4.2 —— 策略改进(Policy Improvement)

一些补充
在讨论策略改进(Policy Improvement)之前,我先来对上一节内容做一点点补充说明~
1. DP的收敛性质
上一节提到在continuing tasks中,只要 \gamma<1 ,我们可以通过Banach不动点定理证明价值函数经过以Bellman equation形式构造的迭代会收敛。细想一下,上一节粗略的诸多描述中存在一些不妥,于是放到这一节做一些修补~
首先证明过程中所需的定理并不要求是建立在Banach空间上,完备的度量空间上就OK了,显然前者更强一些。因为压缩映射的定义中缩放的目标是度量空间中的两个点,而度量并不需要满足范数所包含的线性性质。其次,Banach不动点定理声明了这样一件事情:
定理 完备度量空间上的压缩映射具有唯一的不动点
从定理可以看出需要满足的两个条件:
- 建立在完备的度量空间上;
- 映射具有压缩性质。
那价值迭代的收敛性分析满不满足要求呢?是满足的~ 一般任务建立在N维欧式空间上,这是一个完备的度量空间。进一步地,如果我们对某一状态s,将其状态价值所满足的Bellman equation的右边作为Bellman operator T 的像,那么DP的迭代过程就是建立在具有压缩性质的Bellman operator T 上的,折扣因子 \gamma 的存在对迭代进行了压缩:
T^{\pi}(v_{\pi}(s))=\sum_{a\in A}\pi(a|s)\sum_{s',r}p(s',r|s,a)[r+\gamma v_{\pi}(s')]
由于PE是建立在状态空间上的,所以状态价值函数是一个向量值函数。所以之前建立在Banach空间上是合理的,只是说不动点定理不需要这么强的条件就是了~ 那么可定义空间上的度量 \rho(v_{\pi}(s),u_{\pi}(s))=||v_{\pi}(s)-u_{\pi}(s)|| ,这一点很自然。所以只要证明:
||T^{\pi}(v_{\pi}(s))-T^{\pi}(u_{\pi}(s))||\leq\gamma||v_{\pi}(s)-u_{\pi}(s)||
是成立的,就能说明Bellman operator是一个压缩映射,价值函数的DP更新会收敛到一个唯一的不动点。很明显,证明上式需要展开并进行放缩。所以在范数等价性的支持下,我们可以选择向量的无穷范数帮助我们更容易地完成放缩,而最终得到的结果正是:
||T^{\pi}(v_{\pi}(s))-T^{\pi}(u_{\pi}(s))||_{\infty}\leq\gamma max_{s\in S}||v_{\pi}(s)-u_{\pi}(s)||_{\infty}
那么我们就可以在理论保证下放心地进行价值函数的更新了!
2.“in place”更新具有更快的收敛速度
“in place”版本的更新相对于储存新旧两个array的更新的优势,和Gauss-Seidel迭代相对于Jacobi迭代的优势十分相似,取决于当前更新有没有用到已经更新过的变量。“in place”在更新某一状态价值时,存在使用已经更新过的下一状态的价值的可能性,那么也就自然地加快了收敛的进度。
Policy Improvement
之前的小问题总结完,现在来讨论当我们拿到当前policy \pi 对应的稳定的价值函数之后,如何基于此进行policy improvement呢?总不能安于现状吧
Policy可划分为deterministic policy和stochastic policy两种,前者是给定状态产生确定的动作,后者是形成了一种条件概率分布,即给定状态,输出所有可能动作的概率分布。直观地,讨论deterministic policy的improvement是最容易的,因为如果我们必须要在某一个状态下进行improve,就意味着我们至少这一状态下要采取一些与原有动作不同的新动作,否则就是完全一致的policy。那么,既然要improve,我们就需要考量新动作的执行对于未来累积回报的改变是良性还是恶性的,如果采取了新动作只能获得比原来更低的累积回报,那还不如不改。
状态-动作价值函数为PI提供了方向:
\begin{aligned} q_{\pi}(s, a) & \doteq \mathbb{E}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) \mid S_{t}=s, A_{t}=a\right] \\ &=\sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right] \end{aligned}
结合状态价值函数可以看出,状态价值函数是状态-动作价值函数关于policy的数学期望,如果有一个未被执行的动作能够有效带来高于当前policy产生的价值,那只要再次遇到该状态就执行这个优先级更高的新动作,就能在原始policy的基础上进一步提升,即实现了policy improvement。而这种改进的有效性,被policy improvement theorem支撑着:
定理 对于两个deterministic policies \pi,\pi' ,对于所有的状态 s\in S ,若满足 q_{\pi}(s,\pi'(s))\geq v_{\pi}(s) ,那么policy \pi' 至少不劣于policy \pi ,即 v_{\pi'}(s)\geq v_{\pi}(s) 。
这个定理的证明就是简单地放缩和替换,但有些步骤我还是模棱两可,为了说服我自己,我给了自己一个这样的证明: \begin{aligned} v_{\pi}(s) & \leq q_{\pi}\left(s, \pi^{\prime}(s)\right) \\ &=\mathbb{E}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) \mid S_{t}=s, A_{t}=\pi^{\prime}(s)\right] \\ &=\sum_{s',r}p(s',r|s,\pi'(s))[r+\gamma v_{\pi}(s')]\\ &=1_{\pi'(a|s)}\sum_{s',r}p(s',r|s,\pi'(s))[r+\gamma v_{\pi}(s')]\\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) \mid S_{t}=s\right] \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma q_{\pi}\left(S_{t+1}, \pi^{\prime}\left(S_{t+1}\right)\right) \mid S_{t}=s\right] \\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma \mathbb{E}\left[R_{t+2}+\gamma v_{\pi}\left(S_{t+2}\right) \mid S_{t+1}, A_{t+1}=\pi^{\prime}\left(S_{t+1}\right)\right] \mid S_{t}=s\right] \\ &=\sum_{a}\pi'(a|s)\sum_{s',r}p(s',r|s,a)[r+\gamma[\sum_{s'',r'}p(s'',r'|s',\pi'(s'))[r'+\gamma v_{\pi}(s'')]]]\\ &=\sum_{a}\pi'(a|s)\sum_{s',r}p(s',r|s,a)r+\gamma[\sum_{a}\pi'(a|s){\color{blue}(\color{blue}{\sum_{s',r}p(s',r|s,a)\sum_{a'}\pi'(a'|s')\sum_{s'',r'}p(s'',r'|s',a'))}}]r'\\ &+\gamma^2[\sum_{a}\pi'(a|s){\color{blue}(\color{blue}{\sum_{s',r}p(s',r|s,a)\sum_{a'}\pi'(a'|s')\sum_{s'',r'}p(s'',r'|s',a'))}}]v_{\pi}(s'')\\ &=\sum_{a}\pi'(a|s)\sum_{s',r}p(s',r|s,a)r+\gamma[\sum_{a}\pi'(a|s)\color{blue}{\sum_{s'',r'}p(s'',r'|s,a)}]r'\\ &+\gamma^2[\sum_{a}\pi'(a|s)\color{blue}{\sum_{s'',r'}p(s'',r'|s,a)}]v_{\pi}(s'')\\ &=\mathbb{E}_{\pi'}[R_{t+1}|S_{t}=s]+\gamma\mathbb{E}_{\pi'}[R_{t+2}|S_{t}=s]+\gamma^2\mathbb{E}_{\pi}[v_{\pi}(S_{t+2})|S_{t}=s]\\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} v_{\pi}\left(S_{t+2}\right) \mid S_{t}=s\right] \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} v_{\pi}\left(S_{t+3}\right) \mid S_{t}=s\right] \\ & \vdots \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} R_{t+4}+\cdots \mid S_{t}=s\right] \\ &=v_{\pi^{\prime}}(s) . \end{aligned}
其中蓝色的部分按照back up diagram进行了概率分布的合并,重新构造成为从状态动作对 (s,a) 到状态-奖励对 (s'',r') 的转移概率,就可以写成我们更为熟悉的形式啦~(如果有错误,感谢各位大佬的指正),还有就是第四行的 1_{\pi'(a|s)} 替代了原始的策略分布的累积项 \sum_{a}\pi'(a|s) ,目的是为了凸显出状态价值函数的基本形式,毕竟deterministic policy以概率1生成指定动作。
基于以上证明,我们知道policy improvement是切实可行的,那么究竟怎么做才能更新策略呢?很简单,只要贪心一点就够了!在当前policy对应的状态价值函数下,智能体在每个状态都计算一下所有动作各自的状态-动作价值函数,选出值最大的执行就行啦,即有:
\begin{aligned} \pi^{\prime}(s) & \doteq \underset{a}{\arg \max } q_{\pi}(s, a) \\ &=\underset{a}{\arg \max } \mathbb{E}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) \mid S_{t}=s, A_{t}=a\right] \\ &=\underset{a}{\arg \max } \sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right] \end{aligned}
在进行policy improvement的过程中,如果出现了这样的情况:新旧策略 \pi',\pi 一样优秀,即二者对应的状态价值函数在所有状态上是一致的,i.e. v_{\pi'}(s)=v_{\pi}(s),\ \forall s\in S 。这就意味着policy improvement无法再通过最大化状态-价值函数来超越其数学期望,即状态价值函数已经达到最大,意即当前的所有状态价值都是由最优动作产生的,进行适当地替换我们就会发现:
\begin{aligned} v_{\pi'}(s) & = \max_{a}\mathbb{E}[R_{t+1}+\gamma v_{\pi}(S_{t+1})|S_{t}=s,A_{t}=a] \\ &=\max_{a}\mathbb{E}[R_{t+1}+\gamma v_{\pi'}(S_{t+1})|S_{t}=s,A_{t}=a]\\ &=\max_{a} \sum_{s', r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma v_{\pi'}\left(s^{\prime}\right)\right] \end{aligned}
只看等式左边和最后一行,这不就是最优价值函数的Bellman equation吗?!好嘛,那对应的 \pi' 就是optimal policy啦(更新不动了....)由此可见,只要原始policy不是optimal policy,policy improvement就能够严格地对当前policy进行优化!
前面的讨论都是建立在deterministic policy上的,那么对于stochastic policy呢?自然地,对于认定的一些具有最大价值的动作我们并不是直接以概率1执行,而是提高其被执行的概率(当然要保证所有动作的执行概率和为一)。只要保证次优动作执行概率为0,再把剩余的概率质量分配到等价的最优动作上去,仍然是可以实现policy improvement的!
最后借用书中的配图,来陈述一个例子吧~
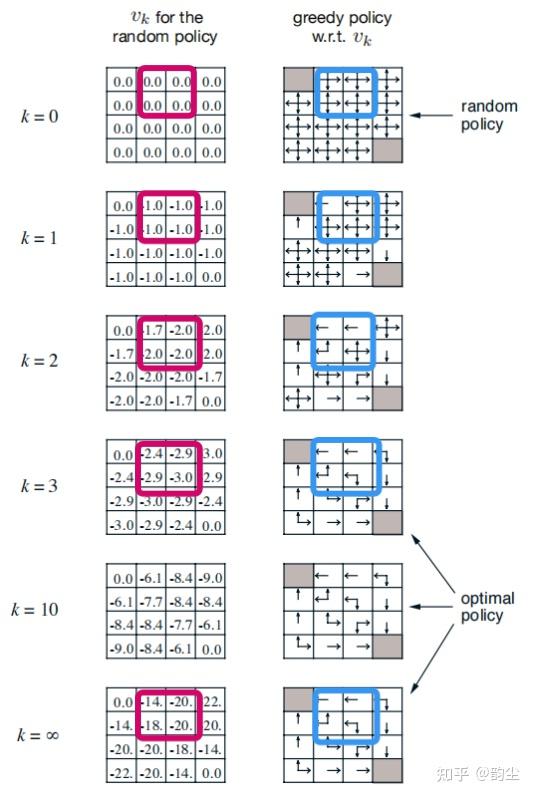

左边的框框是在计算random policy(上、下、左、右四个动作执行概率均等于0.25)的对应的状态价值函数,右边的框框是根据左边计算的状态价值函数进行基于random policy的policy improvement进而产生的greedy policy。考虑这里的折扣因子 \gamma=1 ,智能体每走一步就得到即时回报-1直到走到左上和右下的终点,状态价值也很好计算,例如我们观察k=3时红框中的-2.4、-2.9、-3.0,它们是根据k=2时的状态价值计算的:
- -2.4 \approx (上)0.25 *(-1 + 1 * -1.7)+(下)0.25 *(-1 + 1 * -2.0)+(左)0.25 *(-1 + 1* 0)+(右)0.25 *(-1 + 1 * -2.0)
- -2.9 \approx (上)0.25 *(-1 + 1 * -2.0)+(下)0.25 *(-1 + 1 * -2.0)+(左)0.25 *(-1 + 1* -1.7)+(右)0.25 *(-1 + 1 * -2.0)
- -2.9 \approx (上)0.25 *(-1 + 1 * -1.7)+(下)0.25 *(-1 + 1 * -2.0)+(左)0.25 *(-1 + 1* -1.7)+(右)0.25 *(-1 + 1 * -2.0)
- -3.0 \approx (上)0.25 *(-1 + 1 * -2.0)+(下)0.25 *(-1 + 1 * -2.0)+(左)0.25 *(-1 + 1* -2.0)+(右)0.25 *(-1 + 1 * -2.0)
在计算完成后,如何进行policy improvement呢?以k=2蓝框左下角的位置为例,我们根据当前价值函数可以分别计算上下左右的状态-动作价值:
- 上:-1 + 1 * -1.7 = -2.7
- 下:-1 + 1 * -2.0 = -3.0
- 左:-1 + 1 * -1.7 = -2.7
- 右:-1 + 1 * -2.0 = -3.0
但事实上如果保持random policy,该状态的价值为k=3中相同位置的-2.9,所以可以看出动作“上”和“左”执行后期望收益超过random policy的状态价值,那么policy improvement也就自然地从random policy(上下左右)变成了greedy policy(上左),如右图k=1到k=2的变化。
当我们再次计算k= \infty 时random policy对应的状态价值,可以发现已经不再变化,即policy evaluation已经收敛,此时的状态价值函数就是真正反映random policy性能的说明书,但实际上可以看到对应的greedy policy从k=3的时候起就已经不再变化了,即三轮policy evaluation的基础上进行policy improvement就已经找到optimal policy了(只是人为视角是未知的)。好了,如果我们把新的greedy policy再次当做policy improvement的起点,是不是还能进一步更新呢?确实,因为价值函数也已经发生了变化,而这就是下一节我们会来讨论的policy iteration。