时候就使用了,而且还使用了句子A/B嵌入。
* GPT训练了1M 步,一个batch size有32000词;BERT也是1M步,但是一个batch size有128000个词
* GPT在所有的调参实验中都使用了5e-5的学习率,而BERT对于不同的任务选择了在开发集上表现得最好的学习率
为了消除这些不同之处,我们在5.1中做了相关的实验,实验表明大部分的提升实际上来自于新的预训练任务而不是上述的这些因素。
4 实验
略...
最后老规矩,代码地址
