
基于python的相关样本T检验分析(A/B test)

一、分析背景
在说正题之前,我们先来做一个简单好玩的小实验。请你用最快的速度说出下面四个汉字的颜色。

是不是很顺利的读出来了?那么,再试试下面这四个字。

是不是没有那么顺利了,甚至有些困难?知道 这是为什么吗?
今天,我们就来详细的介绍一种神奇的心理学效应——“斯特鲁普效应”。
1935年,美国心理学家斯特鲁普(John Riddly Stroop)在一次心理实验中发现: 当颜色的文字名字用另一种颜色显示时(比如“红”字用绿墨水书写),和使用同样的颜色显示(比如“红”字用红墨水书写)相比较,前者说出颜色的名字需要更长的时间,而且错误率会更高。这就是著名的“斯特鲁普效应”:
当大脑接收到了一种刺激,例如视觉刺激,而这种刺激包含了来自两个维度的信息——文字和颜色,那么,大脑对这两种信息的加工是不同的;
当这两个信息同时输入大脑时,大脑对两种信息的加工时同时进行的,如果想只对其中一个信息加工而不对另一个加工是难以做到的;
如果这两种刺激所包含的信息是一致的,例如用红墨水书写的“红”字,那么,大脑的处理速度不会减慢。相反,如果包含的信息是不一致的,例如,用绿墨水书写的“红”字,则会由于大脑内功能的相互竞争或不兼容导致反应速度减慢。
二、分析过程
选择24行数据作为分析对象,数据下载地址为
1.查看描述性统计信息
#导入数据包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入数据文件
data=pd.read_csv(r'C:\Users\Administrator\Desktop\stroop effect.csv')
#查看前5行数据
data.head()
#获取描述统计信息
data.describe()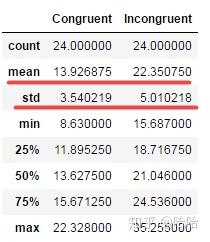
Congruent代表字体含义与颜色一致,Incongruent代表字体含义与颜色不一致。从一致与不一致两列数据的平均值和标准差中可以看出,不一致的平均反应时间和标准差均大于一致情况的平均反应时和标准差。
2.进行推断性统计分析
2.1假设验证
(1)提出问题
①零假设:斯特鲁普效应不存在,第一组平均值=第二组平均值;
备选假设:斯特鲁普效应存在,第一组平均值<第二组平均值。
②检验类型:相关样本检验/配对样本检验。求两列数据的差值数据集。
#画图
data.plot(kind='bar',figsize=(20,10))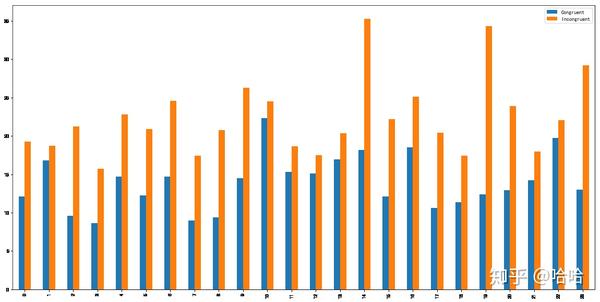

#计算差值数据集
data['Difference']=data['Congruent']-data['Incongruent']
data.head()
③抽样分布类型
#导入seaborn数据包
import seaborn as sns
#查看数据集分布
sns.distplot(data['Difference'])
plt.title('差值数据集分布')
plt.show()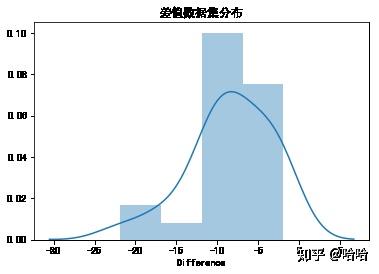
由图看出,差值数据的分布符合正态分布,且样本量<30,因此可以用t检验。
④检验方向
备选假设:斯特鲁普效应存在,第一组平均值<第二组平均值。因为存在“<”,所以才去单尾检验(左侧)。
(2)找到证据
#t检验,计算p值
#导入统计模块
from scipy import stats
#相关样本t检验
t,p_twoTail=stats.ttest_rel(data['Congruent'],data['Incongruent'])
#单尾p值
p_oneTail=p_twoTail/2
#输出t,p_twoTail,p_oneTail
print('t值为:',t,';双尾检验p值为:',p_twoTail,';单尾检验p值为:',p_oneTail)
t值为: -8.088610872807587 ;双尾检验p值为: 3.548719149724915e-08 ;单尾检验p值为: 1.7743595748624577e-08(3)判断标准
#判断标准(显著水平)使用alpha=5%
alpha=0.05(4)作出结论
#单尾检验的p值
p_oneTail=p_twoTail/2
#判断标准的显著水平
alpha=0.05
#使用if函数进行判断
if(t<0 and p_oneTail<alpha):
print('拒绝零假设,接受备择假设,即斯特鲁普效应存在')
else:
print('接受零假设,即斯特鲁普效应不存在')
拒绝零假设,接受备择假设,即斯特鲁普效应存在相关样本t检验结果如下:t (23)=-8.09,p=1.77e-08(a=5%),单尾检验(左尾)。该结果说明统计上存在显著差异,验证了斯特鲁普效应的存在。
2.2置信区间
使用该网址可以计算不同置信水平及自由度下的t值。
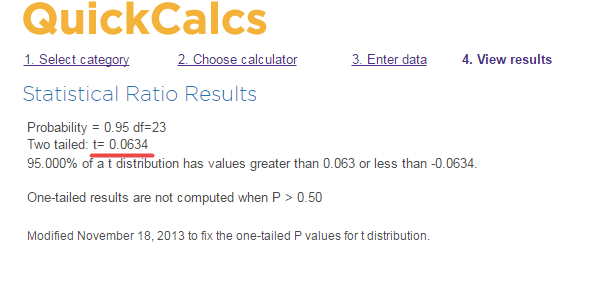

#95%置信水平,自由度为23的t值
t_ci=0.0634
#差值数据集的平均值
sample_mean=data['Difference'].mean()
#差值数据集的标准误差
se=stats.sem(data['Difference'])
#置信区间上限
a=sample_mean-t_ci*se
#置信区间下限
b=sample_mean+t_ci*se
print('%.2f'%a,'%.2f'%b)
-8.49 -8.36由以上计算结果可知,置信区间为CI=[-8.49,-8.36]。
2.3效应量
#计算效应量Cohen's d
#差值数据集对应的总体均值为0
pop_mean=0
#差值数据集的标准差
sample_std=data['Difference'].std()
#d
d=(sample_mean-pop_mean)/sample_std
print('%.2f'%d)
-1.65由以上计算结果可知,效应量d=-1,65,效果非常显著。
三、分析报告
1.描述统计分析
字体含义与颜色一致时,平均反应时为13.93秒,标准差为3.54秒;
字体含义与颜色不一致时,平均反应时22.35秒,标准差为5.01秒。
2.推论统计分析
1)假设检验
相关样本t检验t(23)=-8.09,p=1.77e-08,左尾检验。该结果说明一致与不一致两种情况下的平均反应时差异显著,即存在斯特鲁普效应。
2)置信区间
两个平均值差值在95%置信水平的置信区间为[-8.49,-8.36]。
3)效应量
d=-1.65