
RNN vs LSTM vs GRU -- 该选哪个?

前言
本文的目的不在于讲述基础的公式原理等,而是从全局的角度分析各个RNN及其变体的优劣,最主要的是分析 LSTM 与 GRU 的优劣以帮助我们合理选择。话不多说,let fuck !
从传统 RNN 讲起


RNN 是序列模型,常用来处理文本,这意味着通常来说 RNN 的单元数都是比较多的,随之而来的就是梯度消失,梯度爆炸问题 [1] , 这使得RNN 对长期的依赖关系不敏感(因为梯度消失了),其实就是对长期记忆的丢失。
具体到NLP领域中,通常我们会在 Embedding 层采用双向 LSTM,GRU 对文本进行扫描来获得每个词的上下文表示, 如果我们采用传统的RNN,这就意味着句子的第一个单词对句子最后一个单词不起作用了,这明显是有问题的。
其实传统RNN还有一个小问题, 我们假设在没有梯度消失的情况下,传统的 RNN 真的能很好记住长期记忆吗? 其实依旧有可能不行,因为长期记忆一些信息会被短期记忆掩盖。 以人阅读文章举例来说,当你阅读一段文本,看到结尾时,你能记得多少开始的内容,记得多少结尾的内容呢? 很明显,你对结尾内容记忆清晰,对开头内容记忆模糊。
基于这两个问题,LSTM 提供了很好的解决方案。
LSTM 怎么做的呢?
LSTM 分别采用两大策略来解决上述的缺点。首先,针对梯度消失问题,采用门机制来解决 [1],效果非常好。 而对于短期记忆覆盖长期记忆的问题, LSTM 采用一个 cell state 来保存长期记忆, 再配合门机制对信息进行过滤,从而达到对长期记忆的控制。
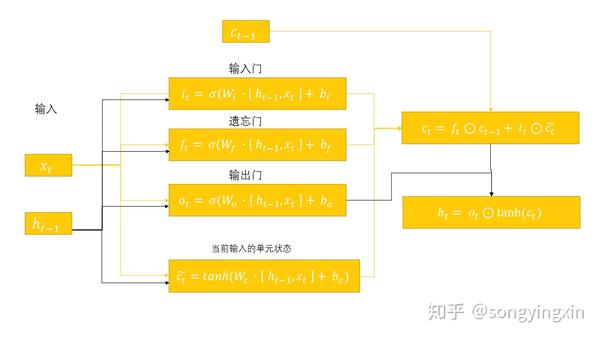
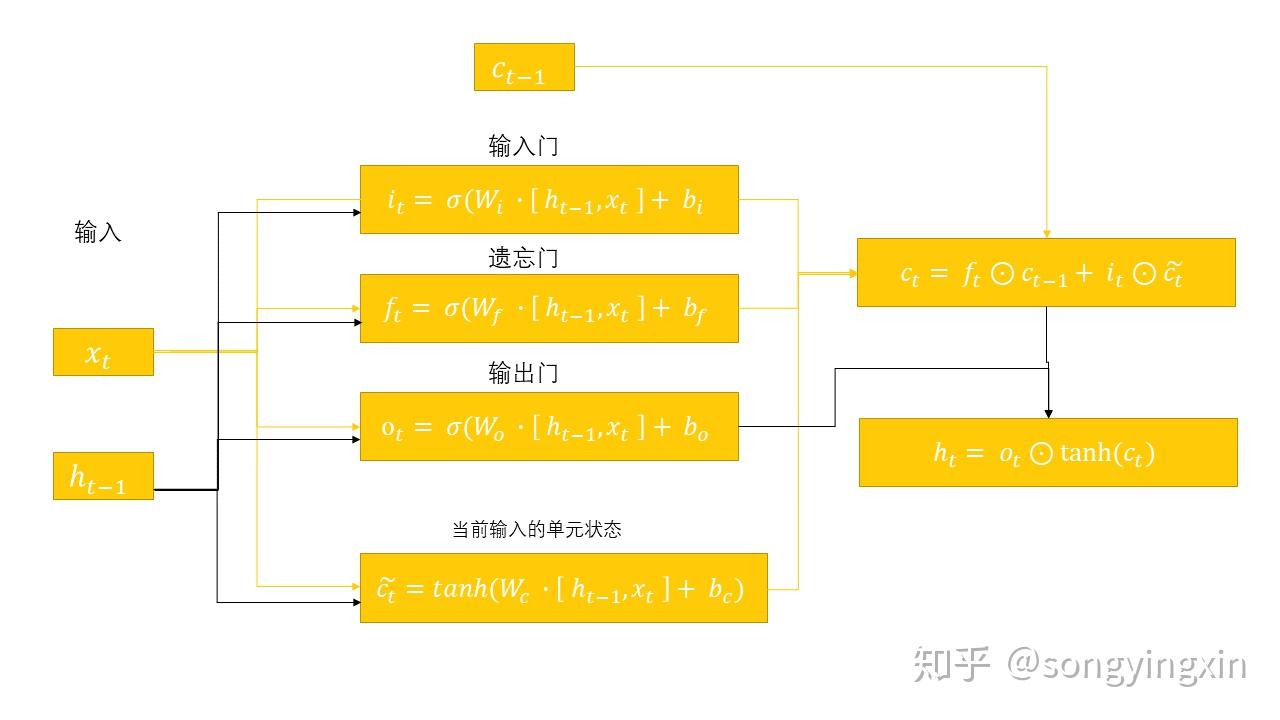
其实理解LSTM 的关键就在于理解门机制与两个状态 h_t 与 c_t 的更新,我们分别来谈一谈。
就我的理解来看,门机制带来了以下两个好处:
- 首先,门机制极大的减轻了梯度消失问题,极大的简化了我们的调参复杂度。
- 其次,门机制提供了特征过滤,将有用的特征保存,没用的特征丢弃,这极大的丰富了我们向量的表示信息。举个NLP中例子而言:“我今天把手机弄丢了,我要买一个新的苹果。”,我现在要将这句话的信息压缩成一个300维的向量中,怎么样才能使得这个向量很好的表示这句话的信息呢? 虽然听上去比较玄学,但是通过特征过滤,最终生成的向量要比传统RNN更能很好的表示句子信息。
我们再来看看 h_t 与 c_t 的传递关系:
- 首先,我们要先理解 h_t 与 c_t 的本质, c_t 本质上是 0 - t 时刻的全局信息,而 h_t 表示的是在 0 - t-1 时刻的全局信息的影响下, 当前 t 时刻的上下文表示。
- 具体到公式中,我们看到 h_t 本质是先将 c_t 经过 tanh 激活函数压缩为 (-1,1)之间的数值,然后再通过输出门对 c_t 进行过滤,来获得当前单元的上下文信息。这意味着当前时刻的上下文信息 h_t 不过是全局信息 c_t 的一部分信息。
而对于全局信息 c_t , 其是由 上一时刻全局信息 c_{t-1} 与当前时刻信息 x_t 通过输入门与遗忘门结合而成的。
GRU 是如何做的?
GRU 是RNN的另一种变体,其与LSTM 都采用了门机制来解决上述问题,不同的是GRU可以视作是LSTM的一种简化版本。我们来对比一下 GRU 与 LSTM 的公式:
- 首先,门的计算公式大同小异,感觉没啥差别。
- 其次,有没有感觉 \tilde{c_t} 与 h'_t 很像,其实是一样的,都是表示当前信息。
- 最后,有没有发现LSTM 中的 c_t 与 GRU 中的 h_t 计算公式相差无几。
那么从公式上看,我们发现 GRU 抛弃了 LSTM 中的 h_t ,它认为既然 c_t 中已经包含了 h_t 中的信息了,那还要 h_t 做什么,于是,它就把 h_t 干掉了。 然后,GRU 又发现,在生成当前时刻的全局信息时,我当前的单元信息与之前的全局信息是此消彼长的关系,直接用 1-z_t 替换 i_t ,简单粗暴又高效 。
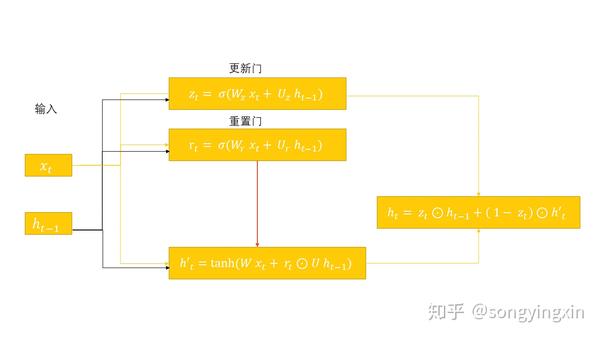
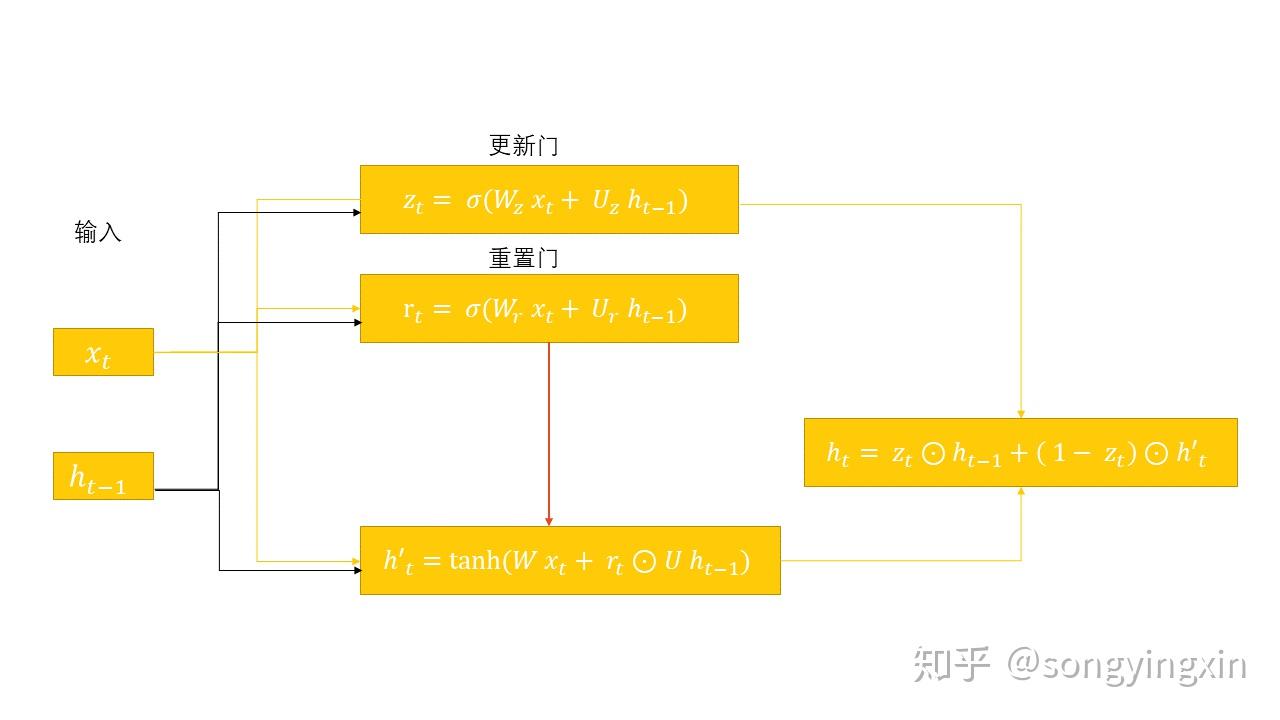
LSTM 与 GRU [5]
这里归纳一下 LSTM 与 GRU 的区别:
- 首先, LSTM 选择暴露部分信息( h_t 才是真正的输出, c_t 只是作为信息载体,并不输出), 而GRU 选择暴露全部信息。
- 另一个区别在于输出变化所带来的结构调整。为了与LSTM的信息流保持一致,重置门本质上是输出门的一种变化,由于输出变了,因此其调整到了计算 h'_t 的过程中。
which one?
首先,可以确定的一件事是带有门机制的 RNN 普遍要比传统的RNN表现更佳,目前,很少有实验或论文来采用普通RNN来作为基本的单元了。
对于 LSTM 与 GRU 而言, 由于 GRU 参数更少,收敛速度更快,因此其实际花费时间要少很多,这可以大大加速了我们的迭代过程。 而从表现上讲,二者之间孰优孰劣并没有定论,这要依据具体的任务和数据集而定,而实际上,二者之间的 performance 差距往往并不大,远没有调参所带来的效果明显,与其争论 LSTM 与 GRU 孰优孰劣, 不如在 LSTM 或 GRU的激活函数(如将tanh改为tanh变体)和权重初始化上功夫。
一般来说,我会选择GRU作为基本的单元,因为其收敛速度快,可以加速试验进程,快速迭代,而我认为快速迭代这一特点很重要。如果实现没其余优化技巧,才会尝试将 GRU 换为 LSTM,看看有没有什么惊喜发生。所以说,深度学习就是玄学。
最后
本文对 GRU 和 LSTM 进行了更深入的探讨,讨论了二者之间的区别以及所带来的变化。值得一提的是,由于RNN是序列模型,其无法并行,因此一般训练起来相当耗时。如果效果不好,可以试试 Transformer,可并行,效果一般会比 RNN要好一些。
Reference
[1] RNN 的梯度消失问题
[2] Supervised Sequence Labelling with Recurrent Neural Networks
[3] LSTM:RNN最常用的变体
[4] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
[5] Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
