
Spring事务管理(二)分布式事务管理之JTA与链式事务


本文作者:皮皮哥
什么是分布式事务
跨库的事务就属于分布式事务,比如对两个库的不同表同时修改和同时rollback等。
上一节中,我们只是演示了单个库(数据源)的事务处理。这一节主要讲如何处理多个数据源的事务。
为什么多数据源下不能使用普通事务来处理呢?
我想很多人都有这个问题,打个比方,分库分表后有个数据库A和数据库B,A中有抢票记录,B中有票数记录。当我们完成抢票功能,需要在B减少票数的同时在A中增加记录。但是如果有下面的代码发生:
@Transactional
public void multiDBTX(){
B.reduce(ticketId);
if (true){
throw new RuntimeException("throw new exception");
}
A.save(result);
}我在B扣除票数后抛出异常,然后执行A库添加记录。
如果没有分布式事务处理,则结果就是B票数扣除,但A没有保存记录。也就是出错后B并没有进行事务回滚。
那问题来了,怎么才能实现我们的要求呢。
分布式事务原则
CAP定理
web无法同时满足以下三点:
- 一致性: 所有数据变动都是同步的
- 可用性: 每个操作都必须有预期的响应
- 分区容错性: 出现单个节点无法可用,系统依然正常对外提供服务
BASE理论
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果。核心思想是即使无法做到强一致性,但可以使用一些技术手段达到最终一致。
- Basically Available(基本可用):允许系统发生故障时,损失一部分可用性。
- Soft state(软状态):允许数据同步存在延迟。
- Eventually consistent(最终一致性): 不需要保持强一致性,最终一致即可。
那如何来实现分布式事务管理呢?
分布式事务管理实践
1. JTA实现
事务有效的屏蔽了底层事务资源,使应用可以以透明的方式参入到事务处理中,但是与本地事务相比,XA 协议的系统开销大
在这里我先带大家走出一个误解,你在网上搜JTA一般都是分布式事务用它,但是它就是用来做分布式事务的吗?不是的,我在上文说过,JTA只是Java实现XA事务的一个规范,我们在第一节Spring事务管理(一)快速入门中用到的事务,都可以叫JTA事务管理。下面主要说JTA实现分布式事务管理:
这里我们会用到Atomikos事务管理器,它是一个开源的事务管理器,实现了XA的一种分布式事务处理并可以嵌入到你的SpringBoot当中。
拓展:什么是XA
基本上所有的数据库都会支持XA事务,百度百科上说法:XA协议由Tuxedo首先提出的,并交给X/Open组织,作为资源管理器(数据库)与事务管理器的接口标准。简单的说,它是事务的标准,JTA也是它标准的java实现。
1.1 导入pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>1.2 设置数据源
SpringBoot设置多数据源这里只说下思路(重点还是说事务实现):
- 在
application.yml中配置多数据源配置。 - 写配置类加载配置并放入DataSource并设置事务:
@Configuration
@DependsOn("transactionManager")
@EnableJpaRepositories(basePackages = "com.fantj.repository.user", entityManagerFactoryRef = "userEntityManager", transactionManagerRef = "transactionManager")
@EnableConfigurationProperties(UserDatasourceProperties.class)
public class UserConfig {
@Autowired
private JpaVendorAdapter jpaVendorAdapter;
// 这里注入 dataSource信息的类
@Autowired
private UserDatasourceProperties userDatasourceProperties;
@Bean(name = "userDataSource")
public DataSource userDataSource() {
// 给XADataSource 设置 DataSource 属性
MysqlXADataSource mysqlXaDataSource = new MysqlXADataSource();
mysqlXaDataSource.setURL(userDatasourceProperties.getUrl());
mysqlXaDataSource.setUser(userDatasourceProperties.getUser());
mysqlXaDataSource.setPassword(userDatasourceProperties.getPassword());
mysqlXaDataSource.setPinGlobalTxToPhysicalConnection(true);
// 创建 Atomiko, 并将 mysql的XA交给JTA管理
AtomikosDataSourceBean xaDataSource = new AtomikosDataSourceBean();
xaDataSource.setXaDataSource(mysqlXaDataSource);
// 设置唯一资源名
xaDataSource.setUniqueResourceName("datasource2");
return xaDataSource;
}
@Bean(name = "userEntityManager")
@DependsOn("transactionManager")
public LocalContainerEntityManagerFactoryBean userEntityManager() throws Throwable {
HashMap<String, Object> properties = new HashMap<String, Object>();
properties.put("hibernate.transaction.jta.platform", AtomikosJtaPlatform.class.getName());
properties.put("javax.persistence.transactionType", "JTA");
LocalContainerEntityManagerFactoryBean entityManager = new LocalContainerEntityManagerFactoryBean();
// 给工厂bean设置 资源加载属性
entityManager.setJtaDataSource(userDataSource());
entityManager.setJpaVendorAdapter(jpaVendorAdapter);
entityManager.setPackagesToScan("com.fantj.pojo.user");
entityManager.setPersistenceUnitName("userPersistenceUnit");
entityManager.setJpaPropertyMap(properties);
return entityManager;
}
}这只是一个数据源的配置,第二个数据源的配置也类似,注意不能同Entity同Repository,映射放在不同包下实现。
两个都返回LocalContainerEntityManagerFactoryBean它便会交给@Transaction去管理,两个数据源配置完后。这样的代码B将会回滚。
@Transactional
public void multiDBTX(){
B.reduce(ticketId);
if (true){
throw new RuntimeException("throw new exception");
}
A.save(result);
}1.3 JTA缺点
因为JTA采用两阶段提交方式,第一次是预备阶段,第二次才是正式提交。当第一次提交出现错误,则整个事务出现回滚,一个事务的时间可能会较长,因为它要跨越多个 数据库 多个数据资源的的操作,所以在性能上可能会造成吞吐量低。而且,它只能用在单个服务内。一个完善的JTA事务还需要同时考虑很多元素,这只是个示例。
2. 链式事务管理
链式事务就是声明一个ChainedTransactionManager 将所有的数据源事务按顺序放到该对象中,则事务会按相反的顺序来执行事务。
网上发现了一个链式事务管理的处理顺序,总结的很到位。
1.start message transaction
2.receive message
3.start database transaction
4.update database
5.commit database transaction
6.commit message transaction ##当这一步出现错误时,上面的因为已经commit,所以不会rollback可以看到,从345可以看到,它后拿到的事务先提交,这就导致如果1出错,则不会进行数据回滚。跟Spring的同步事务差不多,同步事务也是这种特性。
下面我会测试这个性质。
为了方便,我拿JdbcTemplate来测试该事务。
DBConfig.java
配置DataSource以及返回Template新实例和链式事务配置。
/**
* DB配置类
*/
@Configuration
public class DBConfig {
/**
* user-DB配置
*/
@Bean
@Primary
@ConfigurationProperties(prefix = "spring.datasource.user")
public DataSourceProperties userDataSourceProperties(){
return new DataSourceProperties();
}
@Bean
@Primary
public DataSource userDataSource(){
return userDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean
public JdbcTemplate userJdbcTemplate(@Qualifier("userDataSource") DataSource userDataSource){
return new JdbcTemplate(userDataSource);
}
/**
* result-DB配置
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.result")
public DataSourceProperties resultDataSourceProperties(){
return new DataSourceProperties();
}
@Bean
public DataSource resultDataSource(){
return resultDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean
public JdbcTemplate resultJdbcTemplate(@Qualifier("resultDataSource") DataSource resultDataSource){
return new JdbcTemplate(resultDataSource);
}
/**
* 链式事务配置
*/
@Bean
public PlatformTransactionManager transactionManager(){
DataSourceTransactionManager userTM = new DataSourceTransactionManager(userDataSource());
DataSourceTransactionManager resultTM = new DataSourceTransactionManager(resultDataSource());
return new ChainedTransactionManager(userTM,resultTM);
}
}transactionManager()方法实现了链式事务配置,注意我放置的顺序先userTM后resultTM,所以事务应该是先拿到userTM然后拿到resultTM然后提交resultTM最后提交userTM,也就是说,如果我在提交user事务的时候出错,此时result相关的事务已经提交完成,所以result数据是不能回滚的。
2.1 测试
@RequestMapping("")
@Transactional
public void testTX(){
// resultJdbcTemplate.execute("insert into result values(68,6,6)");
userJdbcTemplate.execute("insert into user values (6,'FantJ',23,'男')");
if (true){
throw new RuntimeException("yes , throw one exception");
}
resultJdbcTemplate.execute("insert into result values(66,6,6)");
// userJdbcTemplate.execute("insert into user values (8,'FantJ',23,'男')");
}两个数据库没有内容。
控制台精简后的日志:
Creating new transaction with name [springbootjtamultidb.jtamulti.JtaMultiApplicationTests.testTX]:
Creating new transaction with name [springbootjtamultidb.jtamulti.JtaMultiApplicationTests.testTX]:
Began transaction (1) for test context [DefaultTestContext@1dde4cb2 testClass = ...
Executing SQL statement [insert into user values (6,'FantJ',23,'男')]
Initiating transaction rollback
Rolling back JDBC transaction on Connection [HikariProxyConnection@318550723 wrapping com.mysql.cj.jdbc.ConnectionImpl@57bd6a8f]
Releasing JDBC Connection [HikariProxyConnection@318550723 wrapping com.mysql.cj.jdbc.
Initiating transaction rollback
Rolling back JDBC transaction on Connection [HikariProxyConnection@1201991394 wrapping com.mysql.cj.jdbc.ConnectionImpl@36f6e521]
Releasing JDBC Connection [HikariProxyConnection@1201991394 wrapping com.mysql.cj.jdbc.ConnectionImpl@36f6e521] after transaction
Resuming suspended transaction after completion of inner transaction
Rolled back transaction for test: [DefaultTestContext@1dde4cb2 testClass = JtaMultiApplicationTests, testInstance = springbootjtamultidb.jtamulti.JtaMultiApplicationTests@441772e,


其实只要是两个dao操作中间出错或者第一个dao操作之前出错,事务都能正常回滚。如果result操作再前,user操作再后,user操作完抛出异常,也能回滚事务,原因上文有讲。
@RequestMapping("")
@Transactional
public void testTX(){
resultJdbcTemplate.execute("insert into result values(68,6,6)");
// userJdbcTemplate.execute("insert into user values (6,'FantJ',23,'男')");
// if (true){
// throw new RuntimeException("yes , throw one exception");
// }
// resultJdbcTemplate.execute("insert into result values(66,6,6)");
userJdbcTemplate.execute("insert into user values (8,'FantJ',23,'男')");
if (true){
throw new RuntimeException("yes , throw one exception");
}
}这段代码也能正常回滚,结果我就不贴了。(浪费大家精力)
2.2 验证第二个事务不能回滚的情况
重要的事情再重复一遍:注意我放置的顺序先userTM后resultTM,所以事务应该是先拿到userTM然后拿到resultTM然后提交resultTM最后提交userTM,也就是说,如果我在提交user事务的时候出错,此时result相关的事务已经提交完成,所以result数据是不能回滚的。
代码和之前的一样,需要在事务提交的方法中打断点
@RequestMapping("")
@Transactional
public void testTX(){
resultJdbcTemplate.execute("insert into result values(68,6,6)");
userJdbcTemplate.execute("insert into user values (8,'FantJ',23,'男')");
}

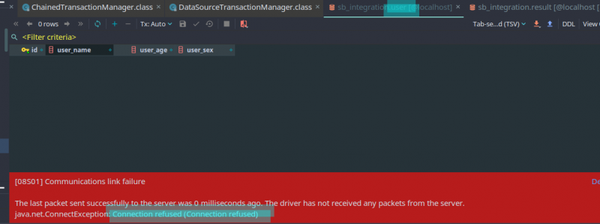
注意拦截到断点时,先放行一个commit,也就是result事务的commit,然后拦截到第二个commit请求时,关闭user所在的数据库,然后放行。
下面是将第一个commit请求放行后的控制台日志:
Creating new transaction with name [springbootjtamultidb.jtamulti.controller.MainController.
Acquired Connection [HikariProxyConnection@810768078 wrapping com.mysql.cj.jdbc.ConnectionImpl@3cfb22cd] for JDBC transaction
Switching JDBC Connection [HikariProxyConnection@810768078 wrapping com.mysql.cj.jdbc.ConnectionImpl@3cfb22cd] to manual commit
Executing SQL statement [insert into result values(68,6,6)]
Executing SQL statement [insert into user values (8,'FantJ',23,'男')]
Initiating transaction commit
Committing JDBC transaction on Connection [HikariProxyConnection@810768078 wrapping com.mysql.cj.jdbc.ConnectionImpl@3cfb22cd]
Releasing JDBC Connection [HikariProxyConnection@810768078 wrapping com.mysql.cj.jdbc.ConnectionImpl@3cfb22cd] after transaction
Resuming suspended transaction after completion of inner transaction注意倒数第三行日志,它出现证明我们第一个result的sql事务已经提交,此时你刷新数据库数据已经更新了,但是我们断点并还没有放行,user的事务还没有提交,我把user的数据库源关闭,再放行,可以看到,result已经有数据,user没有数据,此时result并没有进行回滚,这是链式事务的缺点。



谈谈使用环境
JTA优缺点
JTA它的缺点是二次提交,事务时间长,数据锁的时间太长,性能比较低。
优点是强一致性,对于数据一致性要求很强的业务很有利,而且可以用于微服务。
链式/同步事务优缺点
优点: 比JTA轻量,能满足大部分事务需求,也是强一致性。
缺点: 只能单机玩,不能用于微服务,事务依次提交后提交的事务若出错不能回滚。
它两的比较
- JTA重,Chained轻。
- JTA能用于微服务分布式事务,Chained只能用于单机分布式事务。
事实上我们处理分布式事务都要求做到最终一致性。就是你刚开始我不需要保持你的数据一致,你中间可以出错,但是我能保证最终数据是一致的。这种做法性能最高,下一章节会谈。
