
自然语言处理中的Transformer和BERT

2018年马上就要过去,回顾深度学习在今年的进展,让人印象最深刻的就是谷歌提出的应用于自然语言处理领域的BERT解决方案,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(https://arxiv.org/abs/1810.04805)。BERT解决方案刷新了各大NLP任务的榜单,在各种NLP任务上都做到state of the art。这里我把BERT说成是解决方案,而不是一个算法,因为这篇文章并没有提出新的算法模型,还是沿用了之前已有的算法模型。BERT最大的创新点,在于提出了一套完整的方案,利用之前最新的算法模型,去解决各种各样的NLP任务,因此BERT这篇论文对于算法模型完全不做介绍,以至于在我直接看这篇文章的时候感觉云里雾里。但是本文中,我会从算法模型到解决方案,进行完整的诠释。本文中我会分3个部分进行介绍,第一部分我会大概介绍一下NLP的发展,第二部分主要讲BERT用到的算法,最后一部分讲BERT具体是怎么操作的。
一,NLP的发展
要处理NLP问题,首先要解决文本的表示问题。虽然我们人去看文本,能够清楚明白文本中的符号表达什么含义,但是计算机只能做数学计算,需要将文本表示成计算机可以处理的形式。最开始的方法是采用one hot,比如,我们假设英文中常用的单词有3万个,那么我们就用一个3万维的向量表示这个词,所有位置都置0,当我们想表示apple这个词时,就在对应位置设置1,如图1.1所示。这种表示方式存在的问题就是,高维稀疏,高维是指有多少个词,就需要多少个维度的向量,稀疏是指,每个向量中大部分值都是0。另外一个不足是这个向量没有任何含义。

后来出现了词向量,word embedding,用一个低维稠密的向量去表示一个词,如图1.2所示。通常这个向量的维度在几百到上千之间,相比one hot几千几万的维度就低了很多。词与词之间可以通过相似度或者距离来表示关系,相关的词向量相似度比较高,或者距离比较近,不相关的词向量相似度低,或者距离比较远,这样词向量本身就有了含义。文本的表示问题就得到了解决。词向量可以通过一些无监督的方法学习得到,比如CBOW或者Skip-Gram等,可以预先在语料库上训练出词向量,以供后续的使用。顺便提一句,在图像中就不存在表示方法的困扰,因为图像本身就是数值矩阵,计算机可以直接处理。

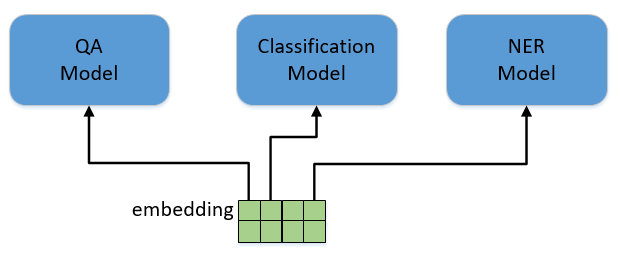
NLP中有各种各样的任务,比如分类(Classification),问答(QA),实体命名识别(NER)等。对于这些不同的任务,最早的做法是根据每类任务定制不同的模型,输入预训练好的embedding,然后利用特定任务的数据集对模型进行训练,如图1.3所示。这里存在的问题就是,不是每个特定任务都有大量的标签数据可供训练,对于那些数据集非常小的任务,恐怕就难以得到一个理想的模型。

我们看一下图像领域是如何解决这个问题的。图像分类是计算机视觉中最基本的任务,当我要解决一个小数据集的图像分类任务时,该怎么做?CV领域已经有了一套成熟的解决方案。我会用一个通用的网络模型,比如Vgg,ResNet或者GoogleNet,在ImageNet上做预训练(pre-training)。ImageNet有1400万张有标注的图片,包含1000个类别,这样的数据规模足以训练出一个规模庞大的模型。在训练过程中,模型会不断的学习如何提取特征,底层的CNN网络结构会提取边缘,角,点等通用特征,模型越往上走,提取的特征也越抽象,与特定的任务更加相关。当完成预训练之后,根据我自己的分类任务,调整最上层的网络结构,然后在小数据集里对模型进行训练。在训练时,可以固定住底层的模型参数只训练顶层的参数,也可以对整个模型进行训练,这个过程叫做微调(fine-tuning),最终得到一个可用的模型。总结一下,整个过程包括两步,拿一个通用模型在ImageNet上做预训练(pre-training),然后针对特定任务进行微调(fine-tuning),完美解决了特定任务数据不足的问题。还有一个好处是,对于各种各样的任务都不再需要从头开始训练网络,可以直接拿预训练好的结果进行微调,既减少了训练计算量的负担,也减少了人工标注数据的负担。
NLP领域也引入了这种做法,用一个通用模型,在非常大的语料库上进行预训练,然后在特定任务上进行微调,BERT就是这套方案的集大成者。BERT不是第一个,但目前为止,是效果最好的方案。BERT用了一个已有的模型结构,提出了一整套的预训练方法和微调方法,我们在后文中再进行详细的描述。
二,算法
BERT所采用的算法来自于2017年12月份的这篇文章,Attenion Is All You Need(https://arxiv.org/abs/1706.03762),同样来自于谷歌。这篇文章要解决的是翻译问题,比如从中文翻译成英文。这篇文章完全放弃了以往经常采用的RNN和CNN,提出了一种新的网络结构,即Transformer,其中包括encoder和decoder,我们只关注encoder。这篇英文博客(https://jalammar.github.io/illustrated-transformer/)对Transformer介绍得非常详细,有兴趣的读者可以看一下,如果不想看英文博客也可以看本文,本文中的部分图片也截取自这篇博客。

图2.1是Transformer encoder的结构,后文中我们都简称为Transformer。首先是输入word embedding,这里是直接输入一整句话的所有embedding。如图2.1所示,假设我们的输入是Thinking Machines,每个词对应一个embedding,就有2个embedding。输入embedding需要加上位置编码(Positional Encoding),为什么要加位置编码,后文会做详细介绍。然后经过一个Multi-Head Attention结构,这个结构是算法单元中最重要的部分,我们会在后边详细介绍。之后是做了一个shortcut的处理,就是把输入和输出按照对应位置加起来,如果了解残差网络(ResNet)的同学,会对这个结构比较熟悉,这个操作有利于加速训练。然后经过一个归一化normalization的操作。接着经过一个两层的全连接网络,最后同样是shortcut和normalization的操作。可以看到,除了Multi-Head Attention,都是常规操作,没有什么难理解的。这里需要注意的是,每个小模块的输入和输出向量,维度都是相等的,比如,Multi-Head Attention的输入和输出向量维度是相等的,否则无法进行shortcut的操作;Feed Forward的输入和输出向量维度也是相等的;最终的输出和输入向量维度也是相等的。但是Multi-Head Attention和Feed Forward内部,向量维度会发生变化。
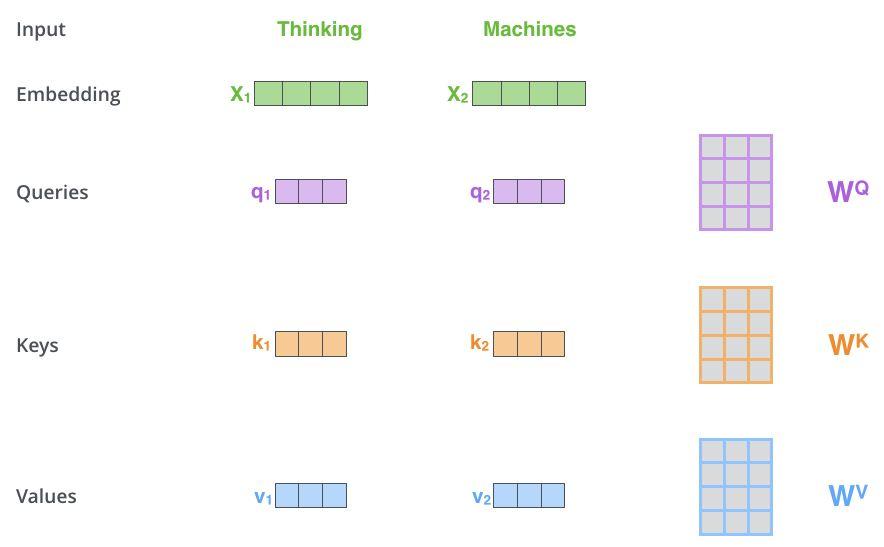
我们来详细看一下Multi-Head Attention的结构。这个Multi-Head表示多头的意思,先从最简单的看起,看看单头Attention是如何操作的。从图2.1的橙色方块可以看到,embedding在进入到Attention之前,有3个分叉,那表示说从1个向量,变成了3个向量。具体是怎么算的呢?我们看图2.3,定义一个WQ矩阵(这个矩阵随机初始化,通过训练得到),将embedding和WQ矩阵做乘法,得到查询向量q,假设输入embedding是512维,在图3中我们用4个小方格表示,输出的查询向量是64维,图3中用3个小方格以示不同。然后类似地,定义WK和WV矩阵,将embedding和WK做矩阵乘法,得到键向量k;将embeding和WV做矩阵乘法,得到值向量v。对每一个embedding做同样的操作,那么每个输入就得到了3个向量,查询向量,键向量和值向量。需要注意的是,查询向量和键向量要有相同的维度,值向量的维度可以相同,也可以不同,但一般也是相同的。

接下来我们计算每一个embedding的输出,以第一个词Thinking为例,参看图2.4。用查询向量q1跟键向量k1和k2分别做点积,得到112和96两个数值。这也是为什么前文提到查询向量和键向量的维度必须要一致,否则无法做点积。然后除以常数8,得到14和12两个数值。这个常数8是键向量的维度的开方,键向量和查询向量的维度都是64,开方后是8。做这个尺度上的调整目的是为了易于训练。然后把14和12丢到softmax函数中,得到一组加和为1的系数权重,算出来是大约是0.88和0.12。将0.88和0.12对两个值向量v1和v2做加权求和,就得到了Thinking的输出向量z1。类似的,可以算出Machines的输出z2。如果一句话中包含更多的词,也是相同的计算方法。
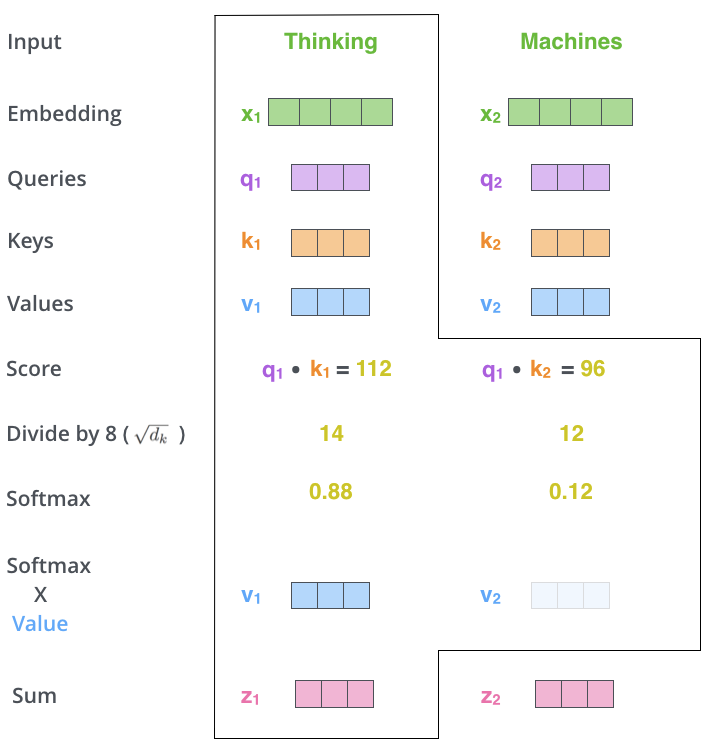

通过这样一系列的计算,可以看到,现在每个词的输出向量z都包含了其他词的信息,每个词都不再是孤立的了。而且每个位置中,词与词的相关程度,可以通过softmax输出的权重进行分析。如图2.5所示,这是某一次计算的权重,其中线条颜色的深浅反映了权重的大小,可以看到it中权重最大的两个词是The和animal,表示it跟这两个词关联最大。这就是attention的含义,输出跟哪个词关联比较强,就放比较多的注意力在上面。上面我们把每一步计算都拆开了看,实际计算的时候,可以通过矩阵来计算,如图2.6所示。



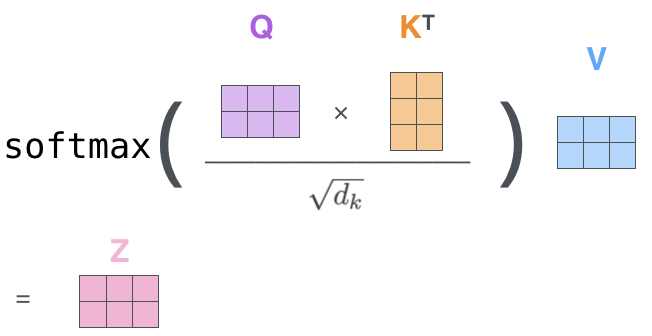

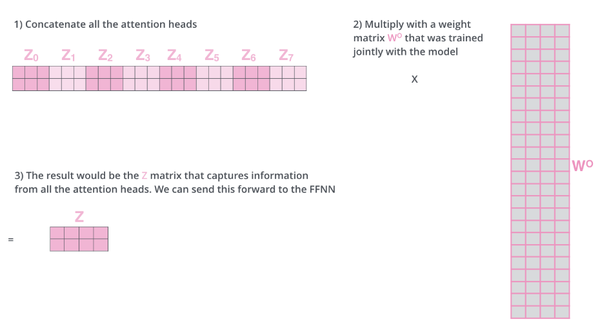
讲完了attention,再来讲Multi-Head。对于同一组输入embedding,我们可以并行做若干组上面的操作,例如,我们可以进行8组这样的运算,每一组都有WQ,WK,WV矩阵,并且不同组的矩阵也不相同。这样最终会计算出8组输出,我们把8组的输出连接起来,并且乘以矩阵WO做一次线性变换得到输出,WO也是随机初始化,通过训练得到,计算过程如图2.7所示。这样的好处,一是多个组可以并行计算,二是不同的组可以捕获不同的子空间的信息。

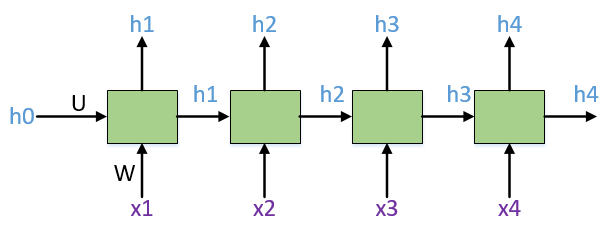
到这里就把Transformer的结构讲完了,同样都是做NLP任务,我们来和RNN做个对比。图2.8是个最基本的RNN结构,还有计算公式。当计算隐向量h4时,用到了输入x4,和上一步算出来的隐向量h3,h3包含了前面所有节点的信息。h4中包含最多的信息是当前的输入x4,越往前的输入,随着距离的增加,信息衰减得越多。对于每一个输出隐向量h都是如此,包含信息最多得是当前的输入,随着距离拉远,包含前面输入的信息越来越少。但是Transformer这个结构就不存在这个问题,不管当前词和其他词的空间距离有多远,包含其他词的信息不取决于距离,而是取决于两者的相关性,这是Transformer的第一个优势。第二个优势在于,对于Transformer来说,在对当前词进行计算的时候,不仅可以用到前面的词,也可以用到后面的词。而RNN只能用到前面的词,这并不是个严重的问题,因为这可以通过双向RNN来解决。第三点,RNN是一个顺序的结构,必须要一步一步地计算,只有计算出h1,才能计算h2,再计算h3,隐向量无法同时并行计算,导致RNN的计算效率不高,这是RNN的固有结构所造成的,之前有一些工作就是在研究如何对RNN的计算并行化。通过前文的介绍,可以看到Transformer不存在这个问题。通过这里的比较,可以看到Transformer相对于RNN有巨大的优势,因此我看到有人说RNN以后会被取代。

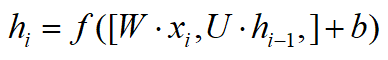
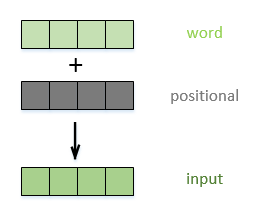
关于上面的第三点优势,可能有人会不认可,RNN的结构包含了序列的时序信息,而Transformer却完全把时序信息给丢掉了。为了解决时序的问题,Transformer的作者用了一个绝妙的办法,这就是我在前文提到的位置编码(Positional Encoding)。位置编码是和word embedding同样维度的向量,将位置embedding和词embedding加在一起,作为输入embedding,如图2.9所示。位置编码可以通过学习得到,也可以通过设置一个跟位置或者时序相关的函数得到,比如设置一个正弦或者余弦函数,这里不再多说。
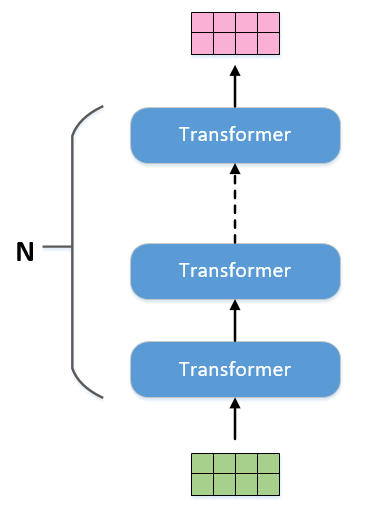
我们把图2.1的结构作为一个基本单元,把N个这样的基本单元顺序连起来,就是BERT的算法模型,如图2.10所示。从前面的描述中可以看到,当输入有多少个embedding,那么输出也就有相同数量的embedding,可以采用和RNN采用相同的叫法,把输出叫做隐向量。在做具体NLP任务的时候,只需要从中取对应的隐向量作为输出即可。
三,BERT
在介绍BERT之前,我们先看看另外一套方案。我在第一部分说过,BERT并不是第一个提出预训练加微调的方案,此前还有一套方案叫GPT,这也是BERT重点对比的方案,文章在这,Improving Language Understanding by Generative Pre-Training(https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)。GPT的模型结构和BERT是相同的,都是图2.10的结构,只是BERT的模型规模更加庞大。GPT是这么预训练的,在一个8亿单词的语料库上做训练,给出前文,不断地预测下一个单词。比如这句话,Winter is coming,当给出第一个词Winter之后,预测下一个词is,之后再预测下一个词coming。不需要标注数据,通过这种无监督训练的方式,得到一个预训练模型。
我们再来看看BERT有什么不同。BERT来自于Bidirectional Encoder Representations from Transformers首字母缩写,这里提到了一个双向(Bidirectional)的概念。BERT在一个33亿单词的语料库上做预训练,语料库就要比GPT大了几倍。预训练包括了两个任务,第一个任务是随机地扣掉15%的单词,用一个掩码MASK代替,让模型去猜测这个单词;第二个任务是,每个训练样本是一个上下句,有50%的样本,下句和上句是真实的,另外50%的样本,下句和上句是无关的,模型需要判断两句的关系。这两个任务各有一个loss,将这两个loss加起来作为总的loss进行优化。下面两行是一个小栗子,用括号标注的是扣掉的词,用[MASK]来代替。
正样本:我[MASK](是)个算法工程师,我服务于WiFi万能钥匙这家[MASK](公司)。
负样本:我[MASK](是)个算法工程师,今天[MASK](股票)又跌了。
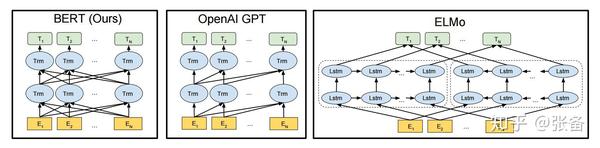
我们来对比下GPT和BERT两种预训练方式的优劣。GPT在预测词的时候,只预测下一个词,因此只能用到上文的信息,无法利用到下文的信息。而BERT是预测文中扣掉的词,可以充分利用到上下文的信息,这使得模型有更强的表达能力,这也是BERT中Bidirectional的含义。在一些NLP任务中需要判断句子关系,比如判断两句话是否有相同的含义。BERT有了第二个任务,就能够很好的捕捉句子之间的关系。图3.1是BERT原文中对另外两种方法的预训练对比,包括GPT和ELMo。ELMo采用的还是LSTM,这里我们不多讲ELMo。这里会有读者困惑,这里的结构图怎么跟图2.10不一样?如果熟悉LSTM的同学,看到最右边的ELMo,就会知道那些水平相连的LSTM其实只是一个LSTM单元。左边的BERT和GPT也是一样,水平方向的Trm表示的是同一个单元,图中那些复杂的连线表示的是词与词之间的依赖关系,BERT中的依赖关系既有前文又有后文,而GPT的依赖关系只有前文。

讲完了这两个任务,我们再来看看,如何表达这么复杂的一个训练样本,让计算机能够明白。图3.2表示“my dog is cute, he likes playing.”的输入形式。每个符号的输入由3部分构成,一个是词本身的embedding;第二个是表示上下句的embedding,如果是上句,就用A embedding,如果是下句,就用B embedding;最后,根据Transformer模型的特点,还要加上位置embedding,这里的位置embedding是通过学习的方式得到的,BERT设计一个样本最多支持512个位置;将3个embedding相加,作为输入。需要注意的是,在每个句子的开头,需要加一个Classification(CLS)符号,后文中会进行介绍,其他的一些小细节就不说了。


完成预训练之后,就要针对特定任务就行微调了,这里描述一下论文中的4个例子,看图3.4。首先说下分类任务,分类任务包括对单句子的分类任务,比如判断电影评论是喜欢还是讨厌;多句子分类,比如判断两句话是否表示相同的含义。图3.4(a)(b)是对这类任务的一个示例,左边表示两个句子的分类,右边是单句子分类。在输出的隐向量中,取出CLS对应的向量C,加一层网络W,并丢给softmax进行分类,得到预测结果P,计算过程如图3.3中的计算公式。在特定任务数据集中对Transformer模型的所有参数和网络W共同训练,直到收敛。新增加的网络W是HxK维,H表示隐向量的维度,K表示分类数量,W的参数数量相比预训练模型的参数少得可怜。
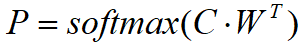
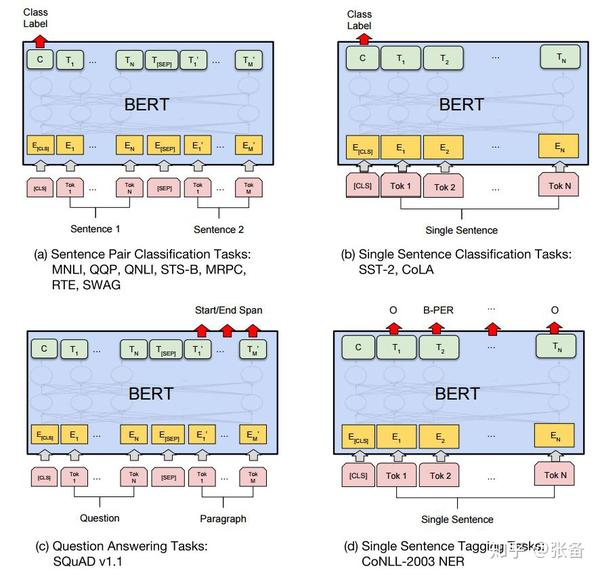

我们再来看问答任务,如图3.4(c),以SQuAD v1.1为例,给出一个问题Question,并且给出一个段落Paragraph,然后从段落中标出答案的具体位置。需要学习一个开始向量S,维度和输出隐向量维度相同,然后和所有的隐向量做点积,取值最大的词作为开始位置;另外再学一个结束向量E,做同样的运算,得到结束位置。附加一个条件,结束位置一定要大于开始位置。最后再看NER任务,实体命名识别,比如给出一句话,对每个词进行标注,判断属于人名,地名,机构名,还是其他。如图3.4(d)所示,加一层分类网络,对每个输出隐向量都做一次判断。可以看到,这些任务,都只需要新增少量的参数,然后在特定数据集上进行训练即可。从实验结果来看,即便是很小的数据集,也能取得不错的效果。
