
大白话Kaggle入门 : Titanic篇

1. 目的
用简单且强大的LR模型, 尝试二分类预测。
文章可能需要你有些Python基础,并简单了解pandas和sklearn的使用。如果没有这部分基础,你也可以简单了解下"传说"中的机器学习是怎么一个过程,可能看完后,你可能觉得也就"那样"?O(∩_∩)O哈哈~
这次大白话,对于入数据民工行业的同学,可能会有三部分收获。
- 数据分析
- 异常数据处理
- 特征选择
如果你偏重分析,完全可以仅读《2.1 数据分析》
如果你想了解数据清理,可以看下《2.2 数据处理》
文中涉及的代码已整理github: Titanic ipython code
Titanic比赛介绍和数据下载: Titanic Kaggle
2. 过程
下面争取用最容易理解的方式分解整个过程
2.1 数据分析
- 重要性: 5星
- 难易程度: 3星
- 时间占用: 10%左右?(估计的数字)
字段说明


2.1.1 整体查看
- 代码
# 以下代码在ipython notebook中执行
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
df_gender = pd.read_csv("gender_submission.csv")
df_test = pd.read_csv("test.csv")
df_train = pd.read_csv("train.csv")
df_train.info()
# 输出如下结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB- 分析结果
- 训练总样本数量: 891条
- 字段数: 12个
- Age字段存: 891-714=177个 空值
- Cabin字段: 891-204=687个 空值
- Embarked字段: 891-889=2个 空值
2.1.2 各属性分布
- 下面的数据样本, 可以看出
- Age, Fare字段的值是连续的, 需要对其按值分组
- Name, Ticket是个性化的, 暂时不看其分布
- 需要按字段值查看分布的有: Survived, Sex, Pclass, Age, SibSp, Parch, Fare, Embarked


- 连续值转离散
# 针对 Age 和 Fare, 进行连续值转离散操作, 实际操作上就是把值分段:
import math
def continueToGroup(df, column_name, group_num):
'''
df: DataFrame
column_name: 被分段的字段
group_num: 希望被划分的组数
'''
# 注意: pd.cut函数默认被分段的区间是左开右闭, 如: (0,10]
# 所以min需要略低一些, 这样不会漏数据
min_v = math.floor(df[column_name].min()) - 0.1
max_v = math.ceil(df[column_name].max()*1.0) # math.ceil要求参数为float类型
step = math.ceil((max_v - min_v) / group_num)
# 自己测试下 np.arange(0,10,1) 就会知道为啥 max_v+step 最后要加step
df[column_name+'_group'] = pd.cut(df[column_name], np.arange(min_v, max_v+step, step))
# 连续值变离散 字段分组:
continueToGroup(df_train, 'Fare', 5)
continueToGroup(df_train, 'Age', 10)
continueToGroup(df_test, 'Fare', 5)
continueToGroup(df_test, 'Age', 10)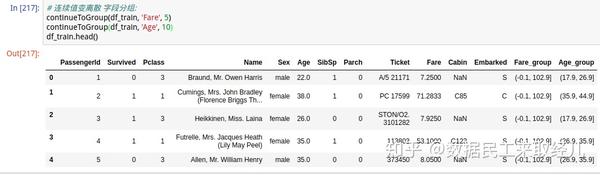

- 各特征的分布
# 字段包括: Survived, Sex, Pclass, Age_group, SibSp, Parch, Fare_group, Embarked
# 每个单个绘图工作重复, 所以写个绘图函数, 批量绘图,刷刷刷! 分布看的一清二楚!
def fun_distributed(df, column_name):
df_res = df.groupby(column_name).count()['PassengerId'].reset_index()
# 柱状图x轴仅接受float类型,如果要显示str的x轴标签,需要映射处理下
x_names = df_res[column_name].values
x_list = range(len(x_names))
plt.xticks(x_list, x_names, rotation=45)
y_list = df_res['PassengerId'].values
plt.title(column_name)
plt.bar(x_list, y_list)
plt.legend()
column_list = ['Survived', 'Pclass', 'Sex', 'Age_group','SibSp', 'Parch', 'Fare_group', 'Embarked']
# 根据单个字段批量绘图
def draw_all_columns(df, columns):
fig = plt.figure(figsize=(15,20))
for i in range(len(columns)):
plt.subplot(3,4,i+1)
fun_distributed(df, columns[i])
draw_all_columns(df_train, columns=column_list)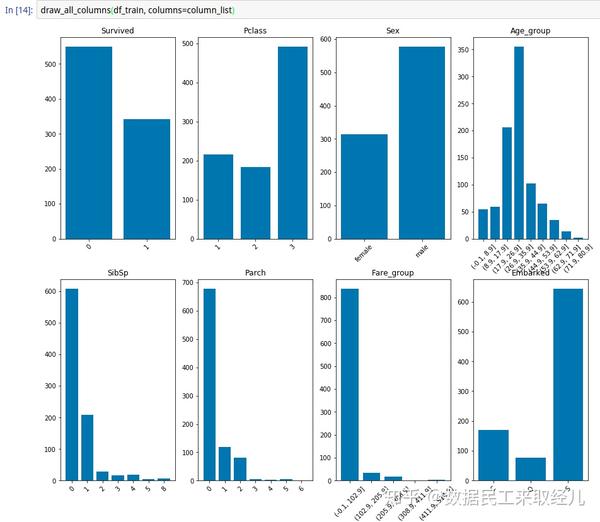

- 各属性TGI指数查看
别慌, TGI我先介绍下, 哈哈。
TGI指数= 目标群体中具有某一特征的群体所占比例/总体中具有相同特征的群体所占比例
举例理解:
小明学校男女比例100:100, 但小明班级男女比例10:5, 那么说明小明班级男生比整个学校平均值高, 那么怎么量化这个值呢?即: 小明班级男生占比 / 全校男生占比 = (10/15) / (100/200) = 1.33
描述: 小明班级男生的密度较高, 是整个学校平均男生密度的1.3倍。
有没有豁然开朗? 好,下面我们计算每个特征对应人群的幸存率并与平均值比较,查看其TGI指数
# 计算平均幸存率
survived_percent = 1.0*df_train.Survived[df_train.Survived==1].count() / df_train.Survived.count()
# tgi比例计算
def fun_tgi(df, column_name, scale=survived_percent):
df_res = df.groupby(['Survived', column_name]).count()['PassengerId'].reset_index()
df_pivot = pd.pivot_table(df_res, values='PassengerId', columns='Survived', index=column_name, aggfunc=np.sum)
df_pivot['total']=df_pivot[0] + df_pivot[1]
df_pivot['percent']=df_pivot[1]/df_pivot['total']
# 柱状图x轴仅接受float类型,如果要显示str的x轴标签,需要映射处理下
x_names = df_pivot.index.values
x_list = range(len(x_names))
plt.xticks(x_list, x_names, rotation=45)
y_list = df_pivot['percent'] / scale
plt.title(column_name)
plt.bar(x_list, y_list)
plt.legend()
column_list = ['Pclass', 'Sex', 'Age_group','SibSp', 'Parch', 'Fare_group', 'Embarked']
# 根据单个字段批量绘图
def draw_tgi_all_columns(df, columns):
fig = plt.figure(figsize=(15,20))
for i in range(len(columns)):
plt.subplot(3,4,i+1)
fun_tgi(df, columns[i])
draw_tgi_all_columns(df_train, column_list)

2.1.3 空值处理
# 批量检查空值
def check_null(df):
for i in df.columns:
df_col = df[df[i].isnull()]
if df_col.size>0 and i != 'Cabin' and i != 'Age_group' and i!='Fare_group':
print df_col
# 针对三个字段的空值进行填充
# 填充方式很多, 这里按中位数填充
df_train.Embarked.fillna('C', inplace=True)
df_train.Fare.fillna(df_train.Fare.median(), inplace=True)
df_train.Age.fillna(df_train.Age.median(), inplace=True)
df_test.Embarked.fillna('C', inplace=True)
df_test.Fare.fillna(df_test.Fare.median(), inplace=True)
df_test.Age.fillna(df_test.Age.median(), inplace=True)
# 检查空值处理后有误
check_null(df_train)
check_null(df_test)2.1.4 异常值查看
# 查看Fare和Age两个连续值的箱图, 观看异常值分布
df_train.Fare.plot(kind='box')
plt.show()
df_train.Age.plot(kind='box')
plt.show()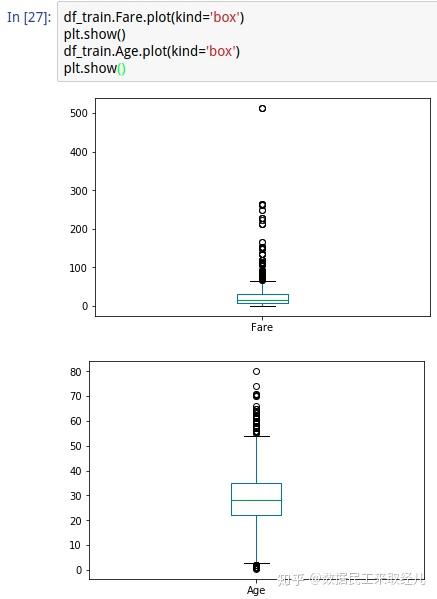

- 过滤掉异常值
过滤的阈值是我自己排脑袋的哈, 大家自己可以自己选择边界值, 多尝试训练效果。这里我们主要知道可能有异常值需要去除这么回事儿。
df_train = df_train[(df_train.Age<=50) & (df_train.Fare<=50)]
df_train.info()
# 如下: 过滤完异常值后的数据信息
Int64Index: 688 entries, 0 to 890
Data columns (total 18 columns):
PassengerId 688 non-null int64
Survived 688 non-null int64
Pclass 688 non-null int64
Name 688 non-null object
Sex 688 non-null object
Age 688 non-null float64
SibSp 688 non-null int64
Parch 688 non-null int64
Ticket 688 non-null object
Fare 688 non-null float64
Cabin 69 non-null object
Embarked 688 non-null object
name2 688 non-null object
HasCabin 688 non-null bool
Cabin_No 688 non-null float64
Fare_group 688 non-null category
Age_group 688 non-null category
Cabin_No_group 688 non-null category
dtypes: bool(1), category(3), float64(3), int64(5), object(6)
memory usage: 86.8+ KB2.2 数据处理(特征处理)
- 重要性: 5星
- 难易程度: 4星
- 时间占用: 50%
2.2.1 连续值转离散
逻辑回归输入的是数值, 所以需要把Age_group, Fare_group等字段的分组分别映射为具体的数字。 如: (-0.1,8.9) -> 1 , (8.9, 17.9) -> 2 , 依次类推。这种map方法可以自己写,但直接使用sklearn中API来处理可能更方便。
# 将连续值转化为Label
import math
def continueToGroup(df, column_name, group_num):
min_v = math.floor(df[column_name].min()) - 0.1
max_v = math.ceil(df[column_name].max()*1.0)
step = math.ceil((max_v - min_v) / group_num)
# 注意: 开闭区间, 所以min和max都要扩大才能cover所有值
df[column_name+'_group'] = pd.cut(df[column_name], np.arange(min_v, max_v+step, step))
# 将离散Label转化为数字
from sklearn import preprocessing
def groupToNum(df, column_name):
le = preprocessing.LabelEncoder()
le.fit(df[column_name])
new_column_name = column_name+'_toNum'
df[new_column_name] = le.transform(df[column_name])
return new_column_name
# 连续值变离散 字段分组:
continueToGroup(df_train, 'Fare', 5)
continueToGroup(df_train, 'Age', 10)
continueToGroup(df_test, 'Fare', 5)
continueToGroup(df_test, 'Age', 10)
# 开始操作
groupToNum(df_train, 'Fare_group')
groupToNum(df_train, 'Age_group')
groupToNum(df_test, 'Fare_group')
groupToNum(df_test, 'Age_group')2.2.2 分类别的离散值进行one-hot编码
比如: 性别, 船舱级别, 是否是小孩等, 这个本身是类别区分, 没有值大小区分, 如果单独放到一列用不同数值区分的话, 训练的时候可能会存在问题。
# one-hot 编码
def get_dummies_all(df, column_list):
res_list = []
for c in column_list:
res_list.append(pd.get_dummies(df[c], prefix= c))
return pd.concat(res_list, axis=1)
c_list = ['Pclass', 'Sex']
df_tmp = get_dummies_all(df_train, column_list=c_list)
df_train = pd.concat([df_train, df_tmp], axis=1)
df_tmp = get_dummies_all(df_test, column_list=c_list)
df_test = pd.concat([ df_test, df_tmp] , axis=1)

2.3 训练预测
- 重要性: 5星
- 难易程度: 2星
- 时间占用: 10%
2.3.1 单个LR训练预测
from sklearn.linear_model import LogisticRegression
# 经过one hot 编码后的列名, 过滤要进入训练集的特征
regex_str = 'Survived|Age_group_toNum.*|Fare_group_toNum.*|SibSp|Parch|Sex_.*male|Pclass_.*'
df_train_filter = df_train.filter(regex=regex_str)
df_test_filter = df_test.filter(regex=regex_str)
X_train_list = df_train_filter.columns.values[2:]
X_test_list = df_test_filter.columns.values[1:]
# 生成训练数据
X = df_train_filter[X_train_list]
y = df_train_filter['Survived']
# 待预测数据
X_predict = df_test_filter[X_test_list]
clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X,y)
# 自己先看下训练评分
clf.score(X, y)
# 结果:
0.793604651162790662.3.2 抽样放回多次LR训练预测
# BaggingRegressor, 即对训练数据抽样N次, 每次都用LR进行预测, 融合最终结果
from sklearn.ensemble import BaggingRegressor
clf = LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.5, max_features=1.0, bootstrap=True, bootstrap_features=True, n_jobs=1)
bagging_clf.fit(X, y)
bagging_clf.score(X, y)
# 结果:
# 含义: Returns the coefficient of determination R^2 of the prediction.
0.24170797413793085

2.4 交叉验证
- 重要性: 4星
- 难易程度: 3星
- 时间占用: 5%
- 备注: 该部分借鉴寒小阳的blog
2.4.1 交叉验证的分值
from sklearn import cross_validation
regex_str = 'Survived|Age_group_toNum.*|Fare_group_toNum.*|SibSp|Parch|HasCabin_False|HasCabin_False|Sex_.*male|Pclass_.*|Mother_.*|isChild_.*|name2_Ms|name2_Mr|name2_Miss|Family.*'
all_data = df_train_filter.filter(regex=regex_str)
X = all_data.as_matrix()[:,1:]
y = all_data.as_matrix()[:,0]
clf = LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
print cross_validation.cross_val_score(clf, X, y, cv=5)
# 结果:
[ 0.79710145 0.77536232 0.80434783 0.7826087 0.83088235]2.4.2 bad case分析
# 分割数据,按照 训练数据:cv数据 = 7:3的比例
from sklearn import cross_validation
split_train, split_cv = cross_validation.train_test_split(df_train, test_size=0.3, random_state=0)
regex_str = 'Survived|Age_group_toNum.*|Fare_group_toNum.*|SibSp|Parch|HasCabin_False|HasCabin_False|Sex_.*male|Pclass_.*'
all_data = split_train.filter(regex=regex_str)
all_data.head()
# 生成模型
clf = LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(all_data.as_matrix()[:,1:], all_data.as_matrix()[:,0])
# 对cross validation数据进行预测
cv_df = split_cv.filter(regex=regex_str)
predictions = clf.predict(cv_df.as_matrix()[:,1:])
origin_data_train = pd.read_csv("/home/zhangleihao/Document/00-litt/titanic/train.csv")
# split_cv[predictions != cv_df.as_matrix()[:,0]].head()
# origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases.describe()2.5 特征优化
- 重要性: 5星
- 难易程度: 5星
- 时间占用: 25%
发现Name和Cabin是没有使用过,看看能不能利用下,比如: Name中称谓是可以提取出来的, Mr. Miss.等, Cabin有大量的空值, 但实际获救场景很可能跟某个船舱相关,因为同一个船舱的人所处的实际地理位置和所知道的信息比较相似。这些都是猜测,我们需要从中提取出数据,加入训练,试一下.
2.5.1 提取name中称谓词
# 提取姓名中的称谓: 如 Mr. Miss. 等
df_train['name2'] = df_train.Name.apply(lambda x: x.split(",")[1].split('.')[0].strip())
df_test['name2'] = df_test.Name.apply(lambda x: x.split(",")[1].split('.')[0].strip())2.5.2 提取Cabin数字
# 仓位Cabin虽然确实比较多, 但可以尝试用下仓位的数字部分
# 标记是否缺失
df_train['HasCabin'] = df_train['Cabin'].isnull()
df_test['HasCabin'] = df_test['Cabin'].isnull()
# 不缺失的值,取出其中数字部分
import re
p= re.compile(r"[a-zA-Z ]")
pNum= re.compile(r"[0-9]")
def chooseNumFromCabin(cabinStr):
if cabinStr is None:
return 0
try:
res = pNum.findall(str(cabinStr))
except TypeError:
print cabinStr, type(cabinStr)
# 即: 如果字符串中没有数字直接返回0
if len(res)==0:
return 0
c_list = p.split(cabinStr)
c_list.sort(reverse=True)
return c_list[0]
df_train['Cabin_No'] = df_train.Cabin.apply(lambda x: chooseNumFromCabin(x))
df_train['Cabin_No'] = df_train.Cabin_No.astype('float')
df_test['Cabin_No'] = df_test.Cabin.apply(lambda x: chooseNumFromCabin(x))
df_test['Cabin_No'] = df_test.Cabin_No.astype('float')2.5.3 生成是否是孩子
df_train['isChild'] = df_train.Age<12
df_test['isChild'] = df_test.Age<122.5.3 生成是否是母亲
df_train['Mother'] = (df_train.Parch>1) & (df_train.name2=='Mrs')
df_test['Mother'] = (df_test.Parch>1) & (df_test.name2=='Mrs')2.5.4 生成家庭成员数
df_train['Family_size'] = df_train.Parch + df_train.SibSp
df_test['Family_size'] = df_test.Parch + df_test.SibSp2.5.5 重新抽取特征预测
c_list = ['Pclass', 'Sex', 'name2', 'HasCabin', 'Mother', 'isChild']
df_tmp = get_dummies_all(df_train, column_list=c_list)
df_train_filter = pd.concat([df_train, df_tmp], axis=1)
df_tmp = get_dummies_all(df_test, column_list=c_list)
df_test_filter = pd.concat([ df_test, df_tmp] , axis=1)
regex_str = 'Survived|Age_group_toNum.*|Fare_group_toNum.*|SibSp|Parch|HasCabin_False|HasCabin_False|Sex_.*male|Pclass_.*|Mother_.*|isChild_.*|name2_Ms|name2_Mr|name2_Miss|Family.*'
all_data = df_train.filter(regex=regex_str)
X = all_data.as_matrix()[:,1:]
y = all_data.as_matrix()[:,0]
X_predict = df_test.filter(regex=regex_str)
clf = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X,y)
clf.score(X, y)
# 结果:
0.8066860465116279加入以上特征, 再训练并预测,结果:


3. 特别感谢
关于经哥
帝都北五环外,码农集聚村,回龙观的一位数据老民工,欢迎加v唠嗑、吐槽(v: ITlooker)
2019年开始写写数据民工那些大白话,定期带来一些数据民工专属干货,如果你有其他行业的数据干货, 欢迎也晒给大家伙儿!集思广益,普惠于民工汪洋大世界!!
- 微信公众号: workindata
- 个人微信号: ITlooker
- 经哥数据教程: SQL|思维
- 自建数据小白SQL学习网站(用户名: hi-zhihu, 密码: justdoit)
人走赞留,江湖再见,蟹蟹!
不赞不赏我都懂,可不加我微信(ITlooker), 就是你的不对了:)
热门文章推荐
入门篇
经哥SQL教程 | 经哥思维教程 | 经哥Excel核心教程
技能篇
shell命令篇:文件查看 | 数据统计 | awk:数据统计
Python绘图篇: Matplotlib | Pandas | Seaborn
案例篇
短视频留存分析 | 社区内容生态建设分析 | 付费自习室的收入预估 | 相亲问题的数据量化
网站日志数据分析实战 | 网站被攻击的数据分析!| 大白话Kaggle入门 : Titanic篇
思维篇
数据波动的异常分析 | 订单下降该如何排查 | 场景思维,咱要有这个习惯 | 数据需求处理场景
求职篇
1400位同学的数据分析入坑问答 | 求职咨询的数据小白 | 前端工程师转行数据分析的咨询 | 关于数据分析找工作咨询回复
资料篇
不赞不赏我都懂,可不加我微信(ITlooker), 就是你的不对了:)知乎专栏: 大数据那些儿大白话
