word2vec详解(CBOW,skip-gram,负采样,分层Softmax)

本文翻译自Xin Rong的《word2vec Parameter Learning Explained》,是一篇非常优秀的英文论文。文章介绍了两种基本模型:CBOW和Skip-Gram模型的原理和求导的细节,之后介绍了优化模型的方法:分层softmax和负采样技术。是理解word2vec的非常好的资料。
1 连续词袋模型(CBOW)
- 单个上下文情境
我们先来介绍CBOW模型中最简单的一个版本。假定每一上下文只有一个单词,也就是模型通过给定一个上下文单词来预测一个目标单词,就好比一个二元模型。对不了解神经网络的同学,强烈建议先快速阅读一下附录A以便了解基本的概念和技术要领。
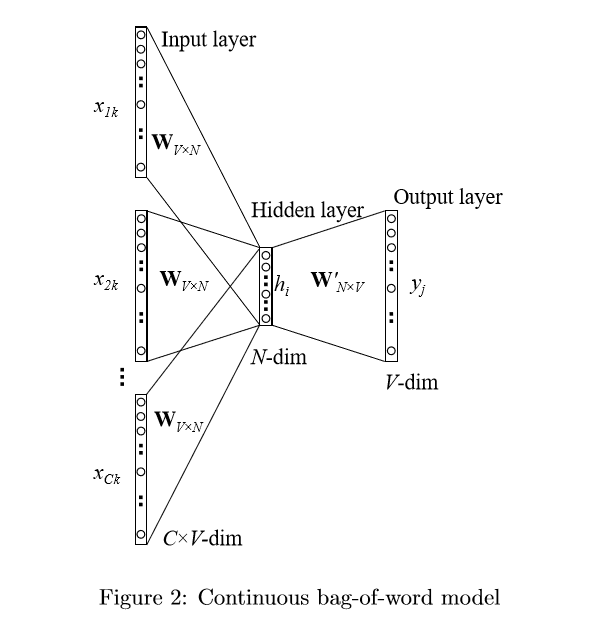
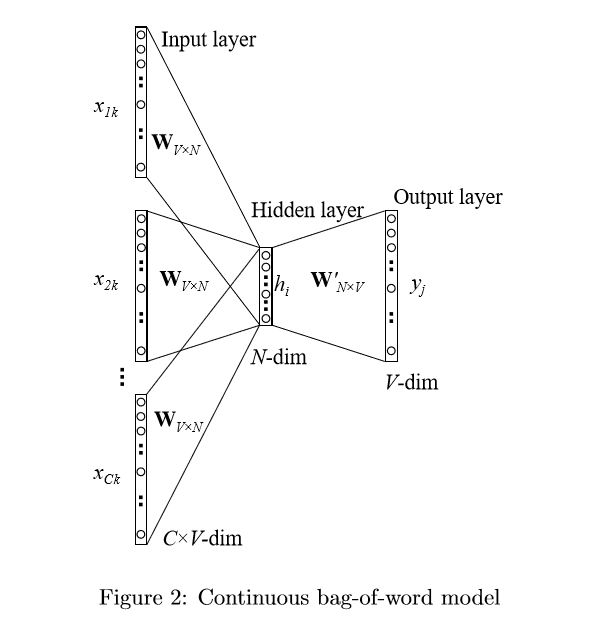
图 1 展示了该简化版模型的神经网络结构。根据我们的设定,模型词汇表的大小是V,每个隐藏层的维度是N。相邻的神经元之间的连接方式是全连接。
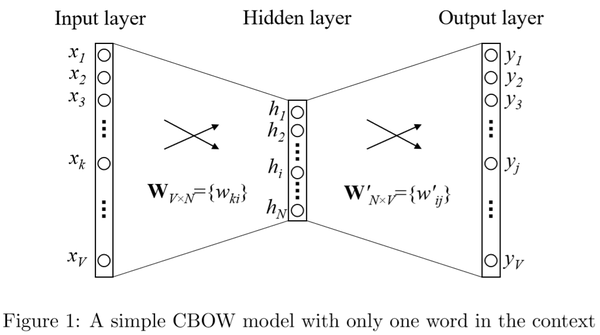

模型的输入是一个独热(one-hot)向量,这意味着对于给定的一个单词,\left\{ x1,…,xV\right\} 这个序列中只有一个值为1,其他值都为0。输入层和隐藏层之间的权重矩阵可以用一个 V\times N 的矩阵W来表示。W的每一行是一个与模型输入相对应的N维向量 v_{w} ,经过转置,矩阵的第i行就是 v_{w}^{T} 。给定一上下文(也就是一个单词),假定输入序列中x_{k}^{} = 1和 x_{k}^{'}=0 (对所有的 x_{k}^{'}\ne x_{k} ),可以得到:
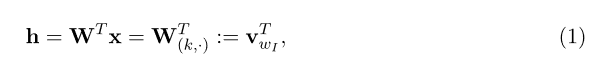

也就是直接复制W矩阵第k行赋给h, v_{wi} 是输入单词wi的向量表示。这表明隐藏层单元的激活函数是简单的线性关系(也就是传递输入向量的加权和给下一层)。
隐藏层和输出层之间,存在一个不同的矩阵 W^{’} ,该矩阵的维度是 N\times V 。有了这些权重,我们可以计算出词汇表中每个单词 u_{j} 的得分:


v_{wj}^{'} 是矩阵 W^{'} 的第j列。现在可以用softmax,一种对数线性分类模型,去得到单词的后验分布,它是一种多项式分布。
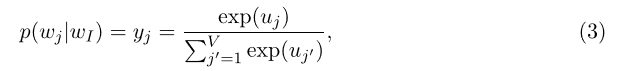

y_{j} 是输出向量中第j个单元。把式(1)和式(2)带入式(3),可得:
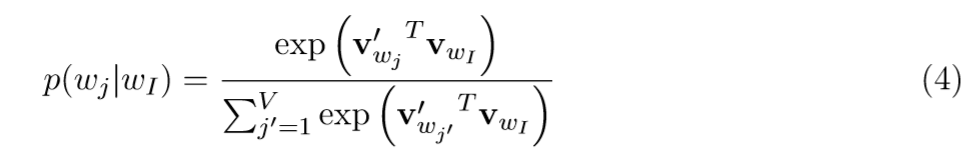

注意一点, v_{w} 和 v_{w}^{'} 是对单词w的两种不同的向量表示。 v_{w} 来自于矩阵W的行向量,也就是输入层 \rightarrow隐藏层的权重矩阵, v_{w}^{’} 来自于矩阵 的列向量,也就是隐藏层 \rightarrow 输出层的权重矩阵。以下,我们将 v_{w} 称为单词w的输入向量, v_{w}^{'} 称为单词w的输出向量。(补充一下,这两类向量,有的文章中也叫做中心词向量和上下文向量)
隐藏层 \rightarrow 输出层权重的更新公式
现在我们来推导一下该模型的权重更新公式。尽管该公式实际计算中并不可行(下面会具体解释原因),我们将直接使用这个原始模型(不加任何优化技巧)来演绎一下推导过程以增加对该模型的理解。对于反向传播的一些基础概念,可以参考附录A。
该模型的训练目标是最大化公式(4),给定输入wi下真实输出值 w_{O} 的条件概率(正确输出单词的索引是 j^{*} )。
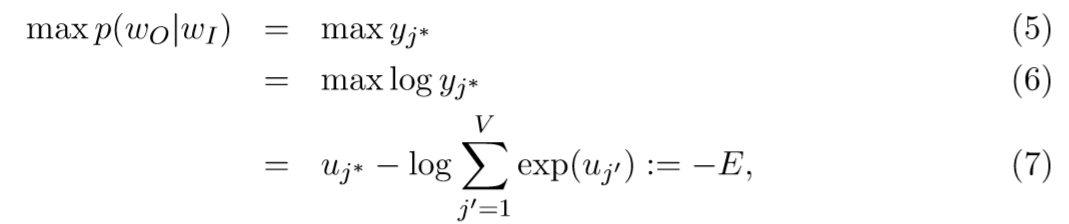

损失函数 E=-log P(w_{O}| w_{I}) (我们的目标是最小化 E), j^{*} 是真实输出值的索引。该损失函数可以理解为一种特殊的衡量两个概率分布的交叉熵形式。
现在我们来求解隐藏层和输出层权重更新方程,求E对求 u_{j} 的偏导,可得:


当 j=j^{*} 时, t_{j} =1,否则为0。可以看出,这个结果恰好等于预测误差 e_{j} 。
接下来我们对 w_{ij}^{'} 求偏导,得到隐藏层 \rightarrow 输出层权重的梯度:
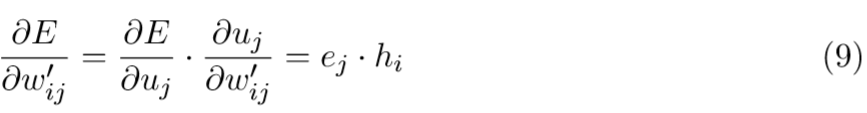

因此,使用随机梯度下降的方法,我们可以得到隐藏层 \rightarrow 输出层的权重更新公式:
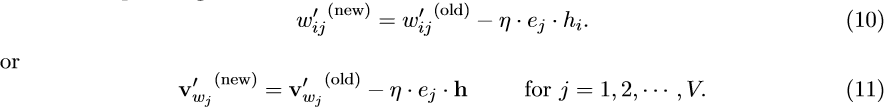

学习率 \eta >0 , e_{j}=y_{j}-t_{j} , h_{j} 是隐藏层的第j个单元; v_{wj}^{'} 是单词 w_{j} 的输出向量。注意到该更新公式意味着我们必须遍历词汇表中的所有单词来才能得到输出值 y_{j} ,再将 y_{j} 和期望输出 t_{j} (0或1)进行比对。如果 y_{j}>t_{j} (结果估计过高),那么我们让 v_{wj}^{'} 减去一定比例的隐向量h(也就是 v_{wi} ),这样使得向量v_{wj}^{'} 更加远离向量 v_{wi};如果y_{j}<t_{j}(结果被低估,仅当 t_{j} =1时发生的情况,此时 w_{j}=w_{O} ),我们加上一定比例的h给 v_{wo}^{'} ,使得v_{wo}^{'}更接近于v_{wi}^{'}。如果y_{j}和t_{j}非常接近,根据公式,权重的更新值也会很小。再次提醒,输入向量 v_{w} 和输出向量 v_{w}^{'} 是对同一个单词w的两种不同的表达。
输入层 \rightarrow 隐藏层权重的更新公式
有了 W^{'} 的更新公式,我们继续求解W的更新公式。我们求E对 h_{i} 的偏导,得到:
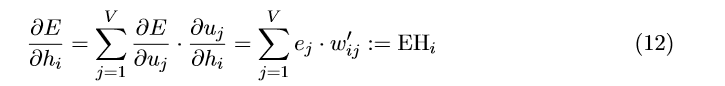

h_{i}是隐藏层第i个单元的输出;根据公式(2)的定义, u_{j}是输出层的第j个输入;e_{j}=y_{j}-t_{j}是输出层第j个单词的预测误差。EH是一个N维向量,是词汇表所有单词的输出向量根据预测误差的加权求和。
接下来,我们来求E对输入权重矩阵W的偏导。首先,让我们回忆一下,隐藏层是对输入层的值的线性计算过程。把公式(1)展开得到:


现在我们可以对W的各元素进行求导,得到:
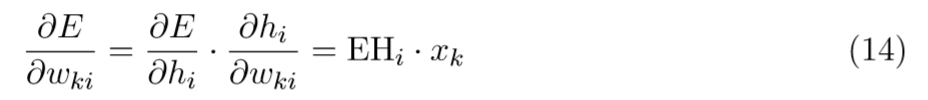

这和x和EH的张量计算输出等价,


我们最终得到了一个V*N的矩阵。因为x向量中只有一个元素是非0的,所有 \partial E/\partial W
矩阵中只有一行是非0,该行的值为EH(x的值为1),是一个N维向量。所以最终W的更新公式为:


v_{wi} 是唯一上下文单词的输入向量,也是W矩阵的导数中唯一为非0的一行。W矩阵的其他行在迭代过程中均保持不变,因为他们的导数都为0.
直观的来理解一下这个过程,由于EH向量是词汇表中所有单词的输出向量根据预测误差e_{j}=y_{j}-t_{j}的加权求和。我们可以这样理解公式(16),将输出向量的一部分加到上下文单词的输入向量中去。如果在输出层,单词 w_{j} 作为预测单词的概率被高估(y_{j}>t_{j}),那么上下文单词wi的输入向量趋向于远离w_{j}的输出向量;相反的,如果单词w_{j}作为预测单词的概率被低估(y_{j}<t_{j}),那么上下文单词wi的输入向量将趋向于靠近w_{j}的输出向量;如果单词
w_{j}作为预测单词恰好等于真实值,那么上下文单词wi的输入向量将几乎没有什么改变。输入向量wi的变化情况取决于词汇表中所有单词向量的预测误差;误差越大,输入向量的变动越大。
由于在训练过程中,我们是通过训练语料中的上下文—目标单词对来迭代地更新模型参数,每次迭代更新对向量的影响也是累积的。我们可以想象成单词w的输出向量被w所有周围词的输入向量的来回往复的拖拽。就好比有真实的琴弦在单词w和其他词之间。同样的,输入向量也可以被想象成被很多输出向量拖拽。这种解释可以提醒我们想象成一个重力,或者其他力量所指引的输出图。每根弦的均衡长度跟共同出现的关联单词对之间的力量权衡有关,也跟学习率有关。经过多次迭代,输入和输出向量的相对位置将趋于平稳。
- 多个单词上下文情境
图2展示了多个上下文单词的CBOW模型。当计算隐藏层的输出时,CBOW并不是直接拷贝上下文的输入向量,而是对上下文单词的输入向量求均值后再作为输出。
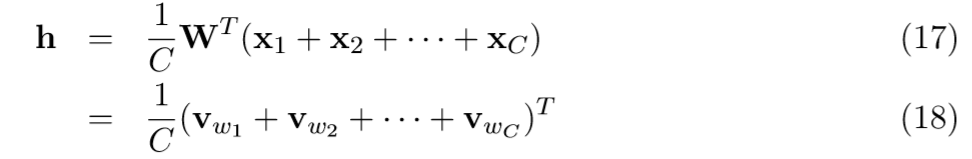

C是上下文的单词个数, w_{1}, \cdot\cdot\cdot,w_{C} 是上下文中的单词, v_{w} 是单词w的输入向量。损失函数定义为:
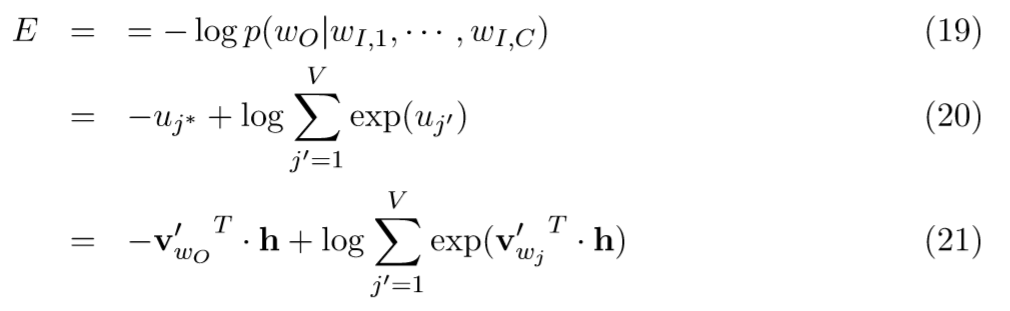

跟公式(7)一样,目标和one-word-context模型一致,除了h的定义不同,也就是将公式(18)替换公式(1)。
对于隐藏层 \rightarrow 输出层,梯度更新公式跟one-word-context模型一致。直接拷贝公式如下:
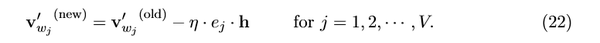

注意一点在训练过程中我们需要把该公式迭代作用于输出矩阵的每个元素。对于输入层 \rightarrow 隐藏层,梯度更新公式和式(16)类似,除了现在需要将如下公式作用于上下文词的每个单词 w_{I,c} :
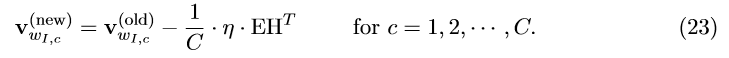

w_{I,c}是上下文中第c个单词的输入向量; \eta 是学习率;可EH由公式(12)得到。对更新公式的直观理解可以参考(16)。
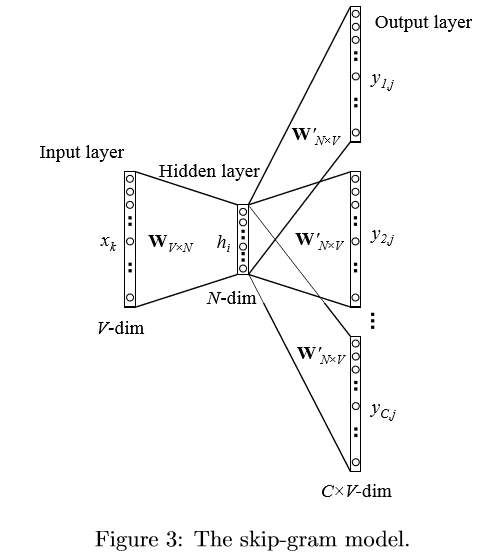
- Skip-Gram Model
Skip-gram模型是由Mikolov等人提出的。图3展示了skip-gram模型的过程。该模型可以看做是CBOW模型的逆过程。CBOW模型的目标单词在该模型中作为输入,上下文则作为输出。
我们仍然使用 v_{wi} 来表示输入层中唯一单词(也叫中心词)的输入向量,所以这样的话,对隐藏层h的定义跟公式(1)一致,意味着h仅仅只是简单拷贝了输入层 \rightarrow 隐藏层的权重矩阵W
中跟输入单词wi相关的那一行。拷贝公式得到:


在输出层,我们输出C个多项式分布来替代仅输出一个多项式分布。每个输出是由同一个隐藏层 \rightarrow 输出层矩阵计算得出的:


这里 w_{c,j} 是第c个输出面上第j个单词;w_{O,c}是中心词对应的目标单词中的第c个单词;wi是中心词(唯一输入单词);y_{c,j}是第c个输出面上第j个单元的输出值;u_{c,j}是第c个输出面上的第j个单元的输入。因为输出面共享同一权重矩阵,所以有:
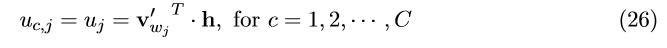

v_{wj}^{'} 是词汇表第j个单词的输出向量,可由 W^{'} zsssss1s1阵中的所对应的一列拷贝得到。

模型参数的更新过程和one-word-context模型基本一致。损失函数更改为:
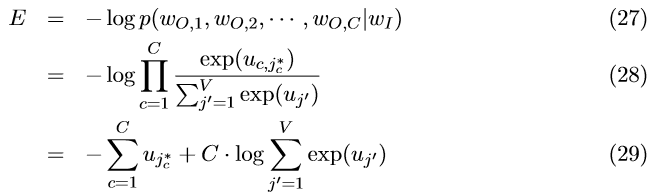

j_{c}^{*}是词汇表中第c个真实输出单词的索引。我们求E对u_{cj}^{}的偏导,得到:
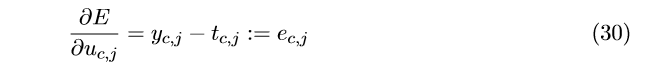

跟公式(8)一致,这个就是该单元的预测误差。为了方便表示,我们定义一个V维向量 EI=\left\{ EI_{1} ,\cdot\cdot\cdot, EI_{V}\right\} ,该向量是C个预测单词的误差总和:


接下来,我们作E对 W^{'} (隐藏层 \rightarrow 输出层的权重矩阵)的偏导,可得:
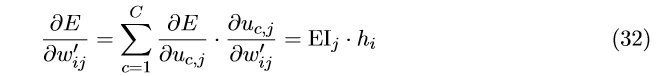

这样我们得到了隐藏层到输出层矩阵W^{'}的梯度更新公式,
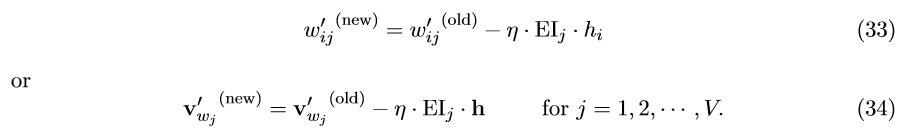

直观上对该公式的理解跟(11)一样,除了预测误差是对输出层所有上下文词的误差总和。
对输入层 \rightarrow 隐藏层的权重更新跟(12)和(16)一致,除了需要将预测误差e_{j}^{}替换为EI_{j}^{},直接给出更新公式:
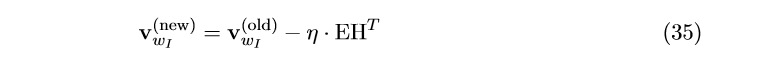

EH是一个N维向量,向量每个单元被定义为:


直觉上的理解和(16)一致。
- 模型的优化方法
以上我们讨论的模型(二元模型,CBOW和skip-gram)都是他们的原始形式,没有加入任何优化技巧。
对于这些模型,每个单词存在两类向量表达:输入向量v_{w}^{},输出向量v_{w}^{'}(这也是为什么word2vec的名称由来:1个单词对应2个向量表示)。学习得到输入向量比较简单;但要学习输出向量是很困难的。从公式(22)和(33)得知,为了更新v_{w}^{'},在每次训练中,我们必须遍历词汇表中的每个单词w_{j}^{},从而计算得到 u_{j}^{},预测概率y_{j}^{}(skip-gram为y_{c,j}^{}),它们的预测误差e_{j}^{},(skip-gram为EI_{j}^{}),然后再用误测误差来更新输出向量v_{j}^{'}。
对每个训练过程做如此庞大的计算是非常昂贵的,使得它难以扩展到词汇表或者训练样本很大的任务中去。为了解决这个问题,我们直观的想法就是限制每次必须更新的输出向量的数量。一种有效的手段就是采用分层softmax;另一种可行的方法是通过负采样。
这两种技巧都只针对输出向量更新的优化。在我们的推导过程中,我们关心三种值:(1)
E,新的目标函数;(2) \partial E/\partial v_{w}^{'} ,新的输出向量的更新公式;(3)\partial E/\partial h_{}^{},反向传播中用于更新输入向量的预测误差的加权和。
3.1分层softmax
分层softmax是计算softmax问题的一种有效的方法。该模型用二叉树来表示词汇表中的所有单词。
V个单词必须存储于二叉树的叶子单元。可以被证明一共有V-1个内单元。对于每个叶子节点,有一条唯一的路径可以从根节点到达该叶子节点;该路径被用来计算该叶子结点所代表的单词的概率。参考图4:
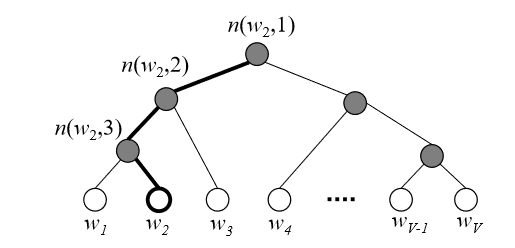

图4:用于分层softmax的二叉树示例。白色节点表示词汇表中的所有单词,黑色节点表示隐节点。从根节点到单词 w_{2}
的路径被加粗表示出,在这个例子中,该路径的长度
L(w_{2}) = 4。n(w,j)表示从根节点到单词的路径的第 j 个节点。分层softmax模型没有单词的输出向量,取而代之的是, V-1 中每个隐节点都有一个输出向量 v_{n(w,j)}^{'} 。一个单词作为输出词的概率被定义为:
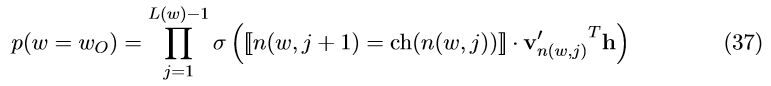

ch(n) 是节点 n 的左侧子节点;v_{n(w,j)}^{'}是隐节点 n(w,j) 的向量表示(“输出向量”); h 是隐藏层的输出值(skip-gram模型中,h= v_{wi} ;CBOW模型中,h= 1/C\sum_{c=1}^{C}{v_{w_{c}}} );
[[x]] 是一个特殊的函数,定义如下:
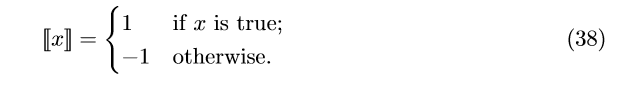

让我们通过一个例子来直观上理解一下这个公式。看图4,假如我们想要计算w_{2} 作为输出单词的概率。我们将这个概率定义为问题中从根节点出发到叶子结点的随机路径。在每个隐节点(包含根节点),我们需要分配往左走或往右走的概率。我们定义在当前隐节点 n 往左走的概率为:


它是由隐节点向量和隐藏层输出值( h ,也就是输入单词的向量表示)共同决定。容易得到,从隐节点 n 往右走的概率为:
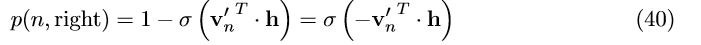

如图4,沿着从根节点到单词w_{2}的路径,我们可以计算w_{2}是输出单词的概率为:
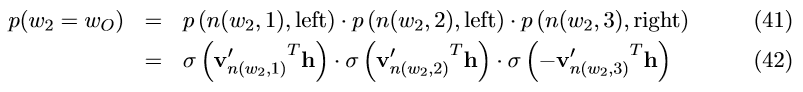

也就是公式(37)。不难看出:


这使得分层softmax模型是一个的关于所有单词的良好定义的多分类分布。
现在我们来推导隐节点向量的参数更新公式。为了简化,我们先从one-word-context模型开始。再扩展到CBOW和skip-gram模型就会很容易了。为了表达简单,我们使用下面的简化公式:
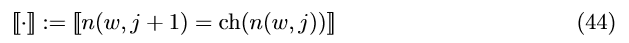



对于训练过程,我们将误差函数定义为:
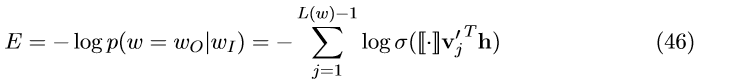

我们作E对 v_{j}^{'}h 的偏导,可得:
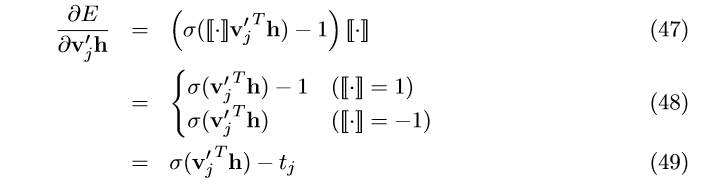

当 [[\bullet]] =1时, t_{j}= 1,当[[\bullet]]=-1时,t_{j}= 0。
接下来我们求 E 对隐节点 n(w,j) 的偏导,可得:
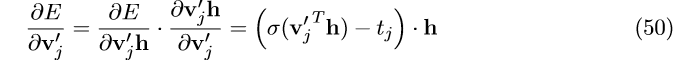

最终我们的梯度更新公式为:
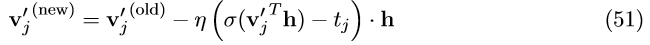

该公式会从 j=1,2,\cdot\cdot\cdot, L(w)-1 依次迭代。我们可以将 \sigma(v_{j}^{'T}h_{})-t_{j} 理解隐节点
n(w,j) 的预测误差。对每个隐节点来说,他们的任务就是预测下一步是该往左侧子节点走,还是往右侧子节点走。 t_{j}=1 表示实际路径是往左;t_{j}=0表示实际路径是往右。
\sigma(v_{j}^{'T}h_{})表示预测结果。对于训练数据来说,如果对隐节点的预测结果和真实路径非常相似,那么它的向量 v_{j}^{'} 只需要微小的改动;否则,向量v_{j}^{'}就会按适当的方向进行调整(要么靠近,要么远离 h )来减少预测误差。这个更新公式既可以用于CBOW模型,也可以用于skip-gram模型。当用于skip-gram模型时,需要对输出的C个单词中的每个词重复这个更新过程。
我们通过对 E 求 h 的偏导来看误差在输入层 \rightarrow 隐藏层的反向传播过程:
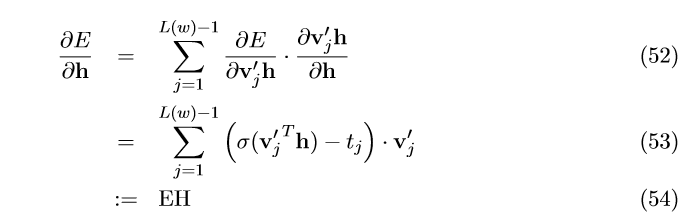

这个结果可以直接带入公式(23)来求得CBOW模型的输入向量的更新公式。对于skip-gram模型,我们可以计算窗口的每个单词的 EH 值,对这些 EH 值加和后再带入公式(35)来得到输入向量的更新公式。
从更新公式可以看出,训练模型的计算复杂度从 O(V) 降至 O(logV) ,这在效率上是一个巨大的提升。而且我们仍然有差不多同样的模型参数(原始模型: V 个单词的输出向量,分层softmax: V-1 个隐节点的输出向量)。
3.2 负采样技术
相比分层softmax,负采样的思想更加直观:为了解决数量太过庞大的输出向量的更新问题,我们就不更新全部向量,而只更新他们的一个样本。
显然正确的输出单词(也就是正样本)应该出现在我们的样本中,另外,我们需要采集几个单词作为负样本(因此该技术被称为“负采样”)。采样的过程需要指定总体的概率分布,我们可以任意选择一个分布。我们把这个分布叫做噪声分布,标记为 P_{n}(w) 。可以凭经验选择一个好的分布。
在word2vec中,作者称用简化的训练目标取代用一个定义好的后多项分布的负采样形式,也能够产生高质量的词嵌入:
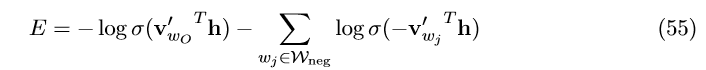

w_{O} 是输出单词(即,正样本), v_{wo}^{'} 是它的词向量; h 是隐藏层的输出:在CBOW中,
h= 1/C\sum_{c=1}^{C}{v_{w_{c}}},在skip-gram中, h=v_{wi} ; W_{neg}=\left\{ w_{j} |j=1,\cdot\cdot\cdot, K\right\} 是 从
P_{n}(w) 中采样得到的单词集合,也就是负样本。
为了得到基于负采样的词向量的更新公式,我们首先求 E 对输出单元 w_{j}
的网络输入的偏导:
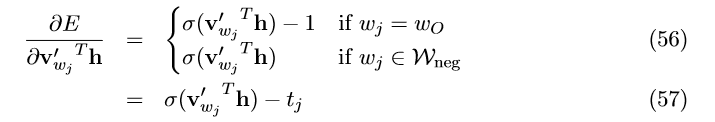

t_{j}是单词w_{j}的标签。t=1时, w_{j}是正样本;t=0时,w_{j}为负样本。
接下来我们求 E 对单词w_{j}的输出向量求偏导,
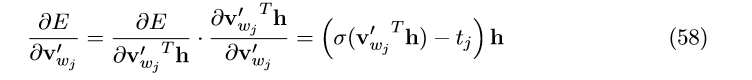

由此可以得到输出向量的更新公式:
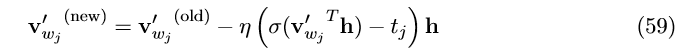

只需要将此公式作用于 w_{j}\in\left\{ w_{O} \right\}\cup W_{neg} 而不用更新词汇表的所有单词。这也解释了为什们我们可以在一次迭代中节省巨大的计算量。
直觉上对该更新公式的理解和公式(11)一致。该公式可以通用于CBOW模型和skip-gram模型。对于skip-gram模型,我们一次作用于一个上下文单词。
为了使误差反向传播到隐藏层来更新单词的输入向量,我们求 E 对隐藏层输出 h 的偏导:
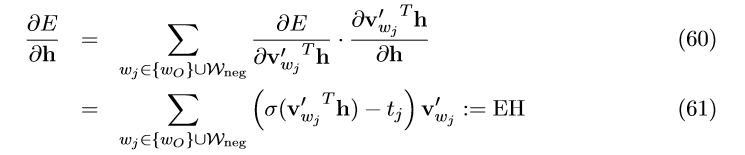

把 EH 带入公式(23)可得CBOW模型的输入向量的更新公式。对于skip-gram模型,我们计算每个单词的EH值并加和再带入公式(35)就可得到输入向量的更新公式。
附录
没有翻译,可以参考原文~~~

