
机器学习中的泛化能力

我们常常提到模型的泛化能力,什么是泛化能力呢?
百度百科这样解释:是指机器学习算法对新鲜样本的适应能力。 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
提取几个关键词:新鲜样本、适应能力、规律、合适输出。由此可见,经训练样本训练的模型需要对新样本做出合适的预测,这是泛化能力的体现。
举个例子,高中生每天各种做题,五年高考三年模拟一遍遍的刷,为的什么,当然是想高考能有个好成绩。高考试题一般是新题,谁也没做过,平时的刷题就是为了掌握试题的规律,能够举一反三、学以致用,这样面对新题时也能从容应对。这种规律的掌握便是泛化能力,有的同学很聪明,考上名校,很大程度上是该同学的泛化能力好。
考试成绩差的同学,有这三种可能:一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做;二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了;三、完全不做题,考试全靠瞎蒙。机器学习中,第一类情况称作欠拟合,第二类情况称作过拟合,第三类情况称作不收敛。


下面图片中每个点代表一棵树的位置,蓝点代表生病的树,橙点代表健康的树。
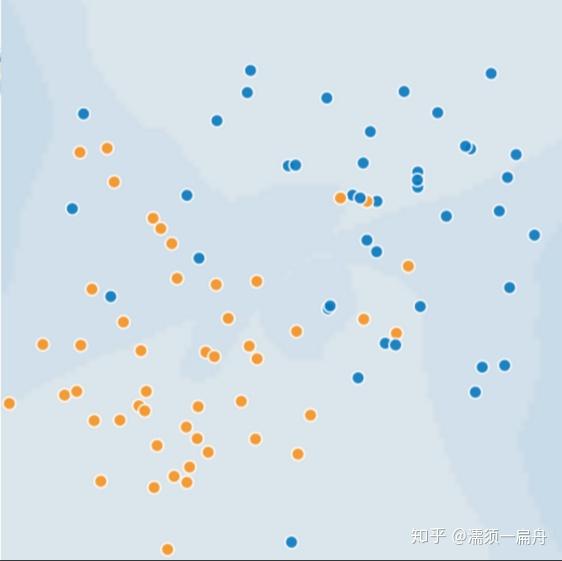

给你样本数据,要求提供一个机器学习算法算法,区分开两种树。
你千辛万苦画出来一条曲线能够很好地进行聚类,而且模型的损失非常低,几乎完美的把两类点一分为二。但这个模型真的就是好模型吗?
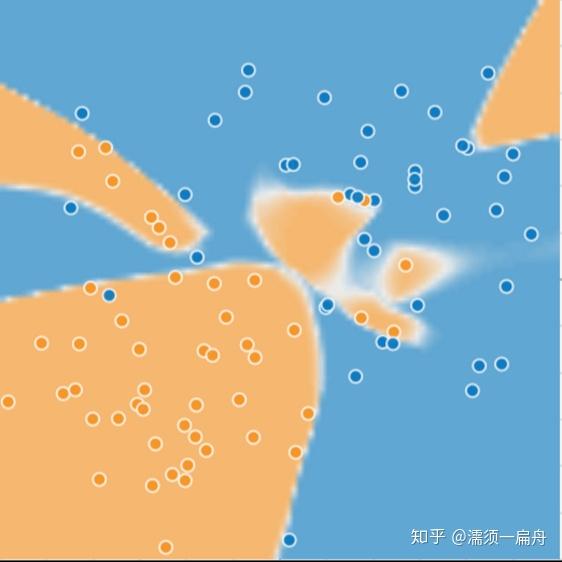

用该算法预测新样本时,没有很好的区分两类点,表现得有些差劲。
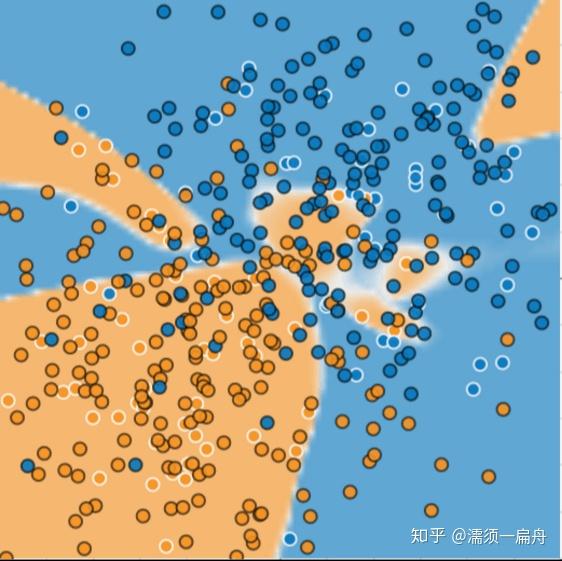

上述模型过拟合了训练数据的特性,过拟合模型在训练过程中产生的损失很低,但在预测新数据方面的表现却非常糟糕。如果某个模型在拟合当前样本方面表现良好,那么我们如何相信该模型会对新数据做出良好的预测呢?过拟合是由于模型的复杂程度超出所需程度而造成的。机器学习的基本冲突是适当拟合我们的数据,但也要尽可能简单地拟合数据。
机器学习的目标是对从真实概率分布(已隐藏)中抽取的新数据做出良好预测。遗憾的是,模型无法查看整体情况;模型只能从训练数据集中取样。如果某个模型在拟合当前样本方面表现良好,那么你如何相信该模型也会对从未见过的样本做出良好预测呢?
奥卡姆的威廉是 14 世纪一位崇尚简单的修士和哲学家。他认为科学家应该优先采用更简单(而非更复杂)的公式或理论。奥卡姆剃刀定律在机器学习方面的运用如下:
机器学习模型越简单,良好的实证结果就越有可能不仅仅基于样本的特性。
现今,我们已将奥卡姆剃刀定律正式应用于统计学习理论和计算学习理论领域。这些领域已经形成了泛化边界,即统计化描述模型根据以下因素泛化到新数据的能力:
- 模型的复杂程度
- 模型在处理训练数据方面的表现
虽然理论分析在理想化假设下可提供正式保证,但在实践中却很难应用。机器学习速成课程则侧重于实证评估,以评判模型泛化到新数据的能力。
机器学习模型旨在根据以前未见过的新数据做出良好预测。但是,如果要根据数据集构建模型,如何获得以前未见过的数据呢?一种方法是将您的数据集分成两个子集:
- 训练集 - 用于训练模型的子集。
- 测试集 - 用于测试模型的子集。
一般来说,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是:
- 测试集足够大。
- 您不会反复使用相同的测试集来作假。
本文参考谷歌-机器学习教程、Liu-Kevin博客
