基于深度学习的webshell检测(二)


综述
上一篇主要讲述如何使用机器学习方法来进行webshell检测,本章将使用深度学习方法同样完成这一任务
webshell,从本质上来看就是一个代码文件,其中包含的是文本信息,不同的是他是计算机语言的文本信息。 那么,我们可以思考,是否可以参照nlp(自然语言处理)来进行的文本类任务同样将其应用于计算机语言的分类呢
个人认为是可以的
因为计算机语言和自然语言在某些方面是相同的,比方说,二者都具有非常清晰的语法特点和标准
在自然语言中,词法包括主谓宾定状补等,语法包括主系表,主谓宾等等....
而在计算机语言中,同样包括这些,如 变量,类型,类,对象,生命,函数名等等
可以说他们同样拥有着一套自己的语法规范和各式,这也是本文思路的来源
本文使用最常见的文本分类方法,word embedding配合lstm来完成这一任务,代码使用python keras实现
话不多说,直接上代码
首先,我们导入常用库,用于数据预处理以及可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
import os
import subprocess
import re
%matplotlib inline读取数据
和上一篇一样,我们将数据集的label和对应的文件路径存入一个pandas.DataFrame对象中
files_webshell = os.listdir("/webshell/project/php-webshell/")
files_common = os.listdir("/webshell/project/php-common")
labels_webshell = []
labels_common = []
for i in range(0,len(files_webshell)):
labels_webshell.append(1)
for i in range(0,len(files_common)):
labels_common.append(0)将恶意文件和正常文件拼接在一起,再将文件列表和标签列表拼接在一起
for i in range(0,len(files_webshell)):
files_webshell[i] = "/webshell/project/php-webshell/" + files_webshell[i]
for i in range(0,len(files_common)):
files_common[i] = "/webshell/project/php-common/" + files_common[i]
files = files_webshell + files_common
labels = labels_webshell + labels_common将其转化成pandas.DataFrame类型数据
datadict = {'label':labels,'file':files}
df = pd.DataFrame(datadict,columns=['label','file'])由于我们的样本量是非常小的,而一个代码文件可能包含非常多的变量,字符串,函数,类等等,我们可以想象如果只是在代码层面上做一些语言处理的工作,如one-hot,embedding等,那么我们将会得到一个非常大且非常稀疏的矩阵(因为离散分布着大量的词)
那么如何处理这种情况,我们想到可以通过将代码编译成中间层代码或底层代码来实现,我们将这类代码乘坐opcode,可以将其类比于X86汇编,这样我们就可以将大量代码转化成指令集有限且不多的底层代码(就像汇编中的mov,jz,jump一样)
对于最好的语言php来说,他的底层代码可以通过扩展程序VLD获得,因此我们可以将我们的所有样本文件都编译出php的opcode代码,并保存起来,这个过程有一些漫长...
def getopcode(x):
try:
cmd = "php -dvld.active=1 -dvld.execute=0 " + str(x)
output = subprocess.getoutput(cmd)
oplist = re.findall(r'\s(\b[A-Z_]+\b)\s',output)
print(str(x))
return oplist
except:
print("error" + str(x))
return None
df['opc'] = df['file'].map(lambda x:getopcode(x))之后,由于我们所使用的lstm模型需要一个定长的输入,因此我们计算出每个文件转化成opcode代码的长度并保存,在此之前,我们丢弃空数据
df = df.dropna()
def getoplen(x):
return len(x)
df['oplen'] = df['opc'].map(lambda x:getoplen(x))OK,接下来看一看opcode码长啥样吧,其实跟X86差不多
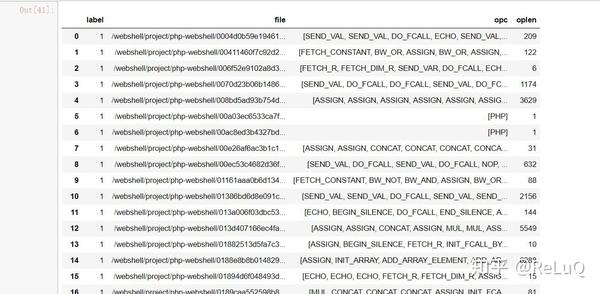

接下来就是模型前的数据处理了,我们使用最常见最通用的word embedding + lstm方法来建模,embedding使用word2vec方法,代码实现使用python gensim库
(再次重复python真的太舒服了,让笔者几次想要入Julia坑都跑回来了2333)
我们封装一个函数,将opc这一列通过word2vec算法生成对应元素的数值矩阵,笔者这里选择向量长度为100,并将矩阵存入word2vec.txt文件中
from gensim.models import Word2Vec
def getw2v(opc_list,label_list):
print(label_list[0:10])
stop = []
w2v_list = []
for i in range(0,7789):
try:
print(label_list[0:10])
tmp = []
name = opc_list[i]
#print(name[0])
for j in range(0,len(name)):
tmp.append(name[j])
w2v_list.append(tmp)
except:
pass
model = Word2Vec(w2v_list, min_count = 1)
#print (model._vocabulary)
model.wv.save_word2vec_format('word2vec.txt',binary=False)
#return 0
#print model['a']
label_vect = []
wv_vect = []
for i in range(0,7789):
try:
#print(i)
name = opc_list[i]
tmp = []
vect = []
for j in range(0,len(name)):
if name[j] in stop:
continue
tmp.append(model[name[j]])
if j >= 99:
break
if len(tmp) < 100:
for k in range(0,100-len(tmp)):
tmp.append([0]*100)
vect = np.vstack((x for x in tmp))
wv_vect.append(vect)
label_vect.append(label_list[i])
#if i ==100000:
# break
except:
pass
wv_vect = np.array(wv_vect)
label_vect = np.array(label_vect)
return wv_vect,label_vect
w2v_word_list,label_list = getw2v(df['opc'],df['label'])接下来就是测试模型啦,随便选部分数据作为我们的训练集,剩余作为测试集(demo就省略验证集啦)
x_train = np.concatenate((w2v_word_list[0:2000],w2v_word_list[2500:7000]))
y_train = np.concatenate((label_list[0:2000] , label_list[2500:7000]))
x_test = np.concatenate((w2v_word_list[2000:2500] , w2v_word_list[7000:]))
t_test = np.concatenate((label_list[2000:2500] , label_list[7000:]))
接下来我们使用keras来建模,选择keras的原因只有一个,对于小型代码极端方便,后面的篇幅笔者也会使用tensorflow来应对复杂的任务
是的,以下几行代码,建模就完成了,这里使用了单层的lstm模型,将输出带入一个sigmod函数来归一成0-1分布,优化器使用adam
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Embedding
from keras.layers import LSTM
model = Sequential()
#model.add(Embedding())
model.add(LSTM(128,dropout = 0.2,recurrent_dropout = 0.2))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = 'adam',metrics = ['accuracy'])最终我们得到如下的准确率
print ('now training....')
model.fit(x_train,y_train,nb_epoch = 50,batch_size = 32)
print ('now evaling....')
score,acc = model.evaluate(x_test,y_test)
print (score,acc)now evaling....
1260/1260 [==============================] - 3s 3ms/step
0.1536306839850214 0.9396825398717608
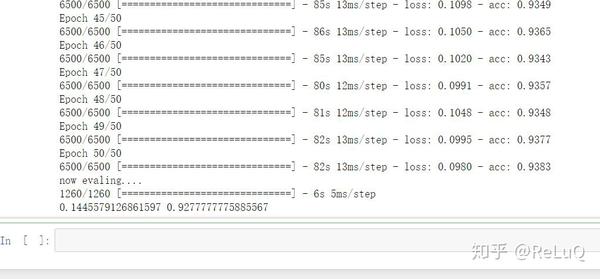
试试看两层的lstm:
model = Sequential()
#model.add(Embedding())
model.add(LSTM(128,dropout = 0.2,recurrent_dropout = 0.2,return_sequences=True))
model.add(LSTM(128,dropout = 0.2,recurrent_dropout = 0.2))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = 'adam',metrics = ['accuracy'])
print ('now training....')
model.fit(x_train,y_train,nb_epoch = 50,batch_size = 32)
print ('now evaling....')
score,acc = model.evaluate(x_test,t_test)
print (score,acc)