
论文阅读:Attention-Based 意图检测和槽填充

论文链接:
Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
最近在刷论文,看见这篇关于 Slot Filling 的论文引用很高,虽然文章发表的早,但是非常经典,所以找时间简单写下读书笔记。
背景介绍
语义理解有两个重要组成部分。
- 意图识别(Intent Detection)
- 槽填充(Slot Filling)
意图识别是一个基于句子语义的分类问题,槽填充是要读取句子中的一些语义成分,可以看作一个序列标注问题。在 Seq2Seq 模型出来之前一般是对意图检测和槽填充分别用两种模型单独处理,这篇论文提出一个新的模型来同时解决这两个问题。
模型简介
问题定义
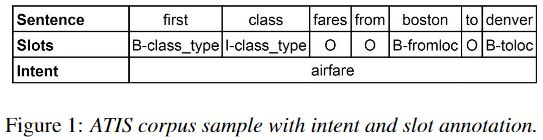

如上图所示,包含 2 个方面,槽填充和意图检测。
槽填充:序列标注问题,具有明确的对齐信息(输入和输出长度一致)。
意图:订机票。
Attention-based Encoder-Decoder 模型
序列标注有明确的对齐信息,所以先没有使用注意力机制。把 x 编码为语义向量 c :
P(y) = \prod_{t=1}^{T} P(y_t|y_{t-1}, c)
这里可以使用 soft-attention 的 Encoder-Decoder 结构。
方法的流程如下:
1. 输入编码
使用双向 LSTM 对输入序列进行编码。
Encoder 部分代码如下所示:
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
USE_CUDA = torch.cuda.is_available()
class Encoder(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, batch_size=16, n_layers=1):
super(Encoder, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.batch_size = batch_size
self.embedding = nn.Embedding(input_size, embedding_size)
self.lstm = nn.LSTM(embedding_size, hidden_size, n_layers, batch_first=True, bidirectional=True)
def init_weights(self):
self.embedding.weight.data.uniform_(-0.1, 0.1)
def init_hidden(self, input):
if USE_CUDA:
hidden = Variable(torch.zeros(self.n_layers*2, input.size(0), self.hidden_size)).cuda()
else:
hidden = Variable(torch.zeros(self.n_layers*2, input.size(0), self.hidden_size))
if USE_CUDA:
context = Variable(torch.zeros(self.n_layers*2, input.size(0), self.hidden_size)).cuda()
else:
context = Variable(torch.zeros(self.n_layers*2, input.size(0), self.hidden_size))
return hidden, context
def forward(self, input, input_masking):
"""
input : B,T
input_masking : B,T
"""
hidden = self.init_hidden(input)
embedded = self.embedding(input)
output, hidden = self.lstm(embedded, hidden)
real_context = []
for i, o in enumerate(output):
# B,T,D
real_length = input_masking[i].data.tolist().count(0)
real_context.append(o[real_length-1])
return output, torch.cat(real_context).view(input.size(0), -1).unsqueeze(1)2. 意图识别
Encoder 最后时刻的隐状态携带了整个句子的信息,使用它进行意图分类。
3. 槽填充
用单向 RNN 作为 Decoder。初始 S_0 = H_t 。论文实验中提到了 3 种方式:
- 只有注意力输入
- 只有对齐输入
- 有注意力和对齐两个输入
下面是论文中的截图
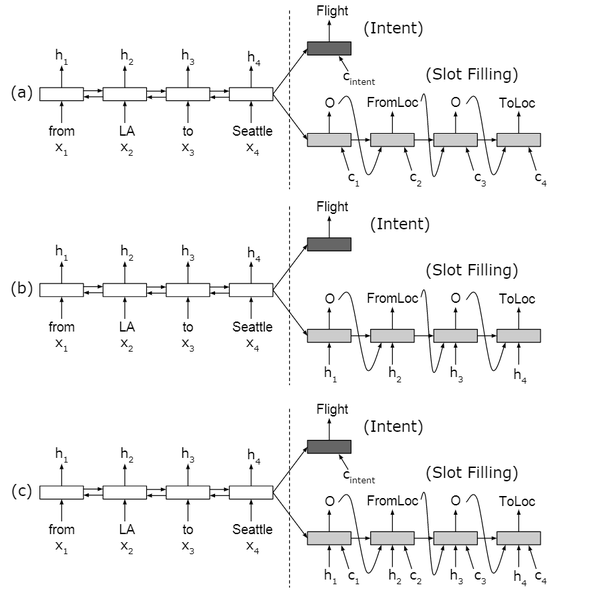

上述第三种方法,带注意力和对齐两种输入的 Decoder
s_0=h_T
计算注意力的上下文 c_i
\alpha_{ij} = softmax(e_{ij})
e_{ij} = g(s_{i-1}, h_k)
c_i = \sum_{j=1}^{T}{\alpha_{ij}h_j}
计算新的状态
si=f(s_{i−1}, y_{i−1}, h_i, c_i)
详细的结构如下图所示,


Decoder 部分代码如下
class Decoder(nn.Module):
def __init__(self, slot_size, intent_size, embedding_size, hidden_size, batch_size=16, n_layers=1, dropout_p=0.1):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.slot_size = slot_size
self.intent_size = intent_size
self.n_layers = n_layers
self.dropout_p = dropout_p
self.embedding_size = embedding_size
self.batch_size = batch_size
# Define the layers
self.embedding = nn.Embedding(self.slot_size, self.embedding_size)
self.lstm = nn.LSTM(self.embedding_size+self.hidden_size*2, self.hidden_size, self.n_layers, batch_first=True)
self.attn = nn.Linear(self.hidden_size, self.hidden_size)
self.slot_out = nn.Linear(self.hidden_size*2, self.slot_size)
self.intent_out = nn.Linear(self.hidden_size*2, self.intent_size)
def init_weights(self):
self.embedding.weight.data.uniform_(-0.1, 0.1)
def Attention(self, hidden, encoder_outputs, encoder_maskings):
"""
hidden : 1,B,D
encoder_outputs : B,T,D
encoder_maskings : B,T
output : B,1,D
"""
# (1,B,D) -> (B,D,1)
hidden = hidden.squeeze(0).unsqueeze(2)
# B
batch_size = encoder_outputs.size(0)
# T
max_len = encoder_outputs.size(1)
# (B*T,D) -> (B*T,D)
energies = self.attn(encoder_outputs.contiguous().view(batch_size * max_len, -1))
# (B*T,D) -> B,T,D
energies = energies.view(batch_size, max_len, -1)
# (B,T,D) * (B,D,1) -> (B,1,T)
attn_energies = energies.bmm(hidden).transpose(1, 2)
# PAD masking
attn_energies = attn_energies.squeeze(1).masked_fill(encoder_maskings, -1e12)
# B,T
alpha = F.softmax(attn_energies)
# B,1,T
alpha = alpha.unsqueeze(1)
# B,1,T * B,T,D => B,1,D
context = alpha.bmm(encoder_outputs)
return context
def init_hidden(self, input):
if USE_CUDA:
hidden = Variable(torch.zeros(self.n_layers, input.size(0), self.hidden_size)).cuda()
else:
hidden = Variable(torch.zeros(self.n_layers, input.size(0), self.hidden_size))
if USE_CUDA:
context = Variable(torch.zeros(self.n_layers, input.size(0), self.hidden_size)).cuda()
else:
context = Variable(torch.zeros(self.n_layers, input.size(0), self.hidden_size))
return hidden, context
def forward(self, input, context, encoder_outputs, encoder_maskings, training=True):
"""
input : B,1
context : B,1,D
encoder_outputs : B,T,D
"""
# B,1 -> B,1,D
embedded = self.embedding(input)
hidden = self.init_hidden(input)
decode = []
# B,T,D -> T,B,D
aligns = encoder_outputs.transpose(0, 1)
# T
length = encoder_outputs.size(1)
for i in range(length):
# B,D -> B,1,D
aligned = aligns[i].unsqueeze(1)
_, hidden = self.lstm(torch.cat((embedded, context, aligned), 2), hidden)
# 用这来做意图识别
if i == 0:
# 1,B,D
intent_hidden = hidden[0].clone()
# B,1,D
intent_context = self.Attention(intent_hidden, encoder_outputs, encoder_maskings)
# 1,B,D
concated = torch.cat((intent_hidden, intent_context.transpose(0, 1)), 2)
# B,D
intent_score = self.intent_out(concated.squeeze(0))
# 1,B,D -> 1,B,2*D
concated = torch.cat((hidden[0], context.transpose(0, 1)), 2)
# B,slot_size
score = self.slot_out(concated.squeeze(0))
softmaxed = F.log_softmax(score)
decode.append(softmaxed)
# B
_, input = torch.max(softmaxed, 1)
# B,1 -> B,1,D
embedded = self.embedding(input.unsqueeze(1))
# B,1,D
context = self.Attention(hidden[0], encoder_outputs, encoder_maskings)
# B,slot_size*T
slot_scores = torch.cat(decode, 1)
# B*T,slot_size
return slot_scores.view(input.size(0)*length, -1), intent_score