
炼丹师的工程修养之四: TensorFlow的分布式训练和K8S

接之前的文章:
1 分布式训练的基本原理
无论是TensorFlow还是其他的几种机器学习框架,分布式训练的基本原理是相同的。大致可以从以下五个不同的角度来分类。
- 并行模式
- 架构模式
- 同步范式
- 物理架构
- 通信技术
1.1并行模式
通俗的讲,分布式计算就是通过分布式的多台机器,把原来的巨大的,复杂的问题拆成多个小的、简单的问题来解决。对于机器学习的训练任务,原来的“大”问题主要表现在两个方面。一是模型太大,我们需要把模型“拆”成多个小模型分布到不同的Worker机器上;二是数据太大,我们需要把数据“拆”成多个更小的数据分布到不同Worker上。前者我们称为模型并行,后者称为数据并行。
数据并行相对来说更简单一些,N台分布式Worker,每台只处理1/N的数据,理想情况下能达到近似线性的加速效果,大多数的机器学习框架都原生支持或者改动很小就可以支持数据并行模式。
模型并行相对复杂一点,对于TensorFlow这类基于计算图的框架而言,可以通过对计算图的分析,把原计算图拆成多个最小依赖子图分别放置到不同的Worker上,同时在多个子图之间插入通信算子(Send/Recieve)来实现模型并行。由于模型并行本身的复杂性,加之开发调试困难,同时对模型本身的结构也有一定要求,在工业应用中,大部分还是以数据并行为主。
1.2架构模式
通过模型并行或数据并行解决了“大问题”的可行性,接下来考虑“正确性”。以数据并行为例,当集群中的每台机器只看到1/N的数据的时候,我们需要一种机制在多个机器之间同步信息(梯度),来保证分布式训练的效果与非分布式是一致的(N * 1/N == N)。相对成熟的做法主要有基于参数服务器(ParameterServer)和基于规约(Reduce)两种模式。还有基于MPI的方式,但是互联网中使用的比较少。
参数服务器非常容易理解,就是有一台/组机器只用来存储参数和梯度,其他所有的Worker与PS服务器通信,把自己的梯度上传(Push)到PS,PS把所有Worker的梯度收集计算(通常是求均值),然后各Worker再从PS拉回(Pull)更新后的参数/梯度并应用到自己的参数上。参数服务器的主要问题是多个Worker同时跟PS通信,PS本身有可能成为瓶颈,随着Worker数量的增加,整体的通信量也线性增加,加速比可能会停滞在某个点位上。


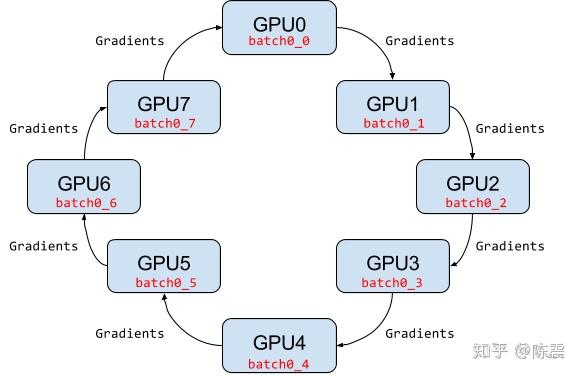
基于规约的模式解决了上述问题。比较典型的一种规约方式是Ring-AllReduce(2017年百度提出)。如下图,多个Worker节点连接成一个环,每个Worker依次把自己的梯度同步给下一个Worker,经过至多2*(N-1)轮同步,就可以完成所有Worker的梯度更新。这种方式下所有节点的地位是平等的,因此不存在某个节点的负载瓶颈,随着Worker的增加,整体的通信量并不随着增加。加速比几乎可以跟机器数量成线性关系且不存在明显瓶颈。目前,越来越多的分布式训练采用Reduce这种模式。

1.3 同步范式
在梯度同步时还要考虑“木桶”效应,即集群中的某些Worker比其他的更慢的时候,导致计算快的Worker需要等待慢的Worker,整个集群的速度上限受限于最慢机器的速度。因此梯度的更新一般有同步(Sync)、异步(Async)和混合三种范式。
同步模式就是刚刚提到的,只有当所有的Worker完成计算后,才开始进行下一轮迭代。
异步模式刚好相反,每个Worker只关心自己,完成计算后就尝试更新,能跟其他多少个Worker“互通有无”完全看运气。这种机制避免了木桶效应,但是其过程非常不可控,有可能出现正确性问题。
混合模式结合上面两种方式,各个Worker都会等待其他Worker的完成,但不是永远等待。这里有一个”超时“的机制。这个超时机制可以是超过某个时间,也可以是到达某个最小副本数。如果”超时“了,等待的Worker就只用当前获取到的梯度来更新并继续下一个迭代,避免无意义的等待。而没来得及完成计算的Worker,其梯度则被标记为”stale“而抛弃或另作处理。
1.4 物理架构
接下来是物理层面,这里主要指基于GPU的部署架构,基本上分为两种:单机多卡和多机多卡(单机单卡很简单,多机单卡没有代表性,这里就不讨论了)
单机多卡即训练任务在一台服务器上,利用同一台服务器上的多个GPU卡实现分布式训练。既可以是数据并行,也可以是模型并行。整个训练任务一般只有一个进程,多块GPU卡的分布式通过多线程的方式通信,模型参数和梯度在进程内是共享的(基于NCCL的不太一样,后面讨论),因此不再需要一个显式的PS,一般通过进程内的Reduce即可完成梯度同步。
多机多卡要复杂一些,但是抽象来看,多台机器间是典型的分布式,需要某种进程间的通信机制(下面讨论)。如果只看某一台机器,那么则与单机多卡是相同的。TensorFlow的计算图在执行之前会有“分裂”的操作,也是分为两步:先按照Worker(TensorFlow中叫Job)分裂到多个机器上,再按照设备(Device)分裂到多个GPU卡上(CPU同理)。
1.5 通信技术
接下来具体到通信技术,主要讨论分布式条件下多进程、多Worker间如何通信,常见的技术有MPI,NCCL,GRPC,RDMA等,逐一介绍下。
MPI被广泛应用在科学计算尤其是超算领域解决大规模计算问题,但是在机器学习尤其是互联网中应用比较少,主要原因有两点:一是MPI的容错性很差,用在超算这种高度稳定的集群中可以,但是互联网的大数据集群是x86服务器,时刻都可能出现稳定性问题,一旦某个节点出现故障,整个训练任务都将失败;二是MPI的通信是All2All,就是说每台机器都要跟其他所有机器进行通信,通信的复杂度是N2,当机器数大量增加时其通信成本将不可接受。
NCCL(NVIDIA Collective Communications Library),是Nvidia针对其GPU实现的规约库,可以实现多GPU间的直接数据同步,避免内存和显存的,CPU和GPU间的数据拷贝成本。当在TensorFlow中选择单机多卡训练时,其默认采用的就是NCCL方式来通信。我对NCCL不是很懂,不作过多介绍,详情可以参考官网
GRPC已经是成熟的进程间通信技术,这里就不啰嗦了。一般环境下的TensorFlow在分布式训练,默认使用GRPC在多台机器间进行数据通信。
RDMA严格意义上讲跟上面三个不在同一个维度,关于RDMA可以参考这篇文章:深入浅出全面解析RDMA
2 TensorFlow的分布式训练
2.1 TensorFlow分布式训练的几种方法
花了好大篇幅把分布式训练的一些基础知识介绍下。还是原来的观点,把基础知识了解清楚之后再到实践层面或API层面,才是合格的“调包侠”。
虽然TensorFlow有各种各样的问题,但是不可否认,TensorFlow仍然是目前对分布式训练支持最完善和最稳定(虽然也很不稳定)的机器学习框架了。加上TensorFlow的社区活跃,谷歌爸爸大力支持,很多分布式特性都能比较快速的支持。但是其分布式训练的API也是一边再变。如果想通过TensorFlow来分布式训练,基本上有以下三种方法:
- Customer Train Loop
- Estimator + Strategy
- Keras + Strategy
2.1.1 Customer Train Loop
第一种方法也是最原生的方法,就是整个分布式训练的过程完全交给工程师来编程处理。这里有个例子,介绍了如何在PS架构下分布式训练MNIST。整个代码比较复杂,用到了很多高级API和我们前面提到的概念。这里我们把代码拆开,只保留最主要的部分来解释:
def main():
# 从环境变量中读取TF_CONFIG,这个JSON字符串描述了整个集群的配置情况
tf_config = json.loads(os.environ.get('TF_CONFIG') or '{}')
cluster_config = tf_config.get('cluster', {})
# 参数服务器的地址
ps_hosts = cluster_config.get('ps')
# Worker的地址
worker_hosts = cluster_config.get('worker')
# 使用集群配置,分别在各个节点上启动Server,这个Server负责与其他所有节点的通信
server = tf.train.Server(
cluster, job_name=job_name, task_index=task_index)
# 如果当前节点是PS节点,join等待。PS节点的代码执行到此就没有了
if job_name == "ps":
server.join()
# 以下是Worker节点执行的代码
# 默认情况下,第一个Worker节点是chief节点,chief除了要计算外,还要负责计算图的初始化和分配,
# 模型文件保存、恢复等管理类的工作
is_chief = (task_index == 0)
# 各个节点根据配置信息,生成设备描述,CPU和GPU的设备描述不一样,分别处理
if num_gpus > 0:
gpu = (task_index % num_gpus)
worker_device = "/job:worker/task:%d/gpu:%d" % (task_index, gpu)
elif num_gpus == 0:
cpu = 0
worker_device = "/job:worker/task:%d/cpu:%d" % (task_index, cpu)
# 使用tf.device这个Context Manager指定接下来所有的操作都在这个设备上面
with tf.device(
tf.train.replica_device_setter(
worker_device=worker_device,
ps_device="/job:ps/cpu:0",
cluster=cluster)):
# 构建模型,省略
...
cross_entropy = ...
# 创建优化器
opt = tf.train.AdamOptimizer(learning_rate)
# 如果是同步更新模式,使用TF的SyncReplicasOptimizer包装原来的优化器
# 该优化器有两个重要的参数,replicas_to_aggregate和total_num_replicas,这两个参数有三种可能:
# 1)如果replicas_to_aggregate < total_num_replicas,表示PS只需要接收到replicas_to_aggregate多个batch的梯度就可以更新,
# 而剩下的部分可以丢弃,实际上起到备份的作用,当某个batch失败了,任务还可以继续进行
# 2)如果replicas_to_aggregate > total_num_replicas,表示PS要接收到多于total_num_replicas数量的梯度才会更新,这可以看做是“能者多劳”模式,
# 即如果集群中有某些Worker的性能更高,那么可以允许其比其他Worker多计算一些batch,充分利用其性能
# 3)如果replicas_to_aggregate = total_num_replicas,其实就是“公平模式”,要求必须接收到规定数量的梯度才会更新
if sync_replicas:
opt = tf.train.SyncReplicasOptimizer(
opt,
replicas_to_aggregate=replicas_to_aggregate,
total_num_replicas=num_workers,
name="mnist_sync_replicas")
# 最终的训练OP
train_step = opt.minimize(cross_entropy, global_step=global_step)
# 同步模式下,需要显式的初始化几个OP
if sync_replicas:
local_init_op = opt.local_step_init_op
if is_chief:
local_init_op = opt.chief_init_op
ready_for_local_init_op = opt.ready_for_local_init_op
# chief节点需要借助一个QueueRunner来完成同步操作
chief_queue_runner = opt.get_chief_queue_runner()
sync_init_op = opt.get_init_tokens_op()
init_op = tf.global_variables_initializer()
# 借助Supervisor类帮助进行训练初始化和部分管理工作,如果是同步模式,则需要多传入两个参数
if sync_replicas:
sv = tf.train.Supervisor(
is_chief=is_chief,
logdir=train_dir,
init_op=init_op,
local_init_op=local_init_op,
ready_for_local_init_op=ready_for_local_init_op,
recovery_wait_secs=1,
global_step=global_step)
else:
sv = tf.train.Supervisor(
is_chief=is_chief,
logdir=train_dir,
init_op=init_op,
recovery_wait_secs=1,
global_step=global_step)
# 创建Session的配置对象
sess_config = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False,
device_filters=["/job:ps",
"/job:worker/task:%d" % task_index])
# 如果是chief节点,手动初始化sync_init_op并启动QueueRunner
if sync_replicas and is_chief:
# Chief worker will start the chief queue runner and call the init op.
sess.run(sync_init_op)
sv.start_queue_runners(sess, [chief_queue_runner])
# 开始训练的迭代,与单机训练无异
while True:
# Training feed
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
train_feed = {x: batch_xs, y_: batch_ys}
_, step = sess.run([train_step, global_step], feed_dict=train_feed)我们在上面用注释把主要的逻辑解释了。这里需要强调两个地方。
第一个是TF_CONFIG环境变量,这个环境变量将在后面持续出现。其实这个环境变量也没什么神奇,就是TensorFlow定义的一段JSON来描述集群的配置信息。在cluster中定义了PS节点的地址和Worker节点的地址,这部分所有的机器是一样的。在task中,定义了当前机器的类型和索引,这部分每一台机器要根据情况来修改。这个JSON可以通过环境变量的方式传递给我们的程序,也可以通过其他命令行参数,配置文件等方式,甚至不遵守这个格式都可以(可以在代码里构造)。但是通过环境变量的方式,可以无缝的使用后续的Estimator,Keras的机制,所以还是推荐这种做法。
{
"cluster": {
"ps": [
"host1:2222"
],
"worker": [
"host2:3333",
"host3:3333",
"host3:4444"
]
},
"task": {
"index": 0,
"type": "ps"
}
}第二个重点就是tf.train.SyncReplicasOptimizer这个类,这个类实现了分布式训练中如何进行梯度收集和更新等复杂的操作。通过控制replicas_to_aggregate和 total_num_replicas两个参数,可以实现不同的同步更新策略:
- 如果replicas_to_aggregate < total_num_replicas,表示PS只需要接收到replicas_to_aggregate多个batch的梯度就可以更新,而剩下的部分可以丢弃,实际上起到备份的作用,当某个batch失败了,任务还可以继续进行
- 如果replicas_to_aggregate > total_num_replicas,表示PS要接收到多于total_num_replicas数量的梯度才会更新,这可以看做是“能者多劳”模式, 即如果集群中有某些Worker的性能更高,那么可以允许其比其他Worker多计算一些batch,充分利用其性能
- 如果replicas_to_aggregate = total_num_replicas,其实就是“公平模式”,要求必须接收到规定数量的梯度才会更新
SyncReplicasOptimizer这个类已经被标记为deprecated,不被推荐使用了。
2.1.2 Estimator + Strategy
第一种做法相对底层而繁琐,因此对开发要求比较高,使用起来不太方便。所以TensorFlow提供了第二种方法,使用Estimator和Strategy方式。
Estimator是TensorFlow提供的一个高级API,把数据准备,计算图搭建,训练训练,预测评估和模型保存等常见操作抽象成一个类,避免工程师编写大量的同质代码。关于Estimator的介绍和使用我们不在这里介绍了,详情参考官网。
Strategy是TensorFlow针对分布式训练的复杂性,抽象出来的多种分布式训练的策略(官网介绍),当前提供了六种策略,分别是:
- MirroredStrategy:这个策略支持单机多卡、数据并行、同步更新的分布式训练,采用的是Reduce的模式,在多块卡之间默认通过NCCL完成规约通信
- CentralStrorageStrategy:这个策略简单一些,支持的是单机CPU或单机多卡的数据并行、同步更新的训练。跟MirroredStrategy不同的地方是,如果有多块GPU,那么CPU充当了PS的角色,类似PS结构的分布式训练。如果只有一块GPU,那么权值和Op均放在GPU上。
- MultiWorkerMirroredStrategy:这个策略类似于MirroredStrategy,不同的地方是这个策略支持多台机器,也就是支持多机多卡、数据并行、同步更新的分布式训练,同样采用了Reduce的模式。该模式的规约操作使用了一个叫CollectiveOps的算子,这个算子实际使用的通信技术会根据不同的软硬件和网络环境来选择,比如机器间通信可能采用GRPC或者RDMA,同一台机器多个GPU间可能采用NCCL等。根据介绍说这个策略还对性能做了优化,比如把多个小tensor的reduce操作优化为一个大tensor的操作。注意:在r1.15版本里,这个策略叫CollectiveAllReduceStrategy
- ParameterServerStrategy:这个策略不用多介绍了,就是经典的PS架构,支持多机多卡,数据并行,同步+异步更新,通信技术不太确定,应该是GRPC。
- OneDeviceStrategy:这个策略可以指定某个设置来构建计算图,主要用来开发调试用的,不多说了
- TPUStrategy:针对谷歌自家的TPU,没用过,也不多说了
上面这些策略基本上支持了前面介绍到的多种分布式训练的模式、机制和技术。在当前版本的TensorFlow(v1.15 v2.0)中,有些Strategy还处于试验阶段,相信后面会更完善,也可能出现更多样的策略。
下面看一下如何使用Estimator+Strategy实现分布式训练,还是看代码:
# 数据准备和输入,略过
def input_fn():
...
def main(args):
# 构建计算图模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(16, activation='relu', input_shape=(10,)))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
# 创建优化器并compile模型
optimizer = tf.train.GradientDescentOptimizer(0.2)
model.compile(loss='binary_crossentropy', optimizer=optimizer)
model.summary()
tf.keras.backend.set_learning_phase(True)
# 创建estimator的运行配置,在experimental_distribute参数里可以分别为训练和评估指定不同的策略
# 这里我们指定在训练时用MultiWorkerMirroredStrategy策略,也可以使用其他的策略,比如ParameterServerStrategy等
config = tf.estimator.RunConfig(
experimental_distribute=tf.contrib.distribute.DistributeConfig(
train_distribute=tf.contrib.distribute.MultiWorkerMirroredStrategy(
num_gpus_per_worker=0),
eval_distribute=tf.contrib.distribute.MirroredStrategy(
num_gpus_per_worker=0)))
# 构建estimator对象
keras_estimator = tf.keras.estimator.model_to_estimator(
keras_model=model, config=config, model_dir=model_dir)
# 使用estimator启动分布式训练和评估
tf.estimator.train_and_evaluate(
keras_estimator,
train_spec=tf.estimator.TrainSpec(input_fn=input_fn),
eval_spec=tf.estimator.EvalSpec(input_fn=input_fn))相较于第一种原生的方法,基于Estimator和Strategy的方式大大简化了分布式训练的步骤和代码。这里还缺少了一个环节,那就是集群的配置在代码里没有体现。对了!仍是采用TF_CONFIG环境变量的方式。Strategy会自动读取环境变量中的TF_CONFIG信息并正确解析用于分布式训练集群的配置,是不是很方便。
如果不传入,则默认是单机的训练。这里就不再详细介绍TF_CONFIG了。
2.1.3 Keras + Strategy
最后一种是TensorFlow最新的方案,也是官方推荐的方式。利用Keras这种高层的API,配合Strategy来实现多种模式的分布式训练。直接看代码:
# 数据准备
def make_datasets_unbatched():
...
train_datasets = make_datasets_unbatched().batch(BATCH_SIZE)
#使用Keras API构建计算图模型,指定loss函数和优化器
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
...
])
model.compile(
loss=tf.keras.losses.sparse_categorical_crossentropy,
optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'])
return model
# 通过Context Manager指定使用MultiWorkerMirroredStrategy策略,所有在这个Context下的操作,默认使用了该策略
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with strategy.scope():
# 这时才构建数据准备相关的Tensor和Op
train_datasets = make_datasets_unbatched().batch(GLOBAL_BATCH_SIZE)
# 这时才构建模型训练相关的Tensor和Op
multi_worker_model = build_and_compile_cnn_model()
# 启动模型训练
multi_worker_model.fit(x=train_datasets, epochs=3, steps_per_epoch=5)这种方法的代码看起来更简洁,使用Context Manager方式也更符合python的编程习惯。这里需要注意,一定要先创建好相应的Strategy的Context后再创建相关的Tensor和Op,否则就失去作用了。
跟第二种模式一样,分布式集群的配置信息仍然是通过TF_CONFIG来传入,Strategy会自动读取环境变量并正确应用配置中的信息。
2.1.4 三种方法的比较
上面我们介绍了三种常见的分布式训练的方法,这三种方法是随着TensorFlow的发展而逐步出现的,每一种都有其特定的历史背景。而且从现在看,每一种也都有一些局限性。官方是希望大家使用第三种并在这个基础上持续更新。以下是官方给的一个兼容性列表。Strategy应该会是TensorFlow长期支持的一种分布式训练的设计模式。


2.2 手工配置分布式训练
通过上面的介绍,启动TensorFlow的分布式训练已经变得很简单了。代码写好之后,只需要正确配置好TF_CONFIG并在各个节点上作为环境变量传递给相应的进程就可以了。我们采用第三种方法测试一下。这里有两台服务器,在第一台服务器上启动一个Worker0,第二台服务器启动两个Worker1和Worker2,组成一个3 Workers的集群,分布式训练使用MultiWorkerMirroredStrategy策略,即Reduce模式的,数据并行、同步更新方法。
在HOST1通过以下方式启动第一个Worker
$ TF_CONFIG='{"cluster":{"worker":["p20677v.hulk.shbt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:4444"]},"task":{"index":0,"type":"worker"}}' python keras_with_strategy.py
2019-12-17 16:53:55.420119: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:250] Initialize GrpcChannelCache for job worker -> {0 -> localhost:3333, 1 -> k3711v.add.bjyt.qihoo.net:3333, 2 -> k3711v.add.bjyt.qihoo.net:4444}
2019-12-17 16:53:55.425259: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:365] Started server with target: grpc://localhost:3333
2019-12-17 16:53:55.425350: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:369] Server already started (target: grpc://localhost:3333)在HOST2通过以下方式启动第二个Worker
$ TF_CONFIG='{"cluster":{"worker":["p20677v.hulk.shbt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:4444"]},"task":{"index":1,"type":"worker"}}' python keras_with_strategy.py
2019-12-17 16:55:49.359229: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:250] Initialize GrpcChannelCache for job worker -> {0 -> p20677v.hulk.shbt.qihoo.net:3333, 1 -> localhost:3333, 2 -> k3711v.add.bjyt.qihoo.net:4444}
2019-12-17 16:55:49.362287: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:365] Started server with target: grpc://localhost:3333
2019-12-17 16:55:49.362364: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:369] Server already started (target: grpc://localhost:3333)在HOST2通过以下方式启动第三个Worker
$ TF_CONFIG='{"cluster":{"worker":["p20677v.hulk.shbt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:3333","k3711v.add.bjyt.qihoo.net:4444"]},"task":{"index":2,"type":"worker"}}' python keras_with_strategy.py
2019-12-17 16:58:32.681871: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:250] Initialize GrpcChannelCache for job worker -> {0 -> p20677v.hulk.shbt.qihoo.net:3333, 1 -> k3711v.add.bjyt.qihoo.net:3333, 2 -> localhost:4444}
2019-12-17 16:58:32.684099: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:365] Started server with target: grpc://localhost:4444
2019-12-17 16:58:32.684137: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:369] Server already started (target: grpc://localhost:4444)三个Worker的启动方法几乎一样,唯一的区别是index不一样。当三个Worker都启动起来之后,训练会正式开始并打印出日志。
1303/20000 [>.............................] - ETA: 9:33 - loss: 2.0348 - acc: 0.41912.3 小结
到这里,我们就把TensorFlow的分布式训练的原理、方法和实践介绍完了。整体而言,TensorFlow对分布式训练的支持还是非常好的,仍然比其他各种框架都要全面。但是稳定性可能还是需要大家在实践中来验证了,至少基于我们的经验,还是有很多的坑要爬的。
上面的这种手工启动分布式训练的方法在真正的工业环境中是不太可行的,我们最好依赖某种资源调度框架来完成训练集群的资源申请,然后基于申请到的计算资源再启动分布式训练任务。所以接下来我们用K8S试一下。
3 使用K8S进行TensorFlow分布式训练
3.1 构建Docker镜像
这里没有什么特别的,编写Dockerfile构建Docker镜像,然后推送到阿里云
FROM tensorflow/tensorflow:1.15.0
RUN pip install tensorflow_datasets -i https://pypi.douban.com/simple
ADD . /root
WORKDIR /root
ENTRYPOINT ["python", "/root/keras_with_strategy.py"]3.2 编写K8S Job YAML并启动
在上一篇文章中Kubernetes微服务和简单的机器学习训练,我们介绍了如何使用K8S的Job来运行一个单机的训练任务,这次我们依然采用这个方式。不同的是,我们需要启动三个Job,作为三个TensorFlow的Worker并且让他们互相配合来完成分布式训练。由于三个Job的配置是不一样的,因此我们要生成三份配置文件。以下是为Worker-0编写的配置。
apiVersion: batch/v1
kind: Job
metadata:
name: worker-0
spec:
template:
spec:
containers:
- name: worker-0
image: registry.cn-hangzhou.aliyuncs.com/chenzhen-docker-repo/keras_with_stragety:v3
env:
- name: TF_CONFIG
value: '{"cluster":{"worker":["????:3333","????:3333","????:3333"]},"task":{"index":0,"type":"worker"}}'
ports:
- containerPort: 3333
restartPolicy: Never
backoffLimit: 4我们定义这个Job的名字叫worker-0,这个Job使用的是我们刚刚build好的Docker镜像。我们定义容器对外暴露的端口号是3333,最重要的地方是,我们通过env这个参数把TF_CONFIG传递给容器,从而实现集群配置信息的传递。
但是问题来了:在这个Job被K8S调度启动之前,我们是无法确定自己和其他两个Job的IP的。即便知道了这一次的IP,当再次运行时,K8S又会随机使用其他的IP。既无法预知又时刻变化,TF_CONFIG该如何定义呢????
看过之前文章的话这里可能会想到,我们可以利用K8S Service机制,为每一个Job定义一个唯一的入口。那么看一下这个Service该如何编写:
kind: Service
apiVersion: v1
metadata:
name: keras-with-strategy-worker-0
spec:
type: LoadBalancer
selector:
job-name: worker-0
ports:
- port: 3333其实很简单,我们定义一个名为keras-with-strategy-worker-0的LoadBalancer Service,让其指向worker-0这个具体的Job。如何精确“指向”呢?Selector机制。在Service中定义一个selector,通过job-name: worker-0这个过滤器,就可以精确的找到worker-0这个Job。这里有个隐藏的点,我们在定义Job时并没有使用Label,但是K8S在调度时会自动为Job增加一个job-name: worker-0这样的Label。因此在Service的selector定义中直接使用就好了。
现在,我们可以通过Service的名字,唯一且不变的代表了一个TensorFlow Worker。现在TF_CONFIG就容易定义了:
...
- name: TF_CONFIG
value: '{"cluster":{"worker":["keras-with-strategy-worker-0:3333","keras-with-strategy-worker-1:3333","keras-with-strategy-worker-2:3333"]},"task":{"index":0,"type":"worker"}}'
...接下来,为另外两个Worker分别定义其Job和Service的配置,这个很简单不赘述了。运行一下看看,分别创建了三个Service,每个Service分别“指向”一个Job。每个Job的本质是对应的一个Pod,而每个Pod就是一个TensorFlow的Worker。通过查看Pod的日志,我们相信这个训练任务已经跑起来了。
$ kubectl create -f worker_0.yaml
service/keras-with-strategy-worker-0 created
job.batch/worker-0 created
$ kubectl create -f worker_1.yaml
service/keras-with-strategy-worker-1 created
job.batch/worker-1 created
$ kubectl create -f worker_2.yaml
service/keras-with-strategy-worker-2 created
job.batch/worker-2 created
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
keras-with-strategy-worker-0 LoadBalancer 10.100.27.222 <pending> 3333:31342/TCP 16s
keras-with-strategy-worker-1 LoadBalancer 10.107.229.30 <pending> 3333:32135/TCP 10s
keras-with-strategy-worker-2 LoadBalancer 10.106.108.169 <pending> 3333:30083/TCP 7s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 35d
$ kubectl get job
NAME COMPLETIONS DURATION AGE
worker-0 0/1 3m 3m
worker-1 0/1 2m54s 2m54s
worker-2 0/1 2m51s 2m51s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
worker-0-2mgx4 1/1 Running 0 3m19s
worker-1-jvqff 1/1 Running 0 3m13s
worker-2-5xrkq 1/1 Running 0 3m10s
$ kubectl logs -f worker-0-2mgx4
...
Train on 20000 steps
Epoch 1/5
1324/20000 [>.............................] - ETA: 12:26 - loss: 1.9863 - acc: 0.46783.3 小结
到这里,我们介绍了用K8S来进行TensorFlow的分布式训练,如果想用其他的框架比如PyTorch,XgBoost等,其背后的原理也是如此。目前这个做法有什么问题吗?其实没什么大问题,主要还是太麻烦了。
我们需要针对多个Job分别编写相应的配置文件,要通过Service机制解决IP不确定的问题,每个Job的TF_CONFIG也要修改(仅仅改index一个地方)。如果是PS架构,配置起来可能还要更麻烦一些。
当然,这些配置文件的结构一致,内容大部分是相同的,因此你可能会想到,我们完全可以把变化的部分抽象出来作为参数,使用jinja之类的工具在运行前动态渲染生成出一堆配置文件,然后再扔给K8S就好了,这里就有例子。如果你真的这么想,恭喜恭喜!你已经领悟到KubeFlow的精髓了 ;)
接下来,终于轮到这次的主角:KubeFlow。老规矩,放到下一次分享... = =!
参考资料
https://www.oreilly.com/ideas/distributed-tensorflow
https://developer.nvidia.com/nccl
又啰啰嗦嗦了这么多,还没写完....继续挖坑...2019年结束之前,一定全填上!
后续:
继续做广告:
这本书是我们team的小伙伴 觉非老师 出版的,每一个字,每一幅图都是亲自书写绘制,从初稿完成到最终出版整整花了一年的时间,不断调整校对。我们内部也从头到尾一起过了两遍。整本书的思路比较有趣,目的是介绍机器学习和深度学习理论,但更希望能借此书,提倡崇尚科学,破除深度学习迷信。相信不会让各位失望,大家捧场 ; )
