
如何同时实现高性能并行+分布式计算?| Taichi x MPI4Py

2017 年 11 月的北京 GTC 大会,后来大放异彩的深度学习神器 V100 显卡在国内首次亮相。演讲中,英伟达 CEO 黄教主缓缓说出了一句话,振聋发聩余音绕梁:


后来的事情我们都知道了:几家知名互联网公司买了成千上万张 V100 堆进了数据中心里,AI 智商也不断提高——人脸识别越来越细,语音转文字越来越准,机器翻译开始说人话,游戏 AI 把职业选手按在地上摩擦。在这背后,是大厂和开源社区倾注了大量资源研发的各种分布式机器学习框架,这些框架能够将规模较大的机器学习问题拆解为更小的子问题运行在不同的显卡上,并实现显卡之间的数据通信。
Taichi 社区的用户也常有类似的需求:不少用户在研究中需要处理非常大规模的网格(如流体和粒子仿真),大到数据量远远超过一张显卡的显存。大家都非常想知道有没有一种简单的方法,可以让 Taichi 程序分布式地跑在多张 GPU 卡甚至多台 GPU 机器上,从而高效地解算大规模问题呢?
答案是:当然可以!把 Taichi 和 MPI4Py 结合起来,我们也可以用很短的代码实现并行 + 分布式运算。不信?容我慢慢道来!
准备工作一:初识 MPI4Py


MPI 是超算环境中沿用超过二十年的通信接口,用来让超算中成千上万台机器互相通信协作、传递数据,解决大规模计算问题,因此任何使用超算的人都免不了要和 MPI 打交道。直接写 MPI 程序是个挺麻烦的事情,好在 MPI 也有 Python 封装,叫做 MPI4Py 。我们来看一个最简单的使用 MPI4Py 的程序:
# mpi_hello.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
print(f"Hello from MPI worker {comm.rank}, the MPI world has {comm.size} peers.")这个程序只有三行代码,其中最核心的是第二行引入的 MPI_COMM_WORLD,这也是 MPI 中最基础的概念。所有 MPI 创建的进程,无论是否在同一台机器上,都在 MPI_COMM_WORLD 中有一个独立的编号 rank,rank=0 表示这是第一个进程,rank=1 表示这是第二个进程,以此类推。总进程的个数可以通过 comm.size 拿到。最后的 print 语句会被每个线程分别执行,每个线程会打印自己在 MPI_COMM_WORLD 中的编号 comm.rank,以及所有线程的总数 comm.size。
运行上面这个 MPI 程序需要在 python 命令前加上 mpirun,其中 -np 指定总共需要拉起多少个进程,--hosts 指定参与并行计算的机器名字:
mpirun -np 8 --hosts node1,node2 python mpi_hello.py一切正常的话,屏幕上会出现如下信息
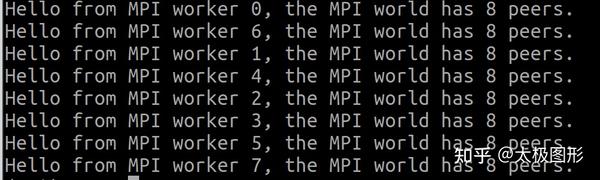

关于 MPI4Py 的基础用法我们就先了解这么多,接下来我们准备一个简单的 Taichi 程序,然后把它拆分成若干子任务用 MPI4Py 跑在不同的机器上。
准备工作二:一个 Taichi 小程序
我们来写一个简单的用 Taichi 处理网格的程序:泊松求解器。泊松求解器实现了下面这个 Laplace 方程的求解过程:
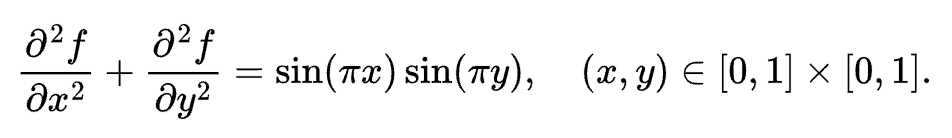
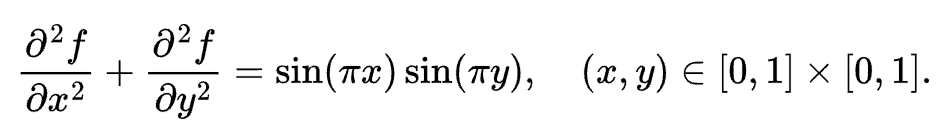
其中边界条件为 f(x,y)=0。
读者完全不必关心这个求解器的计算原理,只要知道这是一个操作网格的 kernel 即可,代码非常简单:
x = ti.field(dtype=float, shape=(N + 2, N + 2))
xt = ti.field(dtype=float, shape=(N + 2, N + 2))
@ti.kernel
def substep():
for i,j in ti.ndrange((1, N+1), (1, N+1)):
xt[i,j] = (-b[i,j]*dx**2+x[i+1,j]+x[i-1,j]+x[i,j+1]+x[i,j-1]) / 4.0
for I in ti.grouped(x):
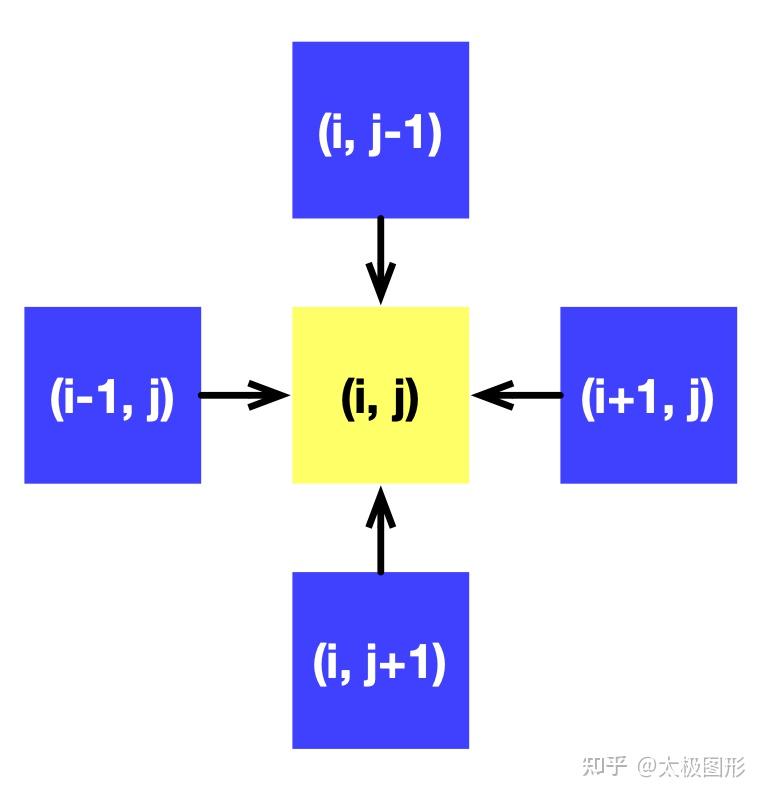
x[I] = xt[I]我们用了一个(N+2) x (N+2) 的 field x 来表示 f,其中的 + 2 是为了避免边界处下标越界额外填充的空间 (padding)。每个网格的计算只依赖它周围相邻的四网格。如下图所示:
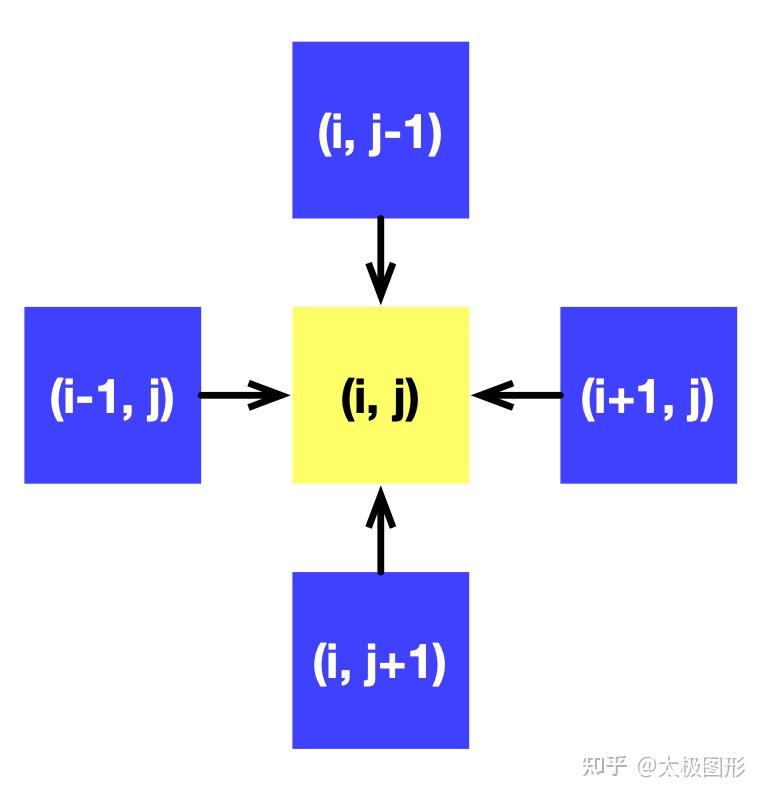
我们可以通过反复调用 substep 来逐渐逼近 f 的解。
现在我们有了一个可以运行在单机单卡上的 Taichi 程序,接下来我们要使用 MPI4Py,把这个程序分布到多台机器上运行!
第一个 MPI 版本:解决数据依赖,实现多机并行
将一个程序从单卡切换到多卡,第一步是要解决的是数据分块的问题。分块有两个层面,一是确定分块的形状,二是解决分块以后块和块之间的数据依赖。
一个简单的切法是,可以把 x 竖直切三刀,分成四个水平排列的子场。由于第一个 MPI 版本:解决数据依赖,实现多机并行 substep 函数只用到网格周围的四个邻居,所以每个子场内部的计算与其它子场独立,但相邻的两个子场在它们的公共边界处的数据是互相依赖的。我们给每个子场进一步填充一些空间(图中灰色的部分),用来存储与其相邻子场的边界数据,如下图所示,然后用 MPI 在多个机器间同步子场的边界数据。
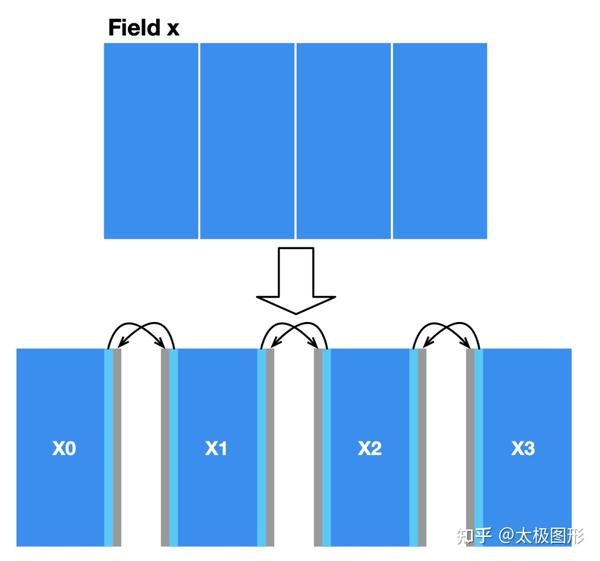
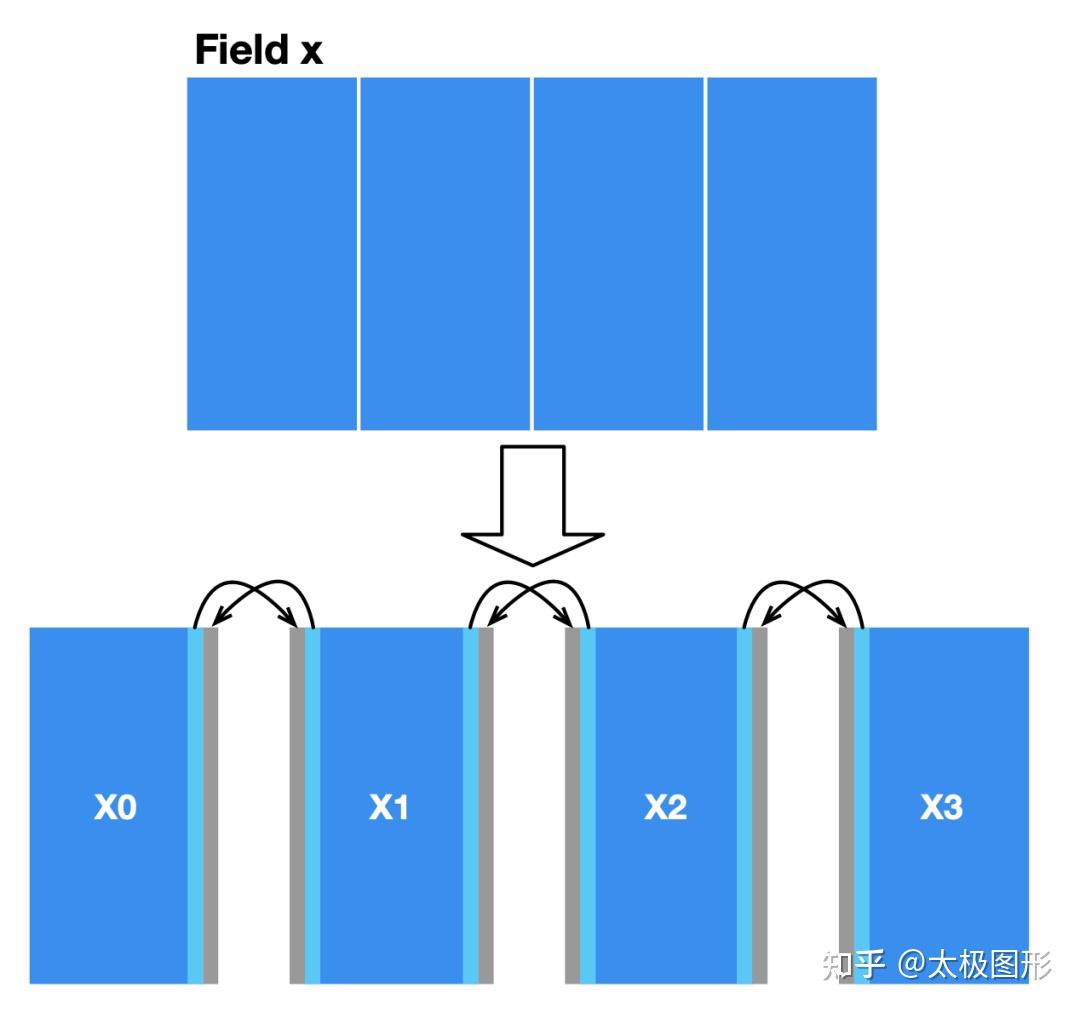
切分后,由于 MPI 会发起多个进程,每个进程中的 Taichi 程序只能看到分配给自己的子场,因此场的声明也要对应改一下维度:
n = N // 4
x = ti.field(dtype=float, shape=(N + 2, n + 2))所以从现在起,x 不再表示完整的 field,而是每个进程自己可见的子场。在不同的进程中 x 对应不同的子场。
MPI4Py 支持直接使用 Numpy 的 ndarray 来作为数据的传输缓冲区,只要保证传递的 ndarray 在内存中是连续的即可。我们可以用 field 数据结构的 to_numpy 和 from_numpy 方法来实现 field 与 NumPy 数组之间的数据交换,下面这段代码展示了如何把当前子场的右边界发送给右边的进程:
comm = MPI.COMM_WORLD
x_arr = x.to_numpy()
x_right = np.ascontiguousarray(x_arr[:, -2])
if comm.rank < num_workers - 1:
comm.Send(x_right, dest=comm.rank+1)假定我们的四个子场是 X0、X1、X2、X3,分别运行在 0,1,2,3 四个进程中,则 comm.rank+1就是右边子场对应的进程。if 语句确保只有 0, 1, 2 进程向右边的进程发送数据,因为 3 号进程是不需要发送右边界的。另外,MPI 中 Recv 和 Send 必须搭配使用,如果只发送了数据,但是 MPI 没有找到接收者,那就会在没有提示的情况下出现通信死锁。所以接下来的代码就需要处理接收逻辑,也就是 Recv:
shadow_left = np.zeros(N + 2)
if comm.rank > 0:
comm.Recv(shadow_left, source=comm.rank-1)
# Fill in the left edge
x_arr[:, 0] = shadow_left
x.from_numpy(x_arr)其中 shadow_left 是一个缓存区,用于存储接收的数据。
和发送的逻辑相反,接收逻辑是每个进程从左边的进程接收数据,填入子场的左边界。其中,0 号进程不需要接收,代码中的 if 语句保证只有 1-3 号进程在接收数据。对另一组边界的处理方式是完全类似的。至此我们就完成了一个完整的发送/接收逻辑,感兴趣的读者可以前往仓库参考完整代码。
现在我们的程序可以成功跑在多台机器上了,但性能上还有很大的提升空间,主要有两个问题:
1. 调用 filed.to_numpy()方法会将整个 field 转换为 NumPy 数组,而实际发送的数据只包含场的边界的部分,有一部分数据拷贝可以省掉。
2. 每个子场只有在 Recv 收到数据后才会进行下一步迭代计算,但实际上大部分的计算发生在子场的内部,它们没有必要“干等”数据的交换。
我们接下来就分别解决这些问题。
优化之一:使用 Taichi 来拷贝边界数据
上一节的代码中为了方便演示,我们把整个场拷贝到 numpy 数组中,然后利用 numpy 的 array slice 来提取或填入边界数据。事实上我们不需要拷贝整个场,只需要操作边界的数据即可。这恰好是 Taichi 非常擅长的工作。我们可以写几个非常简短的 Taichi Kernel 来执行这些操作,以数据填入为例:
@ti.kernel
def fill_shadow(shadow_left : ti.types.ndarray(),
shadow_right : ti.types.ndarray()):
for i in ti.ndrange((0, N + 2)):
x[i, 0] = shadow_left[i]
x[i, n+1] = shadow_right[i]其中,shadow_left 和 shadow_right 是前面 MPI4Py 用来接收数据的 Numpy 数组。而这些 Numpy 数组可以直接传进 Taichi 的 kernel 中,唯一的开销就是必要的 CPU-GPU 之间的数据传输。而如果使用 CPU 后端,Taichi Kernel 会直接在 Numpy 数组上执行操作,没有额外的内存拷贝开销。
优化之二:MPI 异步传输减少通信开销
大多数的网格计算问题的数据依赖都局限在一个很小的区域。在本文的泊松求解器中,每个 x 的子场的内部的格子可以独立于边界格子来计算,这部分的计算是不需要参与通信的。因此我们可以把每个迭代的计算函数 substep 拆解成两个,一部分处理边界相关的计算 substep_edge,一部分处理场内部的计算 substep_bulk,如下图所示。


由于场内部的网格计算不需要参与通信,因此可以和通信同步进行,从而减少时间开销。具体讲,和前面的实现稍有不同,我们将 Send 和 Recv 换成非阻塞的异步通信原语 Isend 和 Irecv。所谓非阻塞,就是代码在提交发送请求之后不做任何等待,继续执行下面的代码,直到遇到 Wait 调用才完成整个通信。另外需要增加一个标签参数 tag,来标记每组通信发送、接收的数据。那么之前的发送数据的通信代码对应改成:
if comm.rank < num_workers - 1:
comm.Isend(edge_right, dest=comm.rank+1, tag=11)而接收的通信代码变成
if comm.rank > 0:
comm.Irecv(shadow_left, source=comm.rank-1, tag=11).Wait()为了掩盖开销,我们先发送数据,然后调用substep_bulk,在通信完成之后调用substep_edge。整个计算和通信的过程如下代码所示:
def step():
mpi_send_edges() # Trigger communication
substep_bulk() # Compute the bulk
mpi_recv_edges() # Wait for communications
substep_edge(shadow_left, shadow_right) # Compute the edges这样调用后,整个程序运行过程中substep_bulk的计算开销和 MPI 的通信开销可以互相掩盖,进而提升总体性能。


性能评估
我手里正好有两台 GPU 的机器,就把它们连在同一个路由器上,配置了 MPI 环境。其中一台机器 (node0) 插了一块 RTX3080 显卡,配的 i9-11900k CPU,另一台机器 (node1) 装的是 GTX1080Ti,配的是 E3-1230v5。两台机器都装的 Ubuntu 20.04 系统。


测试的网格大小为 8192 * 8192。分配给两台机器一起算。我们分别测试了 CPU 和 GPU 的运行性能。在 Taichi 中,切换 CPU 或者 GPU 实现只需要指定 arch=ti.cpu 或 arch=ti.gpu。
在分布式计算中,多台机器所能达到的最优的性能上界应该是各机器的单机性能之和,即所谓的线性扩展。那么我们优化后的实现距离这个理想指标有多远呢?用数据说话!
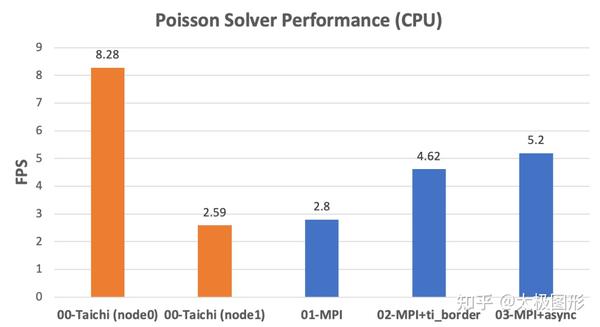
我们先看一下 CPU 的性能评测。两台机器的 CPU 的性能差距非常大(下图橙色部分),由于我们是将整个场做了等比例的切分,每一个迭代步node0 都需要等待node1 完成计算,所以优化后的 MPI 实现的性能差不多是node1 的两倍。这是一个非常好的数据,如果这两台机器的 CPU 完全一样的话,是可以做到理想的线性扩展。

再看一下 GPU 的性能评测。可以看到未优化的 MPI 实现的性能甚至比 CPU 还要慢一些,这是因为 CPU-GPU 之间的内存数据拷贝对性能有很大的影响。而使用 Taichi + 异步通信优化来处理边界数据之后,性能出现了非常大的提升。最终在 GPU 测试上,我们的程序也达到了较慢的那张卡的 2 倍性能 (171.2 / 89.68 = 1.91),这也是非常好的一个结果。
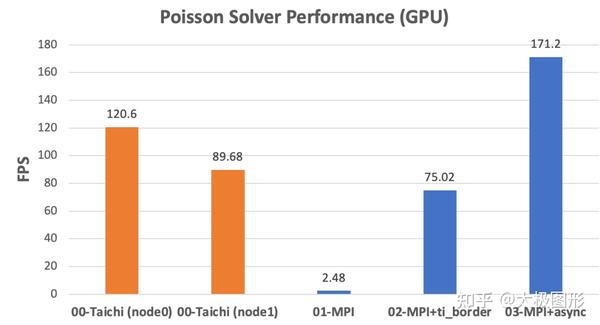

如果想让最终的性能达到两张卡性能之和,就需要按照它们单独运行的性能比例来对问题规模进行划分,这个事情会比较复杂,也不是常见的使用场景,我们就不再深入讨论了。
结语
在这篇文章中,我们用一个简单的例子展示了怎样用 Taichi + MPI4Py 的方法来同时实现并行 + 分布式计算。完整的程序仅有 100 余行 Python 代码,开发起来并不复杂,却达到了非常理想的扩展性。希望本文的讨论能够对需要求解大规模数值计算问题的读者有所助益。不过这里的讨论考虑的数据依赖比较简单,在实际问题中如果需要做随机的数据访问,或者存在更复杂的数据依赖时,MPI 通信的部分写起来还是比较棘手的。大家如果在开发中遇到了这方面的困难,或者有什么好的建议和方案,欢迎到论坛上和我们一起聊聊!