
OpenAI GPT2原理解读

终于读上了GPT2,我觉得整体的思想对我来说高级的,一些新闻或者文章上可能给大家最多的印象就是它参数多了、训练数据多了,然后生成的文本很牛逼,但是我读了论文之后反而觉得模型尺寸与数据只是一方面,它的思想才是最重要的,下面主要围绕两个问题展开解析:
- 论文题目《Language Models are Unsupervised Multitask Learners》到底是什么意思?
- GPT2(单向Transformer)和BERT(双向Transformer)到底有什么区别?
正文分割线
1. GPT2模型
1.1 模型思想
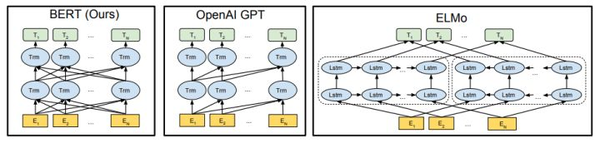
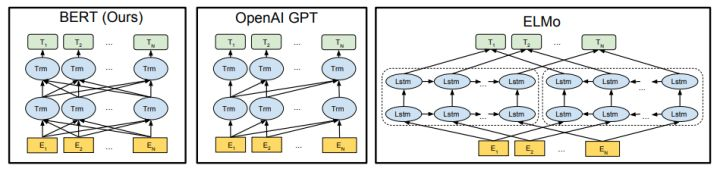
GPT2的核心思想就是认为可以用无监督的预训练模型去做有监督任务。GPT2模型的结构还是和GPT一样,如上图中间部分,它所适用的任务恰好是语言模型,即预测 p(s_n|s_1, s_2, ...,s_{n-1}) ,这是大家再熟悉不过的公式。那为什么这个就能做有监督任务呢?平常的套路难道不是语言模型预训练+微调吗?反正当时我是一脸懵逼的,反复看了两三遍才理透这个逻辑,下面我给大家梳理一下,如果这个思想懂了,那上面的问题就不是问题了。
按照原文的思路,作者是这样论述的:
- 语言模型其实也是在给序列的条件概率建模,即 p(s_{n-k}, ..., s_n|s_1, s_2, ...,s_{n-k-1})
- 任何的有监督任务,其实都是在估计 p(output|input) ,通常我们会用特定的网络结构去给任务建模,但如果要做通用模型,它需要对 p(output|input, task) 建模。对于NLP任务的input和output,我们平常都可以用向量表示,而对于task,其实也是一样的。18年已经有研究对task进行过建模了,这种模型的一条训练样本可以表示为 (translate\ to\ french, english\ text, french\ text) ,或者表示为 (answer\ the\ question, document, question, answer) 。也就是说,已经证实了,以这种数据形式可以有监督地训练一个single model,其实也就是对一个模型进行有监督的多任务学习。
- 语言模型=无监督多任务学习。相比于有监督的多任务学习,语言模型只是不需要显示地定义哪些字段是要预测的输出,所以,实际上有监督的输出只是语言模型序列中的一个子集。举个例子,比如我在训练语言模型时,有一句话“The translation of word Machine Learning in chinese is 机器学习”,那在训练完这句话时,语言模型就自然地将翻译任务和任务的输入输出都学到了。再比如,又碰到一句话“美国的总统是特朗普”,这一句话训练完,也就是一个小的问答了。
没理解的话,多看几遍或者看一下原文,解释的更为详细。
如果以上思想懂了,那文章开始的两个问题就迎刃而解:第一个问题答案就是上面的三点。那单向Transformer和双向Transformer的区别,我认为主要是目标函数的区别,因为BERT的Masked language model是对 p(s_k|s_1, .., s_{k-1}, s_{k+1}, ..., s_n) 进行建模,这个建模思想的区别,也就使得目前的BERT无法做 p(output|input, task) 这样的任务。
上面就是GPT2的主要思想,下面讲一下其他细节。
1.2 其他细节
1.2.1 Training dataset
目前大部分的数据集都是针对特定任务的,而GPT2需要的是带有任务信息的数据,因此作者搜集了40GB的高质量语料进行训练。
1.2.2 Input representation
Word-level去做embedding的话需要解决OOV的问题,char-level的话又没有word-level做出的模型好,作者选择了一种折中的办法,将罕见词拆分为子词,参考论文《Neural Machine Translation of Rare Words with Subword Units》。
1.2.3 Model
主要有以下改动:
- Layer norm放到了每个sub-block前(我还是有些没懂具体在哪里,之后看下源码)
- 残差层的参数初始化根据网络深度进行调节
- 扩大了字典、输入序列长度、batchsize
2. 总结
我觉得GPT2还是蛮惊喜的,首先是它爆出的生成文本真的写得好,还有就是整个模型的思想,提出了“NLP通用模型”。从Word2Vec->ELMo->GPT->BERT->MT-DNN->GPT2,可以看出NLP技术越来越倾向于用更少的有监督数据+更多的无监督数据去训练模型,而GPT2也在一定程度上解释了为什么用language model预训练出的模型有更好的效果和泛化性能。
希望NLP技术越来越好~
具体的实验结果我还没有细看,稍后会继续读论文完善这篇文章,如果有问题希望大家指证鸭。

