
AI Challenger 2018:细粒度用户评论情感分类冠军思路总结

2018年8月-12月,由美团点评、创新工场、搜狗、美图联合主办的“AI Challenger 2018全球AI挑战赛”历经三个多月的激烈角逐,冠军团队从来自全球81个国家、1000多所大学和公司的过万支参赛团队中脱颖而出。其中“后厂村静静”团队-由毕业于北京大学的程惠阁(现已入职美团点评)单人组队,勇夺“细粒度用户评论情感分类”赛道的冠军。本文系程惠阁对于本次参赛的思路总结和经验分享,希望对大家能够有所帮助和启发。


背景
在2018全球AI挑战赛中,美团点评主要负责了其中两个颇具挑战的主赛道赛题:细粒度用户评论情感分析和无人驾驶视觉感知。其中NLP中心负责的细粒度用户评论情感分析赛道,最受欢迎,参赛队伍报名数量最多,约占整个报名团队的五分之一。
细粒度用户评论情感分析赛道提供了6大类、20个细分类的中文情感评论数据,标注规模难度之大,在NLP语料特别是文本分类相关语料中都属于相当罕见,这份数据有着极其重要的科研学术以及工业应用价值(目前在大众点评App已经可以看到20个类别的情感标签了)。
1. 工具介绍
在本次比赛中,采用了自己开发的一个训练框架,来统一处理TensorFlow和PyTorch的模型。在模型代码应用方面,主要基于香港科技大学开源的RNet和MnemonicReader做了相应修改。在比赛后期,还加入了一个基于BERT的模型,从而提升了一些集成的效果。
2. 整体思路
整体将该问题看作20个Aspect的情感多分类问题,采用了传统的文本分类方法,基于LSTM建模文本,End2End多Aspect统一训练。
文本分类是业界一个较为成熟的问题,在2018年2月份,我参加了Kaggle的“作弊文本分类”比赛,当时的冠军团队主要依靠基于翻译的数据增强方法获得了成功。2018年反作弊工作中的一些实践经验,让我意识到,数据是提升文本分类效果的第一关键。因此,我第一时间在网络上寻找到了较大规模的大众点评评论语料,在Kaggle比赛的时候,NLP的语言模型预训练还没有出现,而随着ELMo之类模型的成功,也很期待尝试一下预训练语言模型在这个数据集合上的整体效果。
3. 基础模型思路
首先,尝试了不使用预训练语言模型的基础模型,基于Kaggle Toxic比赛的经验,直接使用了当时表现最好的LSTM Encode + Pooling作为基线模型。在Kaggle的比赛中,大家实验的普遍结果是针对中长文本的分类任务的最佳单模型,都是基于RNN(LSTM/GRU)或者部分基于RNN的模型,比如RCNN、Capsule + RNN这样的模型,而其他的模型,比如单纯的CNN结构相对表现较差,主要可能是因为RNN模型能更好地捕获相对较长距离的顺序信息。
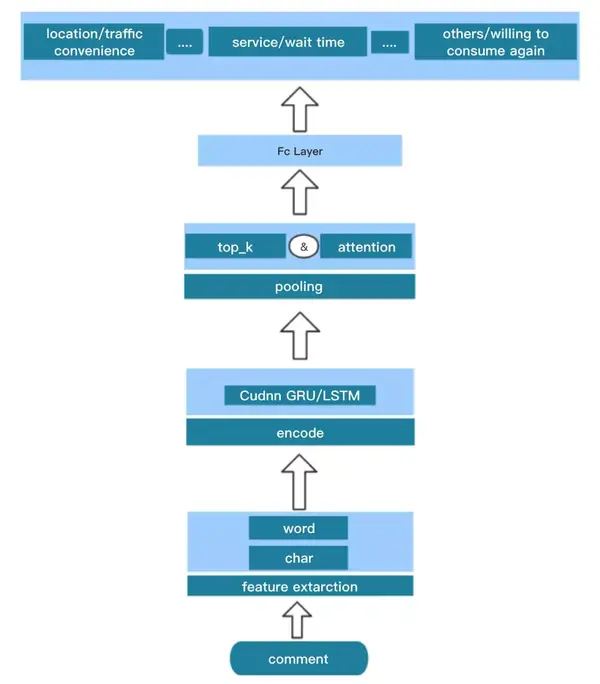

4. 模型层面优化
在基线模型的基础上,效仿阅读理解常见的做法,增加了Self Attention层(计算文本到文本自身的Attention权重),并将Attention之后的输出和原始LSTM输出,采用Gate(RNet)或者Semantic Fusion(MnemonicReader)的方式进行融合。
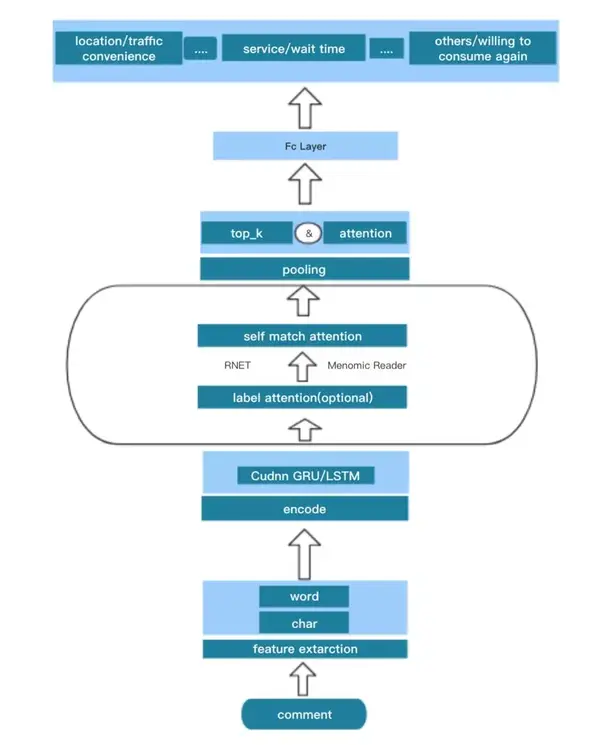

5. 模型细节处理
更宽的参数更多的模型效果更好
- LSTM效果好于GRU。
- Hidden size 400 > 200 > 100。
- Topk Pooling + Attention Pooling的效果好于单独的Max或者Attention Pooling。
- 共享层前置,Pooling层 和最后Fc层不同aspect参数独占效果更好(来自赛后实验,以及其他团队经验)。
这里推测主要原因:是这个数据集有20个Aspect,每个Aspect分4个不同的类别,所需要的参数相对较多。
三角学习率调节效果最佳
- 参考BERT开源代码的学习率设置带来较大效果提升。
采用Word + Char的词建模方式
- 这种建模方式能结合分词和字符粒度切分的好处,最大限度避免词汇UNK带来的损失。
- 注意对比Kaggle Toxic比赛那次比赛是英文语料,对应英文,当时的实验结果是Word + Ngram的建模效果更好,收敛更快,所以针对不同NLP任务,我们需要具体进行分析。
采用尽可能大的词表
和其他团队相比,我采用了更大的词表14.4W(Jieba分词),19.8W(Sentence Piece Unigram分词),依靠外部大众点评评论数据基于fastText预训练词向量,能够支持更大的词表。同时为了避免训练过拟合,采用了只Finetune训练中高频的词对低频词固定词向量的处理方式。
最开始,预计情感相关的词汇相对较少,不需要较大的词表,但是实验过程中发现更大的词表相对地能够提升性能,前提是利用较多的外部数据去比较好的刻画训练数据中低频词的向量。在理论上,我们可以采用一个尽可能大的词表在预测过程中去尽可能的减少UNK的存在(有论文的结论是对应UNK不同的词赋于不同随机向量效果,好于一个固定的UNK向量。这里类似,如果我们赋予一个基于无监督外部数据,通过语言模型训练得到的向量则效果更好)。
6. 预训练语言模型
这部分是模型效果提升的关键,这里采用了ELMo Loss。在简单尝试了官方的ELMo版本之后,感觉速度相对比较慢,为此,采用了自己实现的一个简化版的ELMo,实质上只使用了ELMo的Loss部分。
在当前双层LSTM Encoder的基础上,采用了最小代价的ELMo引入,也就是对当前模型的第一层LSTM进行基于ELMo Loss的预训练,而Finetune的时候,模型结构和之前完全不变,只是第一层LSTM以及词向量部分采用的ELMo预训练的初始化结果,另外在ELMo的训练过程中,也采用了基于fastText的词向量参数初始化。这个设计使得ELMo训练以及Finetune训练的收敛,都加快了很多,只需要大概1小时的ELMo训练,就能在下游任务产生明显受益。值得一提的是,ELMo和Self Attention的搭配在这个数据集合效果非常好。
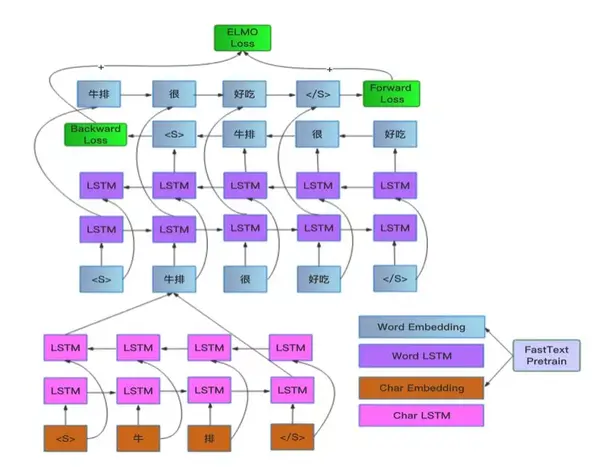

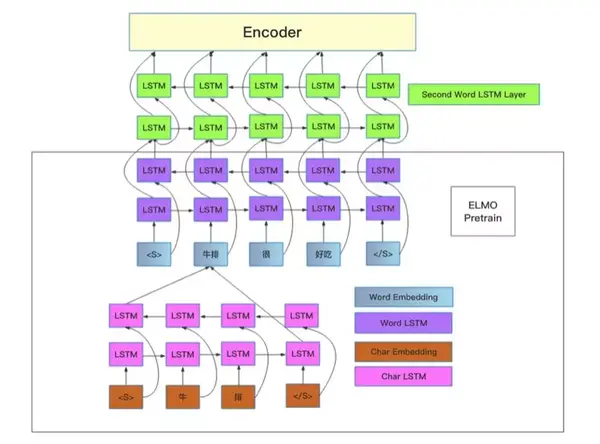

7. 模型集成
为了取得更好的模型多样性,采用了多种粒度的分词方式,在Jieba分词的主要模型基础上,同时引入了基于SentencePiece的多种粒度分词。SentencePiece分词能带来更短的句子长度,但是分词错误相对Jieba略多,容易过拟合,因此采用了只Finetune Char向量,固定词向量的策略来避免过拟合。多种粒度的分词配合Word + Char的建模方式带来了很好的模型多样性。
此外,模型维度的多样性来源自RNet结构和MnemonicReader结构,以及BERT模型的结构的不同。
在模型选择的时候选取了平均F1值最优的轮次模型,集成的时候采用了按Aspect效果分开加权集成的方式(权重来自Valid数据的F1分值排序)。基于以上的多样性策略,只需要7个单模型集成就能取得较好的效果。
8. 关于BERT
在实验中基于Char的BERT单模型,在本次比赛中并没有取得比ELMo更好的效果,受限于512的长度和只基于Char的限制,目前看起来BERT模型在这个数据集合更容易过拟合,Train Loss下降较快,对应Valid Loss效果变差。相信通过适当的优化BERT模型能取得更好的效果。
9. 后续优化
- F1的优化是一个有意思的方向。本次比赛中,没有对此做特殊处理,考虑到F1是一个全局优化值,如果基于Batch强化学习,每个Batch可能很难拟合稀有样本分布。
- BERT的进一步优化。因为BERT出现之前,基于Transformer的模型在长文本分类效果大都是差于基于LSTM的模型的,所以如果我们按照BERT的Loss去预训练基于LSTM而不是Transformer的模型,在分类问题层面的效果如何?另外,在这个数据集合基于Transformer的BERT,能否取得比ELMo更好的分类效果?
对话AI Challenger 2018冠军:程惠阁
Q:谈谈对本次参赛的感受?
程惠阁:作为一个多年的算法从业者,我真实的感受到在AI时代,技术更新非常之快,比如席卷而来的ELMo、BERT等预训练语言模型在工业界影响力之大。包括美团在内的很多公司都快速跟进并上线,而且取得了很好收益,因此技术人员时刻保持学习的心态是非常重要的。
而比赛和工作存在很大的不同,比赛相对更加单纯明确,比赛可以使我在最短时间去学习实验验证一些新的技术,而在标准数据集合验证有效的模型策略,往往在工作中也有实际的价值。对于比赛以及工作中的模型开发,我觉得比较重要的一点首先要做好细致的模型验证部分,在此基础上逐步开发迭代模型才有意义。比如在这次比赛中,我从一开始就监控了包括整体以及各个Aspect的包括F1、AUC、Loss等等各项指标。
Q:对学习算法的新同学有哪些建议?
程惠阁:如果有时间,可以系统地学习一些名校的深度学习相关的课程,还有很重要的一点,就是实践,我们可以参加去学校项目或者去大公司实习,当然也可以利用AI Challenger、Kaggle这样的竞赛平台进行实践。
Q:为什么会选择参加细粒度用户评论情感分类这个赛道?
程惠阁:因为我之前参加过类似的比赛,并且做过文本分类相关的工作,对这个赛道的赛题也比较感兴趣。
Q:本次比赛最有成就感的事情是什么?
程惠阁:不断迭代提升效果带来的成就感吧,特别是简化版ELMo带来的效果提升。
Q:参赛过程中,有哪些收获和成长?
程惠阁:作为一个TensorFlow重度用户,我学会了使用PyTorch并且体验到PyTorch带来的优雅与高效。体验到了预训练语言模型的威力。在比赛中和比赛后,我也收获了很多志同道合的朋友,和他们的交流学习,也帮助我提高了很多。
更重要的是,因为这次比赛,我加入了美团点评这个大家庭,入职这段时间,让我真切地感受到美团点评为了提升用户体验,为了让用户吃的更好,生活更好,在技术方面做了大量的投入。
---------- END ----------

