模型样本构建方案演进之路

TL;DR
- 样本生成过程中,存在诸多挑战,其中特征穿越是较为棘手的问题,解决方法是,生成样本时使用Point-in-Time Correct特征
- 通过对特征请求进行快照,可以做到Point-in-Time Correct,但在大数据量下,常见的几个方案都各有瓶颈
- 美团给出了一个巧妙的方案,跳出了常规思路,解决了大数据量下样本生成的问题
背景
在AI算法模型中的特征穿越问题:原理篇、AI算法模型中的特征穿越问题:工程篇中,我们阐述了模型训练样本生成中的问题——特征穿越,并介绍了几个概要的实现思路。
近日,读到美团技术博客的文章《外卖广告大规模深度学习模型工程实践》(以下简称为“该文章”),其中第5章介绍了美团外卖业务中,样本构建方案选型与改进,给了我很大启发,在此做些笔记。
特征的分类
为了方便陈述问题,我们先定义特征的类别:
- 批式特征:通过批处理作业预计算,并存储于Feature Store供使用,更新频率通常为小时级、天级别
- 流式特征:通过流处理作业预计算,并存储于Feature Store供使用,更新频率通常为秒级、分钟级别
- 即时特征:无法预计算,通常由Feature Store在处理特征请求时,即时完成计算
样本生成过程
以推荐系统为例:
- t0时刻,端侧向推荐服务发起请求,要求为用户u1提供100个最匹配的商品
- t1时刻,服务后端请求召回模型,获得了1000个商品
- t2时刻,服务后端请求该1000个商品以及用户u1的特征,并向排序模型发起请求
- t3时刻,排序模型完成推理,返回排序后的Top100商品
- t4时刻,服务后端返回该100商品,端侧向用户展示商品
- t5时刻,实际仅Top10商品向用户曝光并触发了用户点击,曝光和点击日志回传到服务后端
- t6时刻,根据曝光和点击日志,构建样本,以对排序模型进行再训练或增量训练
样本生成的要求
当生成样本时,特征的时刻要与事件的时刻匹配,不能过早也不能过晚,否则将导致特征穿越。
以如上时间线为例,t2时刻发生了实际的模型推理,这一事件在t6时刻转化成训练样本时,关联的应是t2时刻的特征值,即所谓的Point-in-Time Correct。
不严格的Point-in-Time Correct实现
当t6与t2的时间间隔够小,以至于特征值还未发生变化时,使用t6时刻的特征生成样本也能满足了Point-in-Time要求。
通过曝光和点击日志流式处理+二次特征查询的方式,可以将t6与t2的时间间隔压缩到数秒至数分钟内,详细见AI算法模型中的特征穿越问题:工程篇中的#3。

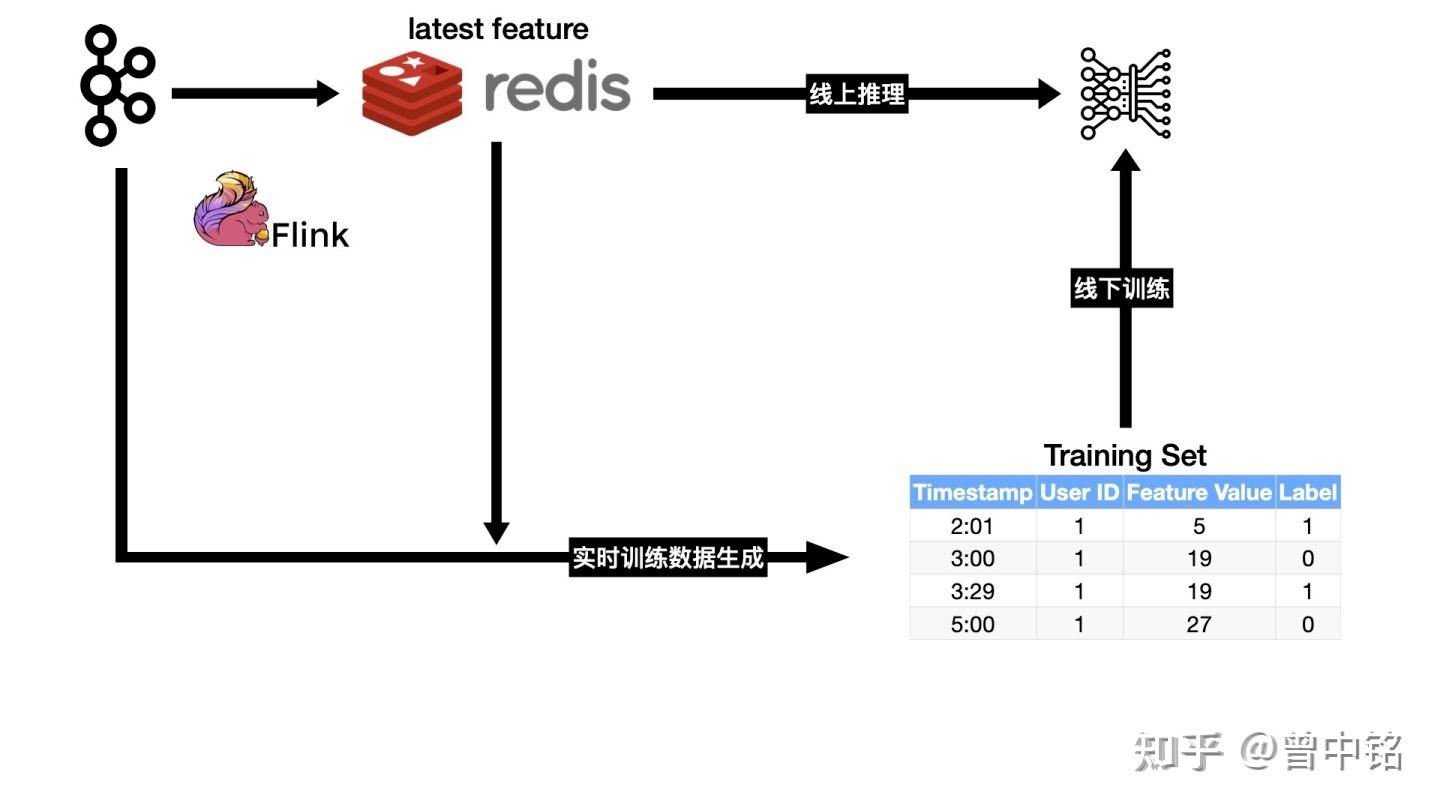
然而,这种方式终究不是严格的Point-in-Time,t6与t2的时间间隔,无论再怎么压缩,都不会降低到0。
因此:
- 对于只使用批式特征的模型,t6与t2的时间间隔远小于特征更新频率,可以认为方案是可靠的;
- 而对于使用了流式特征和即时特征的模型来说,特征更新频率越快,越容易发生特征穿越,不应使用该方案
严格的Point-in-Time Correct实现及其代价
为了完全避免特征穿越,需要将t2时刻,查询到的特征记录成快照,生成样本时Join该特征快照,思路见AI算法模型中的特征穿越问题:工程篇中的#4。
该文章中介绍了三个常见方案:


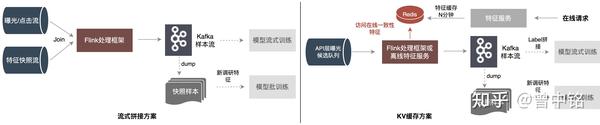

1. 批式拼接方案
特征快照写入离线存储,定时通过批处理实现Join,完成样本生成。
问题:
- 推荐排序系统单次请求可能对数百个商品进行排序,但最终曝光和点击的商品仅数个,导致特征快照数量级远大于曝光/点击流,导致特征快照数据量大,进而导致Join时计算量大
- 批处理方式,样本生成的时效性受限,很难支撑在线学习场景
2. 流式拼接方案
特征快照写入Kafka,通过Flink实现双流Join,完成样本生成。
改用流处理后,样本生成的时效性问题得到解决,但是特征快照数据量大的问题仍未解决,导致:
- 存储特征快照流需要消耗大量Kafka资源;
- Flink中完成双流Join,在窗口内需要缓存所有记录,需要消耗大量内存。
3. KV缓存方案
特征快照写入KV存储(例如Redis)中,并配置自动过期;Flink在处理曝光/点击流时,从KV存储中查询特征快照,进行拼接,完成样本生成。
这一方案将双流Join降级为流表-维表Join,规避了双流Join内存消耗大的问题,但特征快照存储消耗资源的压力仍然存在,而且转移到了更为昂贵的Redis集群上。
美团的答案:先破后立
该文章对流式样本生成过程的瓶颈,进行了细致的拆解分析,最后给出了实现方案的概述。
特征快照数据量消减
通常,特征快照中,同时保存了批式、流式、即时特征。然而,只有流式、即时特征容易引入特征穿越问题。
因此:
- 特征快照中可以只保存流式、即时特征;
- 在样本生成时,再通过二次查询Feature Store补录批式特征
这样一来,特征快照数据量将极大消减,且不影响特征一致性。
Join过程的优化
曝光/点击流与特征Join过程是简单的left join过程,joinKey是明确的,Join的结果要落盘,且没有严格的实效性要求。
如果把joinKey看成数据库的主键,则可以把两表Join过程转化为两表写入数据库的过程:
- 将曝光/点击流和特征快照都以JoinKey为主键,写入Hbase等NoSQL类存储,这一过程中自然完成了Join和落盘过程
- 由于特征快照数量远大于样本数量,因此可以先以Insert方式写入曝光/点击流,延迟数分钟后,再以Update方式写入特征快照,这样既可保证99%+的曝光/点击流都能完成Join,又避免了无用的写入过程
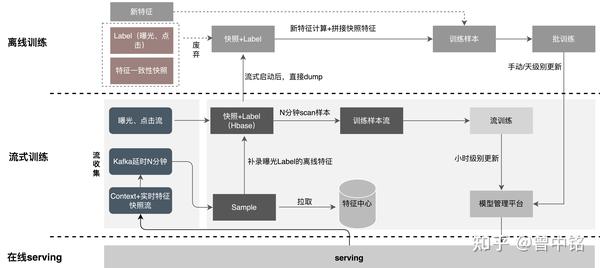
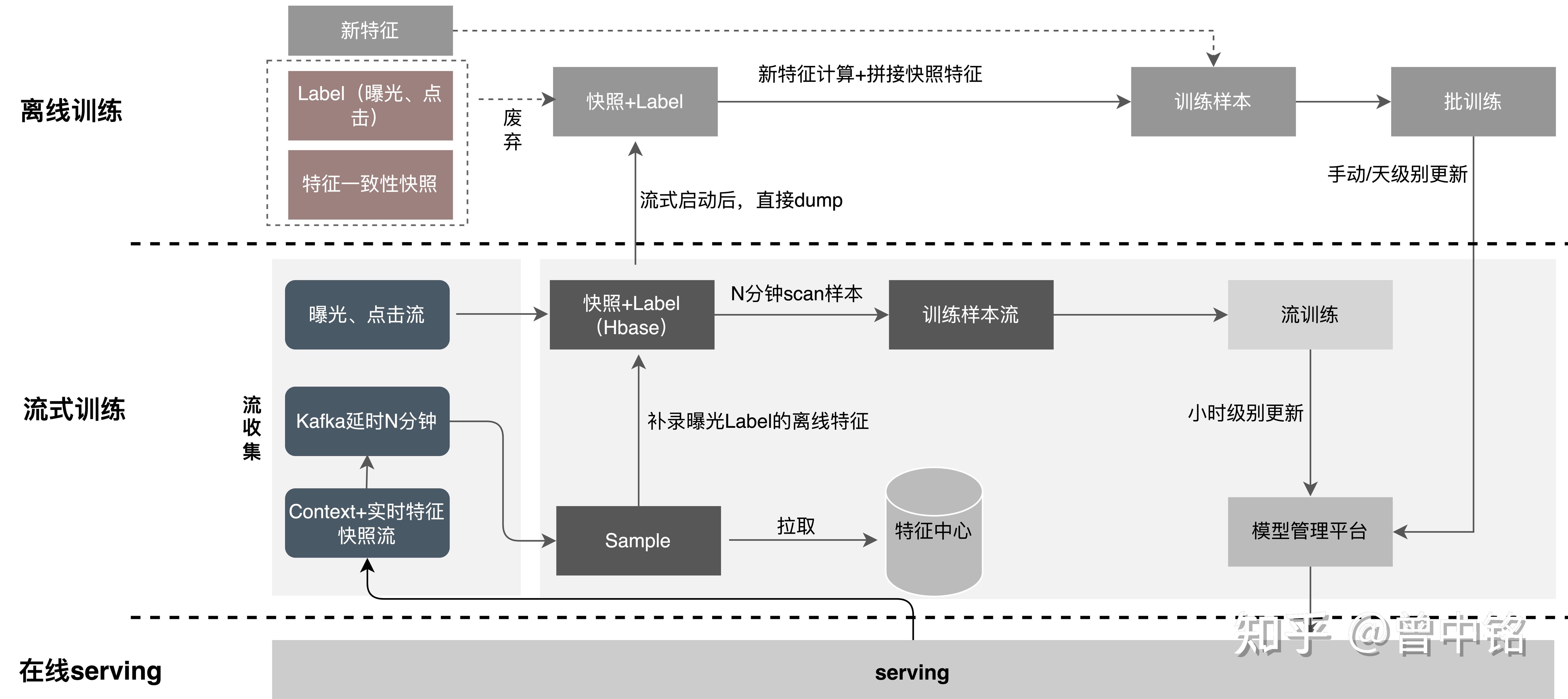
方案实现
美团最终的流式样本生成方案如下图:
- 特征快照中只包含流式、即时特征
- 特征快照写入Kafka
- 曝光/点击流以Insert形式写入Hbase
- 特征快照在Kafka中延迟N分钟后,以Update形式写入Hbase,并在写入过程中,二次访问Feature Store完成批式特征补录
- 从Hbase中抽取样本供在线/离线训练使用
总结
- 样本生成过程中,存在诸多挑战,其中特征穿越是较为棘手的问题,解决方法是,生成样本时使用Point-in-Time Correct特征
- 通过对特征请求进行快照,可以做到Point-in-Time Correct,但在大数据量下,常见的几个方案都各有瓶颈
- 通过对样本生成过程拆解和分析,美团提出了数据拆分+延迟Join方案,巧妙地解决了大数据量下样本生成的问题,令人佩服
参考
外卖广告大规模深度学习模型工程实践 | 美团外卖广告工程实践专题连载 - 美团技术团队 (meituan.com)
