
Web 的未来,语义互联已死,请拥抱自由编辑

语义网的故事
1989 年,Tim Berners-Lee 在欧洲核子研究中心(CERN)工作时,发现人们正在使用的各类计算机无论是文档保存还是菜单编辑,都很不一样。于是他产生了一个想法:
有没有可能开发一个元系统,将这些计算机及其所储存的文件统一起来?
于是 Tim 和他的同事们做的第一件事就是为 CERN 开发了一套存储电话号码的网页。起初这套网页运行在 CERN 的主机上,需要懂得一些计算机操作才能登录浏览,后来有些用户为了方便而安装了他们的网页浏览器(也被称为第一个网页浏览器)。
随后这套系统发生了爆发式增长,直至成了如今的规模。建立在 Web 上的公司都成为了巨头,包括但不限于 Google、Facebook、Twitter、Youtube 等。这些公司囊括了信息检索、网络社交、信息分享和视频内容,为普通消费者创造了极大便利。而这一切的源头都来自 Tim 在 1989 年写的一个号码簿程序。
Tim 本人也在 2017 年 04 月 05 日被美国计算机协会(ACM)授予图灵奖(A.M. Turing Award),该奖项通常被称为“诺贝尔计算机奖“。
Web 让世界和 Tim 本人获得了极大成功,但他认为简单的 Web(Simplicity of Web) 有很大的局限性因素(Limiting Factor),他对 Web 的未来还有更宏大的野心和目标。
在 2001 年 5 月份的《科学美国人》(在国内被称为“环球科学“)杂志上,Tim、James Hendler 和 Ora Lassila 联名发表了一篇名为 Semantic Web 的文章,这篇文章的副标题是“一种能让计算机理解的新型 Web 内容形式,将引发对新的未知可能性的探索“。




通读原文后,我们可以将语义网总结为以下两点:
- A consistent logical web of data
- Information is given well-defined meaning
翻译成中文就是:
- 一个一致的逻辑数据网络
- 信息具有明确的含义
这两点要素都是为了一个共同目标而服务的,即“Web 在之前只对人类友好,现在需要对机器也友好“。
- 语义网并非独立的另一个 Web,而是现在的 Web 的一个延伸。在其中,信息有明确的含义,更利于人机之间的合作。将语义网融入现在 Web 结构的初步努力已经在进行中了。不久的将来,当机器有更强的能力去处理和“理解”现在它仅仅进行显示的数据时,我们将看到很多重要的新功能。
我们每一个人每天都会使用 Google 和百度搜索大量信息,虽然我们都能获得想要的信息,但“搜索“的过程有时是非常耗时耗力的,你需要在不同的网页间跳转,阅读大量的文章或评论,然后从中搜寻自己想要的信息。这虽然能奏效,但并不是最好的。
比如:
- 需要背景知识的复杂查询
- 搜索“使用声纳但既不是蝙蝠也不是海豚的动物“
- “我该学习什么技能才能称为一名合格的增长黑客”
- 在特定领域中的查询
- 旅游咨询,比如“如果我想在大理待三个月,有哪些比较推荐的地方?”
- 商品和服务的价格
- 去年有哪些人离开了阿里巴巴创业,这些人都分布在哪些领域?
- 使用更聪明的“服务“
- 得到一个 DNA 序列,识别基因,确定它们产生的蛋白质,从而确定它们控制的生物过程
通常你需要聚合大量的信息源,然后将数据集中到一个 Excel 表中做分析。如果你是一名程序员,你可能还会写个爬虫抓取数据然后做一些有价值的信息输出。但有很多情况,这些方法都不管用,比如技术无法爬取某网站的内容(某公众号)、法律风险比较大或者过于浪费时间。
很多人可能从来没想过让机器做这些事情,因为计算机在人们眼里就是一个蠢货。但是这世界上没有什么是不会变的,计算机也是如此。语义网就是在做让机器帮助人类决策的事情,兼容语义网的是数据不仅对人类可读,还对机器可读,不仅如此,机器还要能做智能分析,并给予人类合适的建议。
传统的 Web 通过给一段文字加注释来表示具体的含义,比如我们阅读李彦宏的介绍时,人类在浏览器上看到的是:
李彦宏,男,百度创始人。但是计算机的表示是:
<Person>李彦宏</Person>,<Gender>男</Gender>,<Job>百度创始人<Job>。
可以看到,这种表示虽然赋予了文档语义,但却有以下几个缺点:
- 无法将李彦宏和百度关联到一起,这就不能进行关系表示;
- 机器无法自动为李彦宏增加新的介绍(比如李彦宏的妻子马东敏),这就不具备可拓展性;
- 该定义只有 Person、Gender和 Job这几项事物,这是有限的元数据;
在语义网的定义中,会这样表示李彦宏(为便于理解,此示例为简化版的表示方法):
<李彦宏, Gender, 男>
<李彦宏, Company, 百度>
<李彦宏, CompanyJob, 创始人>这被称作三元组,是一个主谓宾的格式,通过这样三元组的定义就可以描述出一个主体和另外一个主体的关系。
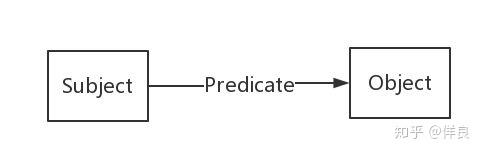

- 能同时表达数据以及根据数据进行推理的规则,并且允许任何现存的知识表现系统中的规则都能输出到Web上。在Web上增加逻辑性 —— 使用规则去推理、选择行为的步骤并回答问题的方法 —— 是语义网面临的一个任务。 这个任务涵盖了数学和工程化决策,使其更加复杂。
这种数据表示方法在语义网中被称为“知识表示“,后文都会以“知识表示“来指代上文的数据表示。
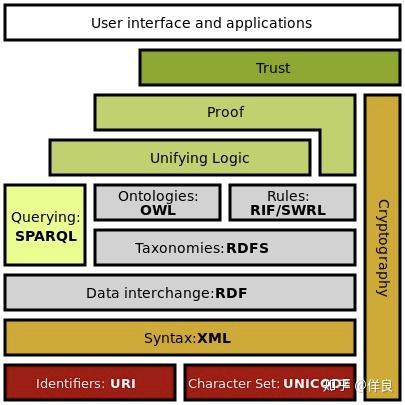
语义网的技术体系
在早期的语义网开发中,有一套规范来指导如何更好的进行知识表示,他们是 XML(eXtensible Markup Language,可拓展标记语言) 和 RDF (Resource Description Framework,资源描述框架)。
XML 是一种标记电子信息并使其具有结构性的标记语言,比如一篇笔记可以使用如下的结构进行表示:
<note>
<title>这是这篇笔记的标题</title>
<body>这是这篇笔记的正文</body>
</note>
资源描述框架(Resource Description Framework),一种用于描述Web资源的标记语言。RDF 是一个使用 XML 语法来处理元数据的规范。所谓元数据,就是“描述数据的数据”或者“描述信息的信息”。举个简单的例子,书的内容是书的数据,而作者的名字、出版社的地址或版权信息就是书的元数据。数据和元数据的划分不是绝对的,有些数据既可以作为数据处理,也可以作为元数据处理,例如可以将作者的名字作为数据而不是元数据处理。
RDF 是语义网的标准,比如描述百度这个网站的 RDF 示例如下:
<?xml version="1.0"?>
<rdf:RDFxmlns:rdf="<http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:si="http://www.runoob.com/rdf/>">
<rdf:Description rdf:about="<https://www.baidu.com>">
<si:title>百度一下,你就知道</si:title>
<si:author>李彦宏</si:author>
</rdf:Description>
</rdf:RDF>
其本质还是一个主谓宾的三元组表现形式。
但是可以看到,这种知识表示方法是非常繁杂的,所以 RDF 并没有在工业界得到广泛应用,其经常被批评为“由学者为学者创造的规范“。这也就是说,语义网的技术体系,与一线开发人员和多变的工业环境是十分不匹配的。
虽然后来又衍生出 RDF/XML,N-Triples,Turtle,RDFa,JSON-LD 等多种表现形式,但由于其极大的使用成本和复杂度,始终没有得到市场的广泛认可。
RDF 在发展到一定程度后,发现有太多的实体需要定义。比如一个人有胳膊、腿、眼睛等特征;一个学校有校长、老师、学生、教室等信息。为了描述这些信息,又出现了 RDFS。可以把 RDFS 理解成 RDF 的一个词汇表,这个词汇表就包括了“人”、“学校”这些实体中各种各样的信息。
再后来,专家们觉得 RDFS 的表达能力有限,于是发展出了 OWL。OWL 的全称是 Web Ontology Language,也就是 Web 本体语言(后来衍生出本体论,鉴于其复杂度和篇幅限制,读者可自行查阅相关资料以理解本体)。所谓本体,就是用来描述“人”、“学校”这些概念的详细说明,也是一种元信息。
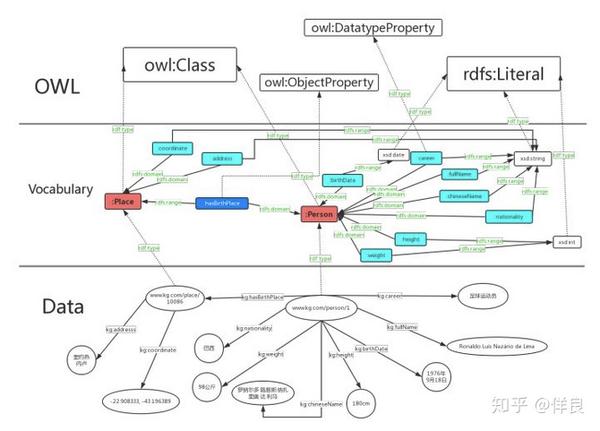

OWL 除了用来定义本体之外还有另外一个很强大的功能就是“推理”。举个比较基本的推理例子,我们用 RDFS 定义人和动物两个类,另外,定义人是动物的一个子类。此时推理机能够推断出一个实体若是人,那么它也是动物。这是一种最基本的推理,OWL 不仅支持这样的推理,还支持更有实际意义的推理。本文主要讲解语义网的故事,这里就不再详述更多技术细节了。
RDF 可以理解成一种数据的存储规范,也可以理解成语义网的数据库。这就好比,MySQL 和 Postgres 都是关系型数据库的实现,而他们都使用 SQL 作为查询语言。同样的,RDF 也有自己的查询语言,其名称为“SPARQL“。
举个易懂的例子,使用 SPARQL 可以查询以下信息:
- 所有的 RDF 三元组。
- 周星驰出演了哪些电影?
- 英雄这部电影有哪些演员参演?
- 巩俐参演的评分大于 7 的电影有哪些?
在 2006 年,Tim 提出了关联数据(Linked Data),这是一种万维网上创建语义关联的方法。这个方法集成了 RDF、SPARQL 等众多语义网实用技术。
语义网的技术体系很庞大,因篇幅所限,技术介绍就到此为止,让我们跳出复杂的语义网技术,转向更宏观的语义网愿景。
回归到语义网最初的愿景
语义网最初希望个体和企业都能够对自己的数据进行语义标注,这显然没能实现。大部分人都是内容消费者,而不是内容生产者。Cory Doctorow阐述过一个观点:“这种由人类自发创建的语义标注是一种乌托邦而且永远不可能实现”。Cory 认为数据标注是一件吃力不讨好的事情,首先过程很枯燥,第二几乎不能给企业和个人带来任何好处。企业关心的是公开数据后会不会对业务产生正面影响,如果这么做不但不能促进业务增长,反而导致竞争对手可以更快的占有市场,那么这是不可能吸引任何企业参与到语义网的建设中去的。
有的人觉得语义网这个概念早就已经死了,有的人觉得语义网已经存在于我们每天的生活中,只是我们没意识到。Google、Yahoo!、微软、IBM 这些公司都从 Web 的迅速发展中分到了一大杯羹。而 Google 于 2012 年 5 月 16 日发布了“知识图谱”后,如今业内也已经很少谈及语义网,多以知识图谱来代替对语义网的称呼,所以 Google 对语义网的贡献是很大的。
Google 知识图谱最常见的一个体现是搜索类似“姚明的身高”或“奥巴马的老婆”这样的信息:
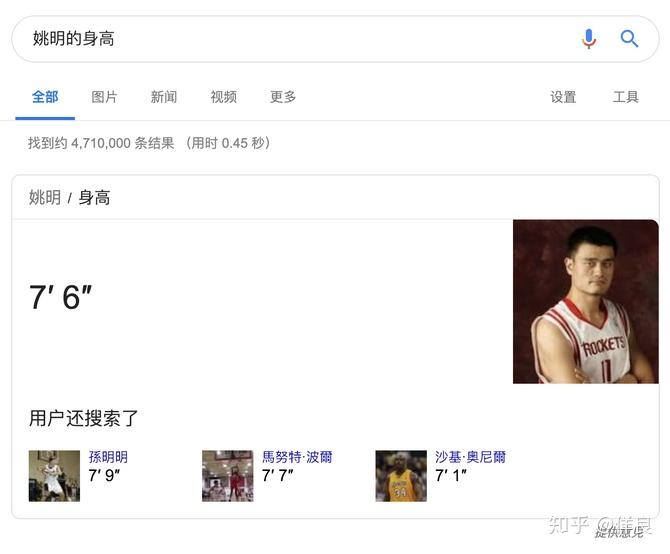

可以看到 Google 直接返回了姚明的身高并以卡片的形式展示,这就是 Google 对实体的标注和查询结果,虽然他的名字已不叫语义网,但是和语义网的技术息息相关。
W3C 上对语义网目标的描述是:
Allow data to be shared and reused across application, enterprise, and community boundaries.
翻译成中文是:
允许数据不受限制的在应用、企业和社区之间共享和重用。
这听起来非常有用,不仅可以减少大量的信息收集和处理成本,还可以让信息在全球公平共享。互联网之所以变得如此强大,是因为他整合了全球信息,并让全球每一个人可以公平的获取。不过这不完全正确,事实上,有时候获取信息还是非常困难的,比如上文中提到过“搜索时需要在不同的网页间跳转,阅读大量的文章或评论,然后从中搜寻自己想要的信息”,当然这并不是全部的信息障碍,比如某国的大型国家局域网举世闻名,也是妨碍信息流通的一种障碍。当然这还没涉及到众多的隐私问题,欧洲颁布 GDPR(数据隐私保护条例)后已经致使不少互联网服务下线。


语义网被其他规范侵蚀的故事
语义网的技术虽然没能在工业界流行,但这些年来 API(Application Programming Interface,应用程序编程接口) 却发生了激增,有些人称之为 API 生态。REST(一种软件架构风格) 和 JSON(一种非常简单的用于表示数据的方式) 成为了事实上暴露结构化数据的规范。用来构建 API 的工具已经非常成熟,同时也易于使用,这符合 Web 开发者的习惯,也是 Web 开发者从实践中总结来的经验。
相比语义网技术的束之高阁,API 显然更加下里巴人。如果仔细想一下,你会发现 REST API 十分贴近 W3C 所定义的关于语义网的目标:“允许数据不受限制的在应用、企业和社区之间共享和重用”。拿小程序举个例子来说,微信向开发者暴露的用户数据,都是以 API + JSON 的形式,而不是复杂的 RDF 等语义网技术。除此之外,神箭手云也提供了数以万计的 API 供开发者调用,虽然他不是免费的,但是上万次的请求只需要一两百元,也是大多数企业和个人开发者承担得起的。
使用 API + JSON 最大的好处就是简单和成本低,缺陷是没有统一的“语义规范”。比如同样是一篇文章,在微博上表示该篇文章内容用的可能是“content”,在微信上用的可能是“text”。于是,人们会把更多的时间花在数据对齐上。JSON-LD就是用来解决这个问题的,他提供了一套语义化的 JSON 规范。
- JSON-LD 针对的数据是“需要在全网传播的数据”而且“对其他个体或组织非常重要”。
这条路仍然任重而道远,长期来看,人们还是会以 JSON 作为数据交换的规范。
自由编辑的 Web —— 一个关于未来的故事
上面说了很多语义网的事情,现在,让我们回归到 “Web” 本身。
这一代 Web 正在向富文本客户端发展,也就是几乎都在模仿桌面软件和移动软件的设计。打开 Teambition、Tower、 Odoo 之类的 SaaS,可以看到他们的界面是丰富又复杂的;而如果打开 Webflow,不知道的人可能会认为这就是个 PC 软件:

而一旦模仿到了顶峰,就会回归本源。虽然这种设计的表现力很强,但他就像移动软件从拟物设计到扁平化设计一样,是一个过渡产物。乔布斯对界面设计的理念是:“任何年龄的人, 任何经历的人,都可以在拿到设备几分钟内轻松掌握它的用法”。于是苹果利用人们的日常经验,做出拟物化的界面,以降低用户的学习成本和理解难度。在《iOS 人机交互指南中》也提到“当你应用中的可视化对象和操作按照现实世界中的对象与操作仿造,用户就能快速领会如何使用它”。拿早期的按钮举例子,凸起的表示可以按,凹陷的表示已经被按了,非常易懂和直接。
在数码设备普及度不高的年代,拟物化是很有效果的,尤其是对从未接触过电子产品的老人和小孩。而一个先进的东西模仿古老的东西让用户快速理解,是一种过渡方案。如果一款温度计产品一定要设计成温度计的样子,那一定糟透了。随着数码设备的普及,人们对产品的要求也在不断变化。
现在的 Web 一直在模仿早期的 PC 软件,软件设计者想要用户从 PC 过渡到 Web 时可以无缝衔接,让他们“体验一致”。以及现在的“混合式”开发框架,聪明的开发者们依托 Web 跨平台和高可定制性的特性开发了大量模仿移动 APP 的框架。
现在,到了该重新思考的时候了。随着 Web 的普及,用户真的需要这么复杂的人机交互方式吗?这样复杂的交互真的是对用户最友好的吗?真的能让用户实现利益最大化吗?软件真的都需要如此复杂的流程吗?
让我们想一想 Web 刚诞生的时候是什么样,没错 —— 都是文档。现在再问一下自己 —— “强大的功能真的需要强大的 UI 才能表现出来吗”?第一代 iPhone 刚面世时,屏幕不大,但是拥有很多功能,这些功能都是用户所真正关注的,用户不关注的功能都被隐藏了起来。我们经常提及“少即是多”,那么这句话的真正含义是什么呢?
真正的产品逻辑不是加无可加,而是减无可减
注意这里的“加”和“减”不是指 UI 上的加减,而是认知、流程和逻辑上的精简。
Web 前端技术突飞猛进的这几年(从刀耕火种到如今的工业化黎明),开发者有了更强大的锤子,于是想创造更强大更有质感的软件,一路狂飙后,在软件日趋饱和和趋同化的今天,是时候做出改变了。


那么,让我们再来看看什么是“可编辑的 Web”。
我们现在所使用的所有软件,本质都是在管理数据。微信在管理你的社交数据,抖音在管理你的多媒体娱乐数据,淘宝在管理你的购物数据,公众号在管理文章数据,高德在管理世界的交通数据,微博在管理媒体数据,贴吧在管理兴趣社区数据,支付宝在管理你的财务数据。
这些应用形式的不同,在于数据的不同。你不能让一个管理好友的程序使用地图样式的 UI(当然,从业务层面,地图 + 社交可能是一个不错的组合创新,但这就是另外一个话题了),也不能让一个管理财务数据的应用使用通讯录的 UI。一个应用的形式既是和业务模式匹配的,也是和数据匹配的。
那么,有没有可能有这么一款应用,他看上去很简单,但是拥有无穷的元素,可以让你自由组合成你想要的应用。可能,在前期,他只是一款用来管理知识的笔记,或者是用于团队间协作的文档系统。
但这就是 Web 的独特性,也是文档流的体现。
“可编辑的 Web” 就是将 Web 重新设计成可以编辑的文档,把所有的元素都视作是可编辑的文档。不要那么多的线框,也不要那么多的按钮。把所有的输入框都变成一个唯一的输入框 —— 就像 Word 一样,你几乎可以在 Word 中书写任何文档,做成任何事情,但是 Word 很明显不是“可编辑 Web” 的最优解。或者把这个输入框理解成一个画板,在输入的同时利用人工智能预测你想要输入的元素,然后给你推荐并且让你选择。
你可能先用这款软件代替 Word 和其他协作工具,比如 Google Docs、Confluence、Jira、Google Sheets。所有这些事情都可以在一款软件中完成,并且每一个元素都在你的掌控之中,不受任何限制,因为所有一切都是“可编辑”的。
想要一个任务管理列表?想做一个产品路线图?想勾画用户故事地图?想和设计师同步设计?CEO 想在全公司同步自己的价值观?只需要一款软件就可以实现。你还可以像早年定制 QQ 空间一样定制自己的工作空间、娱乐空间或生活空间,用你自己的方法解决问题,你是不受任何限制的,能限制你的只有你自己的想象力。
The best way to predict the future is to invent it.
自由编辑的 Web 出现后,必将引发一系列的新兴创业活动。
人工智能在未来 Web 中的角色
我们花了大量篇幅讲述了语义网和可编辑 Web的设计和思想。那么,这两者可否进行结合呢?万维网之父 Tim 已经给出了答案。
Tim 在 2017 年底启动了 Solid 项目,然后又组建了一家名为 Inrupt 的公司以推动 Solid 商业化。
Solid是 Social Linked Data 的缩写,官方宣称是一个去中心化社交平台。而 Inrupt 这家公司的使命是“ Re-decentralize the Internet”,即“使互联网重新去中心化”。简单来说,现在我们的数据都在各大互联网巨头手中,基本上你没有办法将其自由导出,而 Solid 使用上文介绍过的“Linked Data”的规范使数据可以在互联网中自由流通。
举个例子,假如微博和微信同时支持了 Solid 协议,那么当你发一条朋友圈后,微博也会自动同步。不仅如此,如果你不向微博授权,那么微博就拿不到你的这部分数据。这就打破了由各巨头故意建造的数据孤岛,也让数据真正归创造内容的用户所有。所以社交并不是 Solid 的目的,只是 Solid 想通过社交促使更多用户将数据上传到 Solid 中,从而使完善 Solid 的生态,完成冷启动。
所谓 Solid 的生态,就是数据的表示方法符合语义网的语义规范,也就是用 RDF 来做存储。
鲍捷博士在一篇文章中曾指出“从目的的角度,语义网是一套减少数据摩擦,加快数据流动速度的方法”。我们探讨了很多“为什么”,却没探讨过“怎么做”。毫无疑问,在现代互联网中,社交媒体是信息传播速度最快的渠道。这么看,Solid 的社交野心是非常顺理成章的。


Solid 的软件设计上,可以理解为一个“可自由编辑的 Web”。但是因为其是一款开源软件,缺乏商业场景支撑,导致其用户体验**非常差,注意是非常差。**具体体现在 UI 的丑陋性和数据存储/读取的复杂性。尤其是交互的复杂性,连很多专业人士都玩不转,更何况是什么都不知道的普通人呢?这是阻碍 Solid 大规模普及的原因之一,也就是还没有人开发出一款能让普通人玩得转的 Solid 程序。而这样的程序没出来的原因也在于使用了复杂又古老的语义网技术,将一大波富有创造力的开发者拒之门外。
Semantic Web technologies were complex and opaque, made by academics for academics, not accessible to many developers, and not scalable to industrial workloads.
机器学习在分析半结构化数据、非结构化文本图片和音视频领域取得了令人瞩目的成果。这取决于超大的数据集和算法的提升,深度学习就是一个例子。
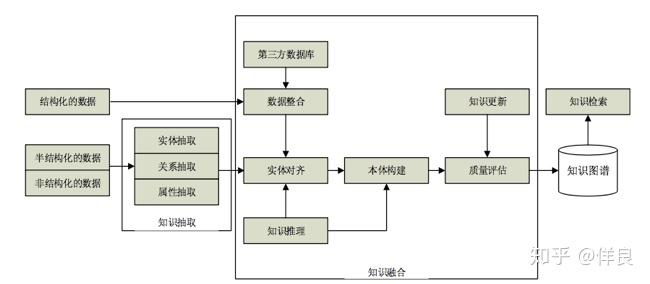

人们讨论过很多关于人工智能在知识图谱构建中的角色,他能帮助图谱自动化的标注数据和更新数据,而且随着数据量的增加,算法也会越来越准确。但是,算法只是一种表层的东西,他看的只是现象,而无法理解事物深层次的含义,因为机器是缺乏基础常识的,也没有时空观念,更没有人类的生活体验,人类的生活经验也是辅助决策的重要来源。即使是 Google 的 Knowledge Vault 系统,抽取的事实也必须经过人类修正,所以不要幻想人工智能会帮助人类做所有事(现阶段只有傻子才会这么想,但是没有什么是不能变的,说不定 100 年后真的实现了呢)。
在可编辑 Web 普及后,大量数据将带有语义的被存储在计算中,数据孤岛将被架起桥梁,此时,智能助理将成为现实。假如你的社交数据显示你非常讨厌中医,那么在另外一个人和你聊天触及到中医时会对对方进行友善的提醒,以防止进一步的摩擦或冲突。
而实现一个可编辑的 Web 并不需要高深莫测的技术,只需要“工程”。人工智能会成为一个真正的实用个人助理,帮助你解决生活、工作中的各种问题,说不定,他还能在计算机中模拟一个“你”,那时,所有人都将以 bit 的形式在电子世界中永生。
语义互联也好,自由编辑也好,都是一个手段,真正的目的还是将最好的服务带给最广大人民。毕竟,所有的技术都是人的延伸。
参考文献
- The Semantic Web is dead. Long live the Semantic Web
- Whatever Happened to the Semantic Web?
- The History of the Semantic Web is the Future of Intelligent Assistants
- semantic-web-the-inside-story
- Build your own Knowledge Graph
- Semantic Web
- 语义网是什么?有什么好处?- 鲍捷博士
- Solid 中文网 | 数据自有 去中心化 语义网
