
【AI】香侬科技提出Glyce模型,打破13项中文机器语言理解记录

编者按:这次小编给大家带来一篇关于NLP(自然语言处理)发展的文章,希望通过这篇文章的阅读,让大家对NLP领域的最新动态有清晰的认识。
文章作者:孟昱先 吴伟
责任编辑:晋杰
文章发表于微信公众号【运筹OR帷幄】:【AI】香侬科技提出Glyce模型,打破13项中文机器语言理解记录
欢迎原链接转发,转载请私信@运筹OR帷幄获取信息,盗版必究。
敬请关注和扩散本专栏及同名公众号,会邀请全球知名学者发布运筹学、人工智能中优化理论等相关干货、知乎Live及行业动态:『运筹OR帷幄』大数据人工智能时代的运筹学
本文经授权转载自公众号香侬科技
让机器读懂人类语言是人工智能领域一个重要的研究方向,并具有很高的商业应用价值,也因此吸引了全世界的科技巨头如Google,Apple, Amazon 投入资源进行深入的研究。国内的大型互联网公司和自然语言处理(NLP)领域的创业公司也都在各自的业务领域进行有针对性的各项研究。NLP领域也因各方的参与,百家争鸣,进展飞速。
香侬科技作为一家金融科技NLP公司,在将NLP技术应用于业务场景的过程中,提出了一个设想:“我们是否能用AI技术提取中文字形中蕴含的丰富语义,帮助人们快速地理解中文的报告、文章和新闻内容呢?”
针对这个设想,香侬科技展开了一系列初步的研究和实验。根据实验结果,香侬科技提出了基于中文字形的深度学习模型 Glyce,并将结果发表在Arxiv上。Glyce模型在13项NLP的任务上取得了目前最好的结果,打破了13项中文NLP的世界纪录。
道阻且长,中文语义理解是一项重要又艰巨的工作。Glyce的工作仅仅是一个开端。香侬科技将最新的研究结果呈现,并希望与各位专家、学者探讨、分享、将中文语义理解的研究深入下去,并在国内实际的业务应用中发挥更大价值。
为什么研究中文字形?
“学汉字真的好难!”身边的外国人常常表达这样的困扰。难懂的文字,造成交流的障碍。虽然今天我们有各种翻译器,可以方便地进行简单的日常沟通。但对于外国人,想要了解中国的经济情况,尤其是阅读中文的财经新闻和行业研究报告,还是难于登天。人工智能领域NLP的多项研究,让人们寄托了厚望。如果机器可以读懂各种中文的报告,那就解决了一个国际交流方面的大问题。
中文和英文其实有一个很大的不同之处。世界上的绝大多数语言,都是拼音文字(alphabetic language), 比如世界上应用广泛的英文、法文、西班牙文、阿拉伯文等。与英文不同,汉字是象形文字(logographic language),也是当今世界上依然被使用的最古老的象形文字。大多数汉字的起源于图形,所以汉字的字形中蕴藏着丰富的语义信息,这一点,是英文所没有的。
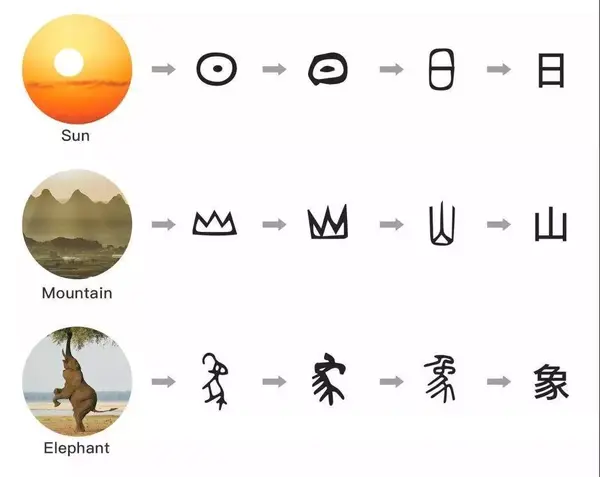

当今中文自然语言处理的方法,大多是基于英文NLP的处理流程,而香侬科技在此次的研究中,提出了基于中文字形的语义表示:把汉字当成一个图片,然后用卷积神经网络学习出语义,这样便可以充分利用汉字中的图形信息,增强了深度学习向量的语意表达能力。
研究过程
当今英文embedding上的研究通常基于word、sub-word及character级别的语义嵌入表示。而在中文上,我们一般停留在word(词)或character(字)级。但注意到中文的character是对应到英文中的sub-word级别,例如词根和词缀。
我们是否能将中文的“字”切分为更小的单位,从而能够从更小的单位中学习到更底层的语义相关性呢?
首先,我们认为可以利用汉字的字形特点。汉字是一种象形文字,在发展的过程中产生了形声、象形等六种构字法,但无论是哪一种构字法,我们都可以从它们的字形中“推测”一个我们不认识的字的含义。显然,汉语字形的信息应该有助于语义建模。但是,一个字很难再被切分为更细的单元,也就没有办法像“字”或者“词”那样去构造字典进行直接的语义嵌入,所以我们考虑采用基于图像的方法去提取汉字的语义特征。
最近也有一些研究注意到了这些事实(Liu et al., 2017; Zhang and LeCun, 2017)。但是令人遗憾的是,他们的研究没有表现出持续的性能提升,一些研究甚至得出了负面效果(Dai and Cai, 2017),字形的加入实际上降低了性能。(Liu et al., 2017; Zhang and LeCun, 2017)在文本分类任务上利用相似的策略测试了这一思路,结果模型性能只在非常有限的几种情况下有所提升。
这是否真的说明,汉字的字形无益甚至有损于语义捕捉和语言建模呢?
我们首先对之前的研究进行总结,发现之前的研究存在改进的空间:


针对以上问题,我们提出了Glyce,一种汉字字形的表征向量。我们仍然将汉字当作图像,并使用CNN来获取语义表征,但是试图用以下方法来解决上述三个问题:


Glyce介绍:
基于中文字形的NLP模型
l 使用历史汉字
我们首先使用了不同历史时期的中文字符:如今广泛使用的简体中文字符是经过漫长的历史演变而来的。简体中文书写更加方便,但是同时也丢失了大量的原始图形信息。Glyce提出需要运用不同历史时期的中文字符,从周商时期的金文,汉代的隶书,魏晋时期的篆书,南北朝时期的魏碑,以及繁体、简体中文。这些不同类别的字符在语义上更全面涵盖了语义信息。


l 提出Tianzige(田字格)-CNN架构
标准的CNN结构接受一个三维图像输入,然后使用n*n的卷积核和max-pooling去提取特征。然而,直接使用这样的Deep CNN结构会导致“逆改善”,因为:
● 汉字图像的尺寸一般很小。比如ImageNet的图像都是800*600,●而中文汉字的尺寸往往只需要用一个12*12的灰度图便可以表示。尺寸上的巨大差异并不能使传统的CNN结构通用。
● 训练数据大小的限制。ImageNet有巨大的训练集,而汉字却只有大概一万个。


为此,我们提出了Tianzige-CNN结构。Tianzige(田字格)是中文传统的书写方式,它由2*2的小正方形组成(见上图左)。田字格结构反映了中文偏旁部首的排列组合顺序,所以非常适合中文字形信息提取。
现在给定输入x ,首先用一个大小为5的卷积核去做卷积,得到一个1024通道的输出,然后用大小为4的max-pooling将8*8的特征图降为2*2的Tianzige尺寸。现在,这个2*2的Tianzige结构表示了汉字的字形特征。最后,我们用group convolution(Krizhevsky et al. 2017; Zhang et al. 2017) 得到汉字的字形表征向量。(见上图右)
l 加入图像分类损失函数
为了进一步减少过拟合,我们使用了图像分类作为附加的损失函数。汉字图像 x 通过Tianzige-CNN得到的汉字字形特征向量 h直接被送去预测它是哪个汉字。假定 x 对应的汉字标签是 z ,那么图像分类的损失函数为:


l 字嵌入与词嵌入
为了将字形信息和传统的词向量和字向量结合起来,我们针对词级别的任务和字级别的任务,提出了两种Glyce模型结构。模型的结构总览如下
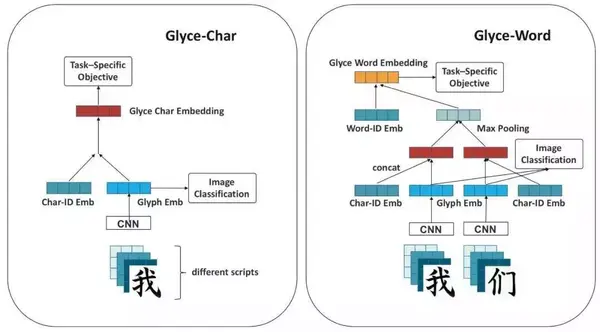

在字级别的任务中,可以首先通过上述方法得到一个Glyph Embedding,然后和对应的Char Embedding结合起来,具体可以使用concat,highway或者全连接,然后送入下游任务。
在词级别的任务中,我们首先有一个Word Embedding,对这个词而言,分别对其中的每一个字进行字级别的embedding操作,把所有的字级别的embedding用max-pooling结合起来,然后再和这个Word Embedding结合,送入下游任务。
实验结果
我们在语言建模、NER、MT等13个任务上进行了实验,并与其他模型进行了对比。下面我们重点分析几个任务的结果。
首先在字级和词级的语言建模上进行了实验。数据集使用了CTB6,采用标准的LSTM结构。实验结果如下
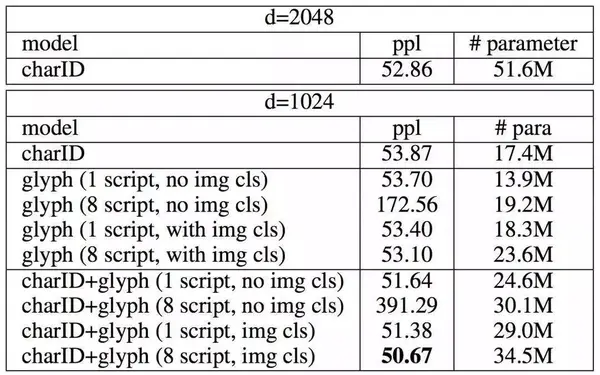



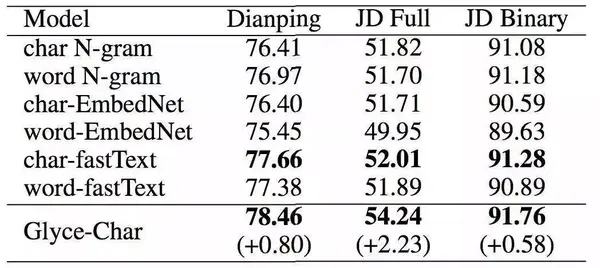
从上述两个任务的实验中我们可以看到,只用汉字字形图像(glyph)比只用字(charID)或只用词(wordID)要好,这验证了中文汉字的字形特征的确可以通过合理的模型结构来获得更好的语义信息。在词级任务上,我们发现,无论是charID还是wordID,它们都能通过附加glyph达到更好的效果,特别地,使用wordID+glyph到达了词级的最好效果。我们认为,这可能是因为相比charID,glyph已经能够提供足够好的语义信息,而再加上charID反而使这种信息更加混乱。
另外,上图第一个表格也展示了附加图像分类损失的作用。我们发现,使用图像分类比不使用图像分类损失效果普遍更好,特别是在字体多达8的时候。如果此时没有附加的图像分类作为学习目标,各种各样的字体信息就会混杂在一起,从而误导模型的学习方向,极大降低学习效果。在字级任务上,我们使用charID+glyph+8 scripts+图像分类损失达到了最好。
然后我们在命名实体识别(Named Entity Recognition)、中文分词(Word Segmentation)和词性标注(Part of Speech Tagging)上进行了实验。实验结果如下


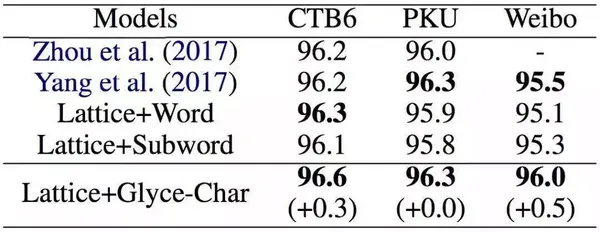

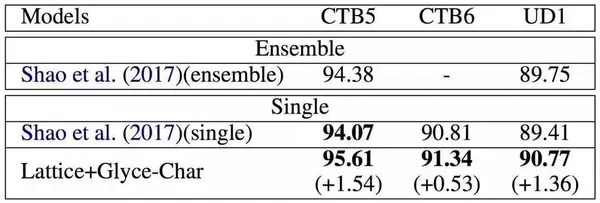


中文词性标注上的表现
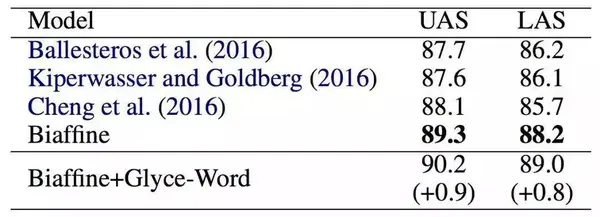
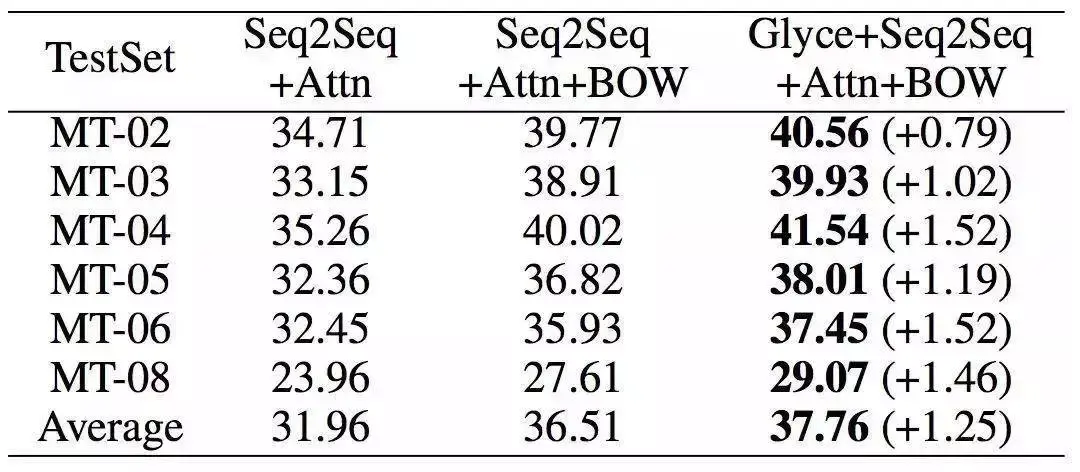
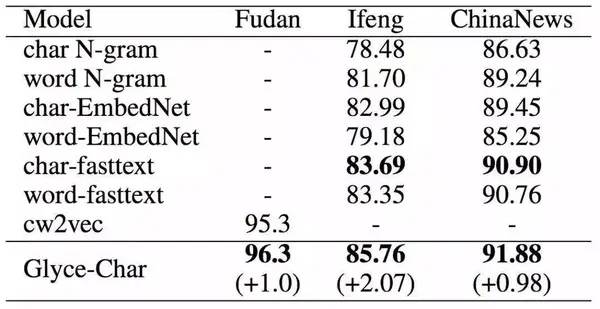
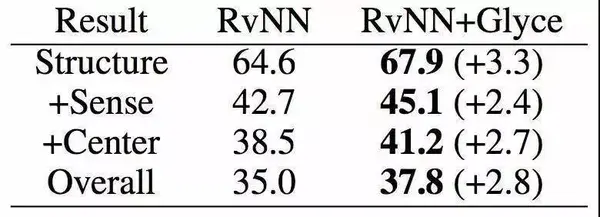
接着,我们又在依存句法分析(Dependency Parsing)、语义角色标注(Semantic Role Labeling)、句子语义相似匹配(Sentence Semantic Similarity)、意图识别(Intention Identification)、中英翻译(Chinese-English Machine Translation)、情感分析(Sentiment Analysis)、文档分类(Document Classification)、语篇分析(Discourse Parsing)等任务上进行了实验,实验结果如下,详细实验过程详见论文。
Glyce在依存句法分析和一些模型的对比及表现
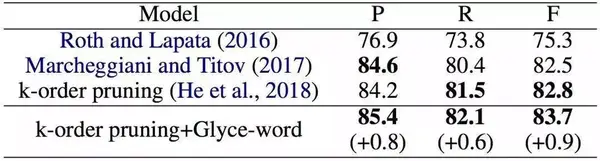

SRL和一些模型的对比及表现
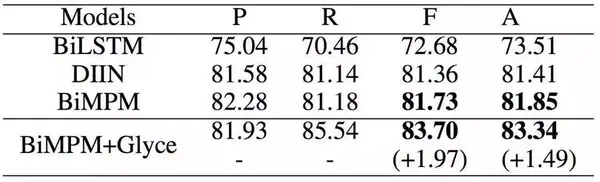

句子语义相似匹配和一些模型的对比及表现





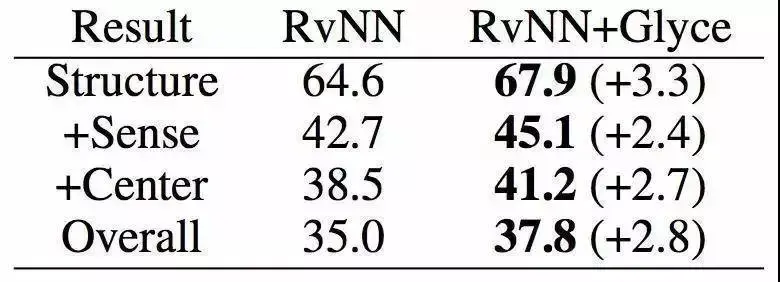
结语
香侬科技提出了一种基于中文字形表示的语义模型,针对中文特殊的字形结构设计了Tianzige-CNN结构来捕捉字级语义,并且使用不同历史时期的汉字来增强这种能力,加入了图像分类任务更好地进行泛化。实验表明我们提出的Glyce模型能够更好地构建中文字级、词级的语义表示,在多项任务中实现SOTA。
道阻且长,中文语义理解是一项重要又艰巨的工作。 Glyce的工作仅仅是一个开端,香侬科技希望能为以中文为代表的象形文字在构建更好的语义表示上的研究提供一些启发,并希望与各位专家和学者探讨、分享,并能国内AI落地业务应用中发挥更大价值。
参与研究人员
参与本次研究的共有九位同学:
Yuxian Meng(孟昱先)与Wei Wu(吴炜)并列为第一作者。Wei Wu(吴炜)在字符级语言模型任务上设计并实现了第一个Glyce-char模型。Yuxian Meng(孟昱先)提出了Tianzige- CNN结构,图像分类作为辅助目标函数和衰变λ。Jiwei Li(李纪为)提出使用不同历史时期的中文字符。Yuxian Meng(孟昱先)负责词级语言模型和意图分类的结果; Wei Wu(吴炜)负责中文分词,命名实体识别和词性标注的结果。Qinghong Han(韩庆宏)负责语义角色标注的结果;Xiaoya LI(李晓雅)负责中文-英文机器翻译的结果; Muiry Li(李慕宇)负责句法依存分析和词性标注的结果;Mei Jie(梅杰)负责篇章分析的结果;Nie Ping(聂平)负责语义相似度的结果; Xiaofei Sun(孙晓飞)负责文本分类和情感分析的结果。Jiwei Li(李纪为)为Glyce通讯作者。
文章由作者授权由『运筹OR帷幄』转载发布
如需转载请在公众号后台获取转载须知
AI板块副主编招聘要求:
1.计算机视觉、语音识别、自然语言处理方向硕士毕业或博士在读,及以上学历也可。
2.有文字编辑经验,博客或知乎专栏写作经历,善于沟通与协调
3.有时间,有责任心,保证每周工作 2-3个小时
扫二维码关注『运筹OR帷幄』公众号:




