
David Silver 增强学习——Lecture 6 值函数逼近

其他Lecture
【1】搬砖的旺财:David Silver 增强学习——笔记合集(持续更新)
【2】搬砖的旺财:David Silver 增强学习——Lecture 1 强化学习简介
【3】搬砖的旺财:David Silver 增强学习——Lecture 2 马尔可夫决策过程
【4】搬砖的旺财:David Silver 增强学习——Lecture 3 动态规划
【5】搬砖的旺财:David Silver 增强学习——Lecture 4 不基于模型的预测
【6】搬砖的旺财:David Silver 增强学习——Lecture 5 不基于模型的控制
【7】搬砖的旺财:David Silver 增强学习——Lecture 7 策略梯度算法
扩充
除了David Silver的教程,还推荐RL祖师爷——Rich Sutton的《Introduction to Reinforcement Learning with Function Approximation》。
PPT链接:http://media.nips.cc/Conferences/2015/tutorialslides/SuttonIntroRL-nips-2015-tutorial.pdf
视频链接:https://www.youtube.com/watch?v=ggqnxyjaKe4
前言
之前讲过,David Silver的课程一共分为了10个Lectures,其中前5讲是第一部分,偏重于基础理论;现在我们要正式进入后5讲啦 ,即第二部分,将扩展第一部分中介绍的表格方法(tabular method),偏重于解决大规模问题的应用理论。
在很多强化学习的任务中,状态空间(state space)是无穷大的。在有限时间和有限空间的情况下,我们无法找到最优策略(optimal policy)或最优值函数(optimal value function)。
无穷大状态空间的问题还在于,在很多任务中,有些状态将永远不会重现。为了在这种情况下作出明智的决策,有必要从以前的经验中推导出与当前状态相似的状态。换句话说,泛化(generalization)才是最关键的问题。
幸运的是,在目前研究的基础上,我们只需要将强化学习与现有的泛化方法相结合。我们所需要的泛化类型通常被称为函数逼近(function approximation),因为它从目标函数(例如,值函数——value function)中获取例子并试图从这些例子中实现推广,从而构造该函数的近似表达。函数逼近是监督学习(supervised learning)的一种方法,在机器学习(machine learning)、人工神经网络(artificial neural network)、模式识别(pattern recognition)和统计曲线拟合(statistical curve fitting)中得到了广泛的应用。
Lecture 6的主要内容如下:


目录
简介
1、简介 ····1.1 大规模强化学习 ····1.2 价值函数逼近 ····1.3 值函数近似的类型 ····1.4 函数近似器 2、梯度算法 ····2.1 梯度下降法 ····2.2 值函数近似和随机梯度下降 3、线性函数近似 ····3.1 特征向量 ····3.2 线性值函数近似 4、值函数近似下的增量式评价算法 ····4.1 增量式评价算法 ····4.2 值函数近似下的MC ····4.3 值函数近似下的TD ····4.4 值函数近似下的 \mathrm{TD\left( \lambda \right)} 5、值函数近似下的增量式优化算法 ····5.1 通用策略迭代 ····5.2 对Q函数的近似 ····5.3 线性Q函数近似 ····5.4 增量式策略优化算法 6、收敛性简介 ····6.1 策略评价时的收敛问题 ····6.2 策略优化算法的收敛性 7、神经网络和卷积神经网络
1、简介
- 1.1 大规模强化学习
强化学习可以用来解决大规模问题,例如西洋双陆棋(Backgammon)有 10^{20} 个状态空间,围棋AlphaGo有 10^{170} 个状态空间,机器人控制以及无人机控制需要的是一个连续状态空间。如何才能将强化学习应用到这类大规模的问题中,进而进行预测和控制呢?
- 1.2 价值函数逼近
到目前为止,我们使用的是查表(Table Lookup)的方式来表达值函数,这意味着每一个状态对应一个 V\left( s \right) 或者每一个状态-行为对对应一个 Q\left( s,a \right) 。对于大规模问题,这么做需要太多的内存来存储,而且有的时候针对每一个状态学习得到价值也是一个很慢的过程。
对于大规模问题,解决思路可以是这样的:
1. 通过函数近似来估计实际的价值函数
\hat v\left( s,\textbf{w} \right)\approx v_\pi\left( s \right)
\hat q\left( s,a,\textbf{w} \right)\approx q_\pi\left( s,a \right)
2. 把从已知状态学到的函数通用化推广至那些未碰到的状态中
3. 使用MC或TD学习来更新函数参数 \textbf{w}
- 1.3 值函数近似的类型
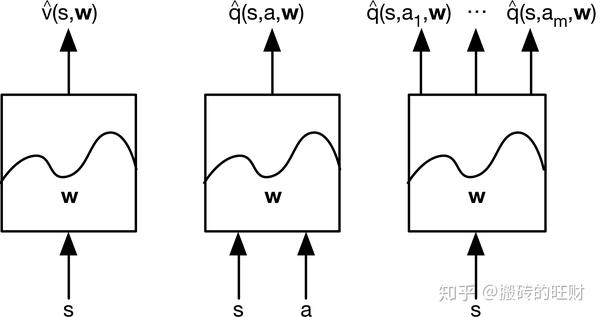
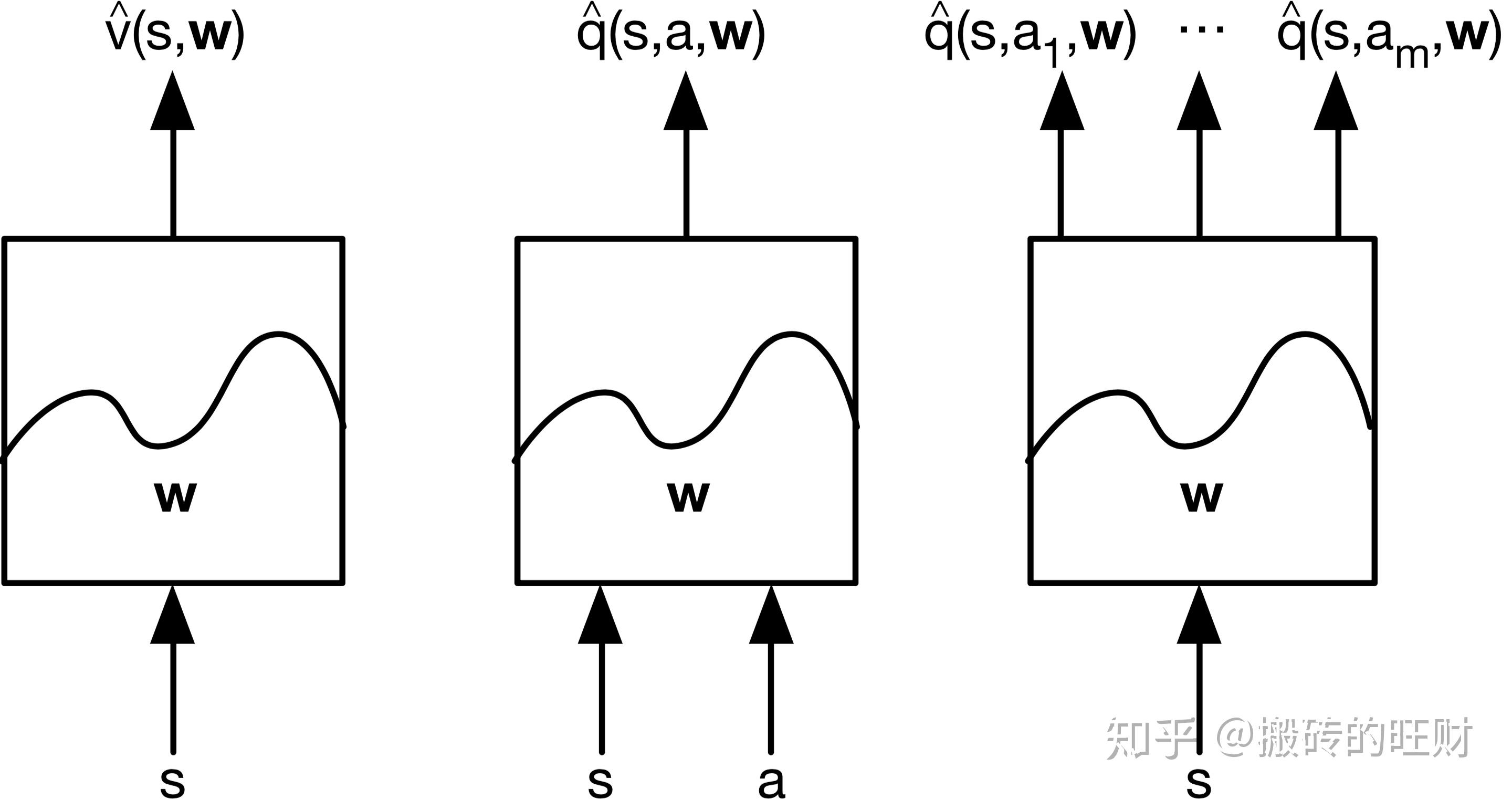
- 针对状态本身,输出这个状态的近似价值
- 针对状态-行为对,输出状态-行为对的近似价值
- 针对状态本身,输出一个向量,向量中的每一个元素是该状态下采取一种可能行为的价值
(注:3不能用于连续的动作,但是方便于求max操作。)
- 1.4 函数近似器
考虑可微的函数近似器,比如:
- 线性模型
- 神经网络
- 决策树
- 最近邻法
- 傅立叶基
- 小波变换...
强化学习应用的场景其数据通常是非静态(non-stationary)、非独立同分布(non-iid)的,因为下一个状态通常与前一个状态高度相关。因此,函数近似器也需要适用于非静态、非独立同分布的数据。
关于独立同分布的详情请参考:
2、梯度算法
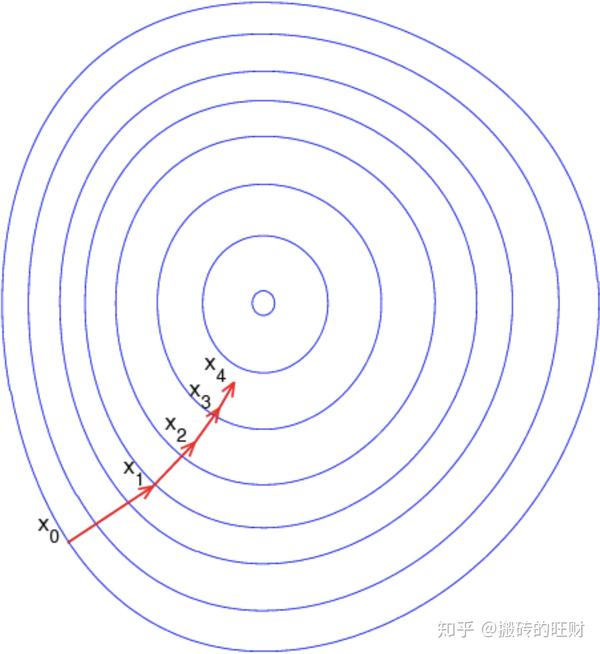
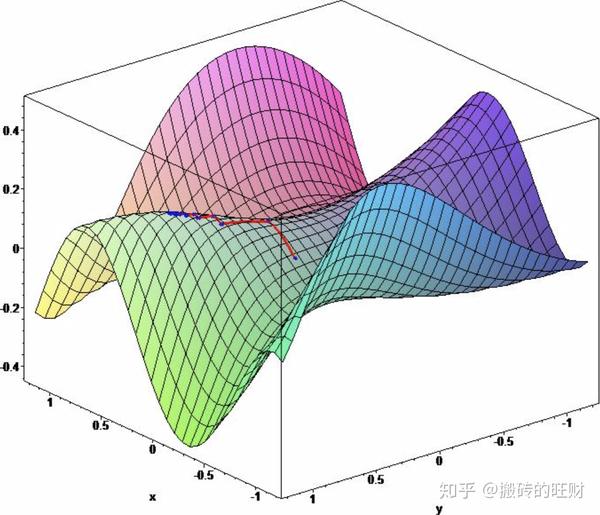
- 2.1 梯度下降法
如果 J\left( \textbf{w} \right) 是参数向量 \textbf{w} 的可微函数
那么 J\left( \textbf{w} \right) 的梯度定义为 \nabla_{\textbf{w}}J\left( \textbf{w} \right)= \begin{bmatrix} \frac{\partial J\left( \textbf{w} \right)}{\partial \textbf{w}_1}\\ \frac{\partial J\left( \textbf{w} \right)}{\partial \textbf{w}_2}\\ \vdots\\ \frac{\partial J\left( \textbf{w} \right)}{\partial \textbf{w}_n} \end{bmatrix}
为了能找到 J\left( \textbf{w} \right) 的局部最优值
沿负梯度方向更新参数向量 \textbf{w} : \Delta\textbf{w}=-\frac{1}{2}\alpha\nabla_{\textbf{w}}J\left( \textbf{w} \right)
(注:这里 \alpha 代表步长)


关于梯度下降的详情请参考:
- 2.2 值函数近似和随机梯度下降
目标
寻找参数向量 \textbf{w} ,以最小化近似值函数 v\left( s, \textbf{w} \right) 和真实的值函数 v_\pi\left( s \right) 之间的均方误差(mean-squared error,MSE) J\left( \textbf{w} \right)={\Bbb E}_\pi\left[ \left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)^2 \right]
梯度下降算法会寻找局部最小值(链式法则)
\Delta\textbf{w}=-\frac{1}{2}\alpha\nabla_{\textbf{w}}J\left( \textbf{w} \right)=\alpha{\Bbb E}_\pi\left[ \left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right) \right]
(注:此时的 \Delta\textbf{w} 式子中, v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) 和 \nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right) 都能够求出来,但是期望 {\Bbb E}_\pi 却不好处理。为了去掉期望 {\Bbb E}_\pi ,最好的方法就是将 \pi 的概率分布求出来,然后再加权求和。这样操作过于复杂,实际操作的时候会采用蒙特卡洛的形式,只用一个样本或者一批样本进行更新,此时会产生一定的样本误差。当样本足够多的时候,所有更新方向加权后就能逼近真实的梯度方向。)
随机梯度下降算法会对梯度进行采样
\Delta\textbf{w}=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right)
其他常见的优化算法:牛顿法,批量梯度下降,动量梯度下降,RMSprop,Nesterov, Adagrad,Adam...
3、线性函数近似
- 3.1 特征向量
通过一个特征向量表达状态 \mathrm{x}\left( S \right)= \begin{bmatrix} \mathrm{x}_1\left( S \right)\\ \mathrm{x}_2\left( S \right)\\ \vdots\\ \mathrm{x}_n\left( S \right) \end{bmatrix}
(注:独立的状态表示方法 S_1 S_2 S_n 比较适用于表格法,而函数近似法更希望提取到状态与状态之间的相互关系,假如某几个状态关系紧密,那么更新一个状态便会影响到其他几个状态,即一批状态满足同一个“规律”。所以,函数近似法会采用特征去表示状态,有时一个特征不够的时候便会采用多个特征,形成了特征向量。举个例子,学习人种分类或学习人脸识别,表格法会将一个一个的人脸表示为一个一个的状态,这些状态之间没有互相关系;但是如果用特征表述状态,比如第一个特征表示肤色,第二个特征表示眼睛的形状,那么我们就会得到这一批肤色的人是什么样的认知,这一批眼睛的形状是什么样的认知,这样就能把有限样本学习到的知识迁移到未见样本上。)
常用于特征之间关系不明显的数据
- 3.2 线性值函数近似
通过特征的线性组合表达值函数 \hat v\left( S,\textbf{w} \right)={\mathrm x}\left( S \right)^{T}\textbf{w}=\sum_{j=1}^n{\mathrm x}_j\left( S \right)\textbf{w}_j
目标函数是 \textbf{w} 的二次形式 J\left( \textbf{w} \right)={\Bbb E}_\pi\left[ \left( v_\pi\left( S \right)-\mathrm{x} \left( S \right)^{T}\textbf{w} \right)^2 \right]
随机梯度下降会收敛到全局最优值
在线性值函数近似的情况下,梯度的计算变得非常简单
\begin{align*} \nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right)&=\mathrm{x}\left( S \right)\\ \Delta\textbf{w}&=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right) \\ &=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\mathrm{x}\left( S \right) \end{align*}
(注:参数更新量 = 步长 × 预测误差 × 特征值)
- 3.3 表格检索特征
表格检索是线性值函数近似的一种特殊形式
(注:每一个状态看成一个特征,个体具体处在某一个状态时,该状态特征取1,其余取0。参数的数目就是状态数,也就是每一个状态特征有一个参数。)
使用表格检索特征 \mathrm{x}^{table}\left( S \right)= \begin{bmatrix} \textbf{1}\left( S=s_1 \right)\\ \textbf{1}\left( S=s_2 \right)\\ \vdots\\ \textbf{1}\left( S=s_n \right) \end{bmatrix}
参数向量 \textbf{w} 本质上相当于给了每个状态对应的值函数 \hat v\left( S,\textbf{w} \right)= \begin{bmatrix} \textbf{1}\left( S=s_1 \right)\\ \textbf{1}\left( S=s_2 \right)\\ \vdots\\ \textbf{1}\left( S=s_n \right) \end{bmatrix}^T \begin{bmatrix} \textbf{w}_1\\ \textbf{w}_2\\ \vdots\\ \textbf{w}_n \end{bmatrix}
4、值函数近似下的增量式评价算法
- 4.1 增量式评价算法
之前是假设了给定了真实的值函数 v_\pi\left( s \right)
但是在RL环境中,并不知道真实的值函数,只有奖励值
直观地,我们用目标值替代 v_\pi\left( s \right)
1. 对于 \mathrm{MC} ,目标值是回报值 G_t
\begin{align*} \Delta\textbf{w}&=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right)\\ &=\alpha\left( G_t-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right) \end{align*}
2. 对于 \mathrm{TD\left( 0 \right)} ,目标值是TD目标值 R_{t+1}+\gamma {\hat v}\left( S_{t+1},\textbf{w} \right)
\begin{align*} \Delta\textbf{w}&=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right)\\ &=\alpha\left( R_{t+1}+\gamma {\hat v}\left( S_{t+1},\textbf{w} \right)-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right) \end{align*}
3. 对于 \mathrm{TD\left( \lambda \right)} ,目标值是 \lambda 回报值 G_t^\lambda
\begin{align*} \Delta\textbf{w}&=\alpha\left( v_\pi\left( S \right)-\hat v\left( S,\textbf{w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S,\textbf{w} \right)\\ &=\alpha\left( G_t^\lambda-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right) \end{align*}
- 4.2 值函数近似下的MC
回报值 G_t 是真实值函数 v_\pi\left( S_t \right) 的无偏估计
构建监督学习的“训练数据” \left< \mathop{\underline{S_1}}_{\textrm{输入}},\mathop{\underline{G_1}}_{\textrm{输出\标签}}\right>,\left< S_2,G_2\right>,\cdots,\left< S_T,G_T\right>
更新参数:
\begin{align*} \Delta\textbf{w}&=\alpha\left( G_t-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right)\\ &=\alpha\left( G_t-\hat v\left( S_t,\textbf{w} \right) \right){\mathrm x}\left( S_t \right)线性情况下 \end{align*}
(注:利用监督学习的数据驱动网络进行更新。)
- 4.3 值函数近似下的TD
TD目标值 R_{t+1}+\gamma {\hat v}\left( S_{t+1},\textbf{w} \right) 是真实值函数 v_\pi\left( S_t \right) 的有偏估计
仍然可以构建监督学习的“训练数据” \left< \mathop{\underline{S_1}}_{\textrm{输入}},\mathop{\underline{R_{2}+\gamma {\hat v}\left( S_{2},\textbf{w} \right)}}_{\textrm{输出\标签}}\right>,\left< S_2,R_{3}+\gamma {\hat v}\left( S_{3},\textbf{w} \right)\right>,\cdots,\left< S_{T-1},R_{T}\right>
更新参数:
\begin{align*} \Delta\textbf{w}&=\alpha\left( R_{t+1}+\gamma {\hat v}\left( S_{t+1},\textbf{w} \right)-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right)\\ &=\alpha\delta{\mathrm x}\left( S \right)线性情况下 \end{align*}
- 4.4 值函数近似下的 \mathrm{TD\left( \lambda \right)}
\lambda 回报值 G_t^\lambda 也是真实值函数 v_\pi\left( S_t \right) 的有偏估计
仍然可以构建监督学习的“训练数据” \left< \mathop{\underline{S_1}}_{\textrm{输入}},\mathop{\underline{G_1^\lambda}}_{\textrm{输出\标签}}\right>,\left< S_2,G_2^\lambda\right>,\cdots,\left< S_{T-1},G_{T-1}^\lambda\right>
前向视角的 \mathrm{TD\left( \lambda \right)} :
\begin{align*} \Delta\textbf{w}&=\alpha\left( G_t^\lambda-\hat v\left( S_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right) \\ &=\alpha\left( G_t^\lambda-{\hat v}\left( S_t,{\textbf w} \right) \right){\mathrm x}\left( S_t \right)线性情况下 \end{align*}
后向视角的 \mathrm{TD\left( \lambda \right)} :
\delta_t=R_{t+1}+\gamma{\hat v}\left( S_{t+1},\textbf{w} \right)-{\hat v}\left( S_{t},\textbf{w} \right)
E_t=\gamma\lambda E_{t-1}+\nabla_{\textbf{w}}\hat v\left( S_t,\textbf{w} \right)=\gamma\lambda E_{t-1}+{\mathrm x}\left( S_t \right)线性情况下
\Delta{\textbf w}=\alpha\delta_tE_t
5、值函数近似下的增量式优化算法
- 5.1 通用策略迭代


策略评价:近似化策略评价, \hat q\left( \cdot,\cdot,{\textbf w} \right)=q_\pi
策略提升: \epsilon 贪婪策略提升
- 5.2 对Q函数的近似
近似Q函数 \hat q\left( S,A,{\textbf w} \right) \approx q_\pi\left( S,A \right)
最小化近似值和真实值的均方误差 J\left( {\textbf w} \right)={\Bbb E}_\pi\left[ \left( q_\pi\left( S,A \right)-\hat q\left( S,A,{\textbf w} \right) \right)^2 \right]
使用随机梯度下降来找到局部最小值:
-\frac{1}{2}\nabla_{\textbf{w}}J\left( \textbf{w} \right)=\left( q_\pi\left( S,A \right)-\hat q\left( S,A,{\textbf w} \right) \right)\nabla_{\textbf{w}}{\hat q}\left( S,A,{\textbf w} \right)
- 5.3 线性Q函数近似
用一个特征向量表示某一个具体的 S,A
{\textbf x}\left( S,A \right)= \begin{bmatrix} {\textbf x}_1\left( S,A \right)\\ {\textbf x}_2\left( S,A \right)\\ \vdots\\ {\textbf x}_n\left( S,A \right) \end{bmatrix}
通过特征的线性组合表达Q函数
\hat q\left( S,A,{\textbf w} \right)={\mathrm x}\left( S,A \right)^T{\textbf w}=\sum_{j=1}^{n}x_j\left( S,A \right){\textbf w}_j
随机梯度下降
\begin{align*} \nabla_{\textbf{w}}\hat q\left( S,A,{\textbf w} \right)&={\mathrm x}\left( S,A \right)\\ \Delta{\textbf{w}}&=\alpha\left( q_\pi\left( S,A \right)-\hat q\left( S,A,{\textbf w} \right) \right){\mathrm x}\left( S,A \right) \end{align*}
- 5.4 增量式策略优化算法
同样地,我们用目标值替换真实的 q_\pi\left( S,A \right)
1. 对于MC,目标值即回报值 G_t
\begin{align*} \Delta\textbf{w} &=\alpha\left( G_t-\hat q\left( S_t,A_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}{\hat q}\left( S_t,A_t,{\textbf w} \right)\\ \end{align*}
2. 对于 \mathrm{TD\left( 0 \right)} ,目标值是TD目标值 R_{t+1}+\gamma Q\left( S_{t+1},A_{t+1} \right)
\begin{align*} \Delta\textbf{w} &=\alpha\left( R_{t+1}+\gamma \hat q\left( S_{t+1},A_{t+1},{\textbf w} \right)-\hat q\left( S_t,A_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}{\hat q}\left( S_t,A_t,{\textbf w} \right)\\ \end{align*}
3. 对于前向视角的 \mathrm{TD\left( \lambda \right)} ,目标值是针对Q的 \lambda 回报值
\begin{align*} \Delta\textbf{w} &=\alpha\left( q_t^\lambda-\hat q\left( S_t,A_t,{\textbf w} \right) \right)\nabla_{\textbf{w}}{\hat q}\left( S_t,A_t,{\textbf w} \right)\\ \end{align*}
对于后向视角的 \mathrm{TD\left( \lambda \right)} ,
\delta_t=R_{t+1}+\gamma{\hat q}\left( S_{t+1},A_{t+1},\textbf{w} \right)-{\hat q}\left( S_{t},A_t,\textbf{w} \right)
E_t=\gamma\lambda E_{t-1}+\nabla_{\textbf{w}}\hat q\left( S_t,A_t,\textbf{w} \right)
\Delta{\textbf w}=\alpha\delta_tE_t
6、收敛性简介
- 6.1 策略评价时的收敛问题
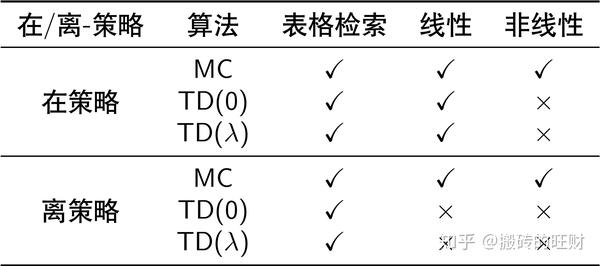

- 表格检索的收敛性最好
- 离策略的收敛性比在策略要差
- 非线性近似会影响收敛性
- TD算法的收敛性不如MC
- 6.2 策略优化算法的收敛性
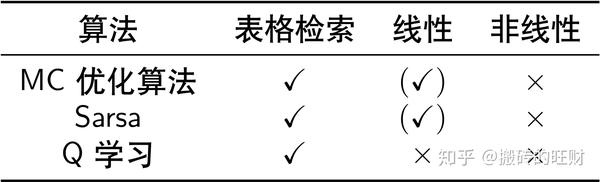

(注:其中 (✓) 表示接近最优值函数)
7、神经网络和卷积神经网络
详情请参考:
参考文献
【1】叶强:《强化学习》第六讲 价值函数的近似表示
【2】深度增强学习David Silver(六)——Value Function Approximation
【3】David Silver强化学习课程笔记(六)
【4】强化学习(六):价值函数的逼近(近似)
