
你真的学会RoI Pooling了吗?

有些问题,你不解决,它一直是个问题,并且严重性会越来越大。---榴弹
Faster-RCNN论文中在RoI-Head网络中,将128个RoI区域对应的feature map进行截取,而后利用RoI pooling层输出7*7大小的feature map。
常见的RoI Pooling实现主要有以下四种方式[1]:
(1)、利用cffi进行C拓展实现,然后pytorch调用。需要单独的 C 和 CUDA 源文件,需事先进行编译。
(2)、利用cupy实现在线编译,直接为 pytorch 提供 CUDA 扩展。
(3)、利用chainer实现。
(4)、在pytorch中可以利用:
torch.nn.functional.adaptive_max_pool2d(input, output_size, return_indices=False)
# 或者
torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
# The output is of size H x W, for any input size.Adaptive Pooling的卷积核大小kernel_size由输入input_size和输出output_size决定,这样就保证了不管输入Tensor的size是多少,输出Tensor的大小都是output_size。
其中使用了tensor.narrow()函数,在这里记录一下。
input.narrow(dimension, start, length) → Tensor
# 表示取变量input在第dimension维上,从索引start到start+length范围(不包括start+length)的值。
example:
In [2]: x = torch.Tensor([[1,2,3], [4,5,6], [7,8,9]])
In [4]: x.narrow(0,0,3)
Out[4]:
tensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
In [6]: x.narrow(0,1,2)
Out[6]:
tensor([[4., 5., 6.],
[7., 8., 9.]])
In [7]: x.narrow(1, 1, 2)
Out[7]:
tensor([[2., 3.],
[5., 6.],
[8., 9.]])RoI Pooling反向传播
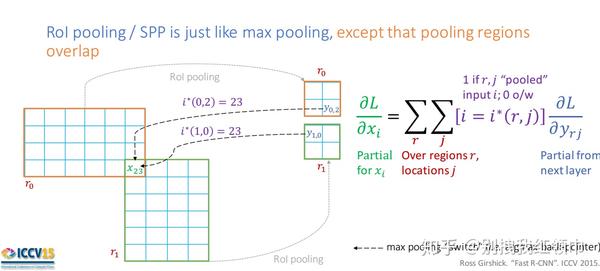
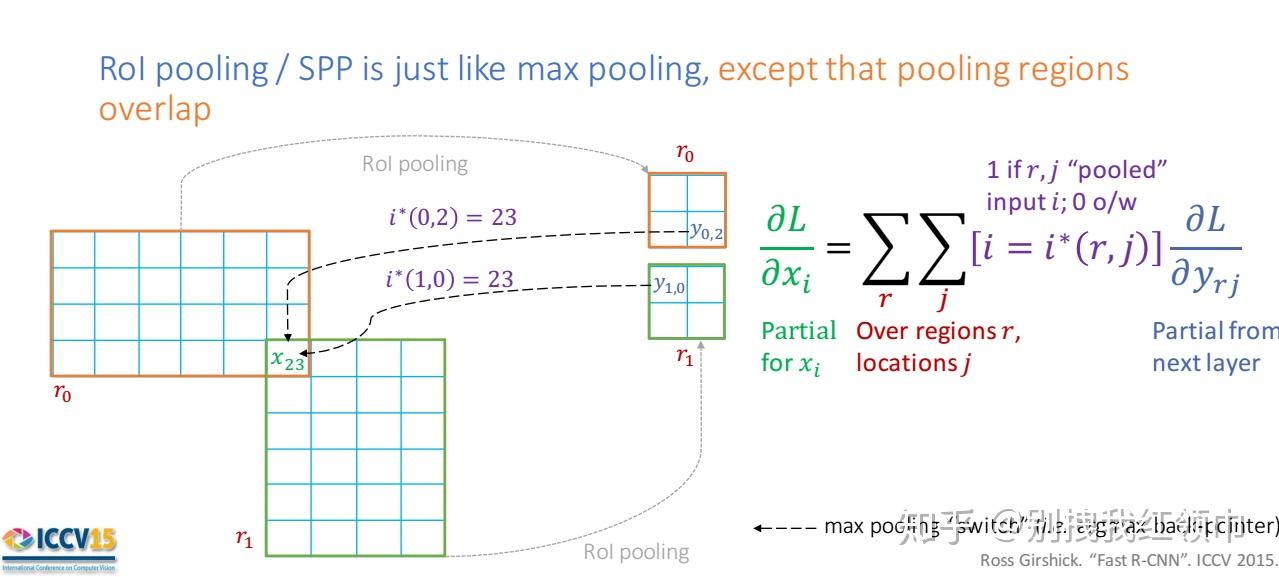
\frac{\partial L}{\partial x_i} = \sum_{r}\sum_{j}[i=i^{*}(r,j)]\frac{\partial L}{\partial y_{rj}} (公式1)
对于RoI Pooling的反向传播公式可以类比max pooling的反向传播公式理解。不同的是,对于每个mini-batch 的RoI r 和每个pooling单元 j 及其输出 y_{rj} ,偏导数 ∂L/∂yrj is accumulated if i is the argmax selected for y_{rj} by max pooling(xi被候选区域r的第j个输出节点选为最大值)。在反向传播过程中, 偏导数 ∂L/∂yrj 已经被RoI pooling层之后的层通过反向传播计算好了。
这里为什么要求和,是因为如图1所示,当不同roi的不同区域出现重叠的情况, y_{0,2} 和 y_{1,0} 对区域 x_{2,3} 的影响,这时候对该区域 x_{2,3}的反向传播值 \frac{\partial L}{\partial x_{2,3}} 应该等于 \frac{\partial L}{\partial y_{0,2}} + \frac{\partial L}{\partial y_{1,0}} 。
RoI Pooling的两次量化过程以及RoI Align是如何改进的?
(1)、在原图上生成的region proposal 映射到feature map需要除以16或者32的时候,边界出现小数,这是第一次量化。
(2)、在每个roi里划分成k×k(7×7)的bins,对每个bin中均匀选取多少个采样点,然后进行max pooling,也会出现小数,这是第二次量化。
ROI Align并不需要对两步量化中产生的浮点数坐标的像素值都进行计算,而是设计了一套优雅的流程。如图2,其中虚线代表的是一个feature map,实线代表的是一个roi(在这个例子中,一个roi是分成了2*2个bins),实心点代表的是采样点,每个bin中有4个采样点。我们通过双线性插值的方法根据采样点周围的四个点计算每一个采样点的值,然后对着四个采样点执行最大池化操作得到当前bin的像素值。
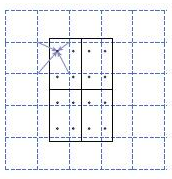
RoI Align做法:假定采样点数为4,即表示,对于每个2.97 x 2.97的bin,平分四份小矩形,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样就会得到四个小数坐标点的像素值。
RoI Align反向传播[5]
\frac{\partial L}{\partial x_i} = \sum_{r}\sum_{j}[d(i, i^{*}(r,j))<1](1-\Delta h)(1-\Delta w)\frac{\partial L}{\partial y_{rj}} (公式2)
类比于ROI Pooling,ROI Align的反向传播需要稍作修改:因为在ROIAlign中, i^*(r,j) 是一个浮点数的坐标位置(前向传播时计算出来的采样点),所以在池化前的特征图中,每一个与 i^*(r,j) 横纵坐标均小于1的点都应该接受与此对应的点 y_{rj} 回传的梯度,故ROI Align 的反向传播公式如公式2所示。 其中, d(.) 表示两点之间的距离, Δh 和 Δw 表示 i 与 i^*(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。直观的理解就是离采样点越近的整数坐标点比重越大,极端的例子是Δh 和 Δw都等于0的时候,就是当前采样点的值。
卷积的反向传播[4]:
为了符合梯度计算,我们在误差矩阵周围填充了一圈0,此时我们将卷积核翻转后和反向传播的梯度误差进行卷积,就得到了前一次的梯度误差。
参考资料:
[1]、https://www.cnblogs.com/king-lps/p/9026798.html
[2]、https://github.com/SirLPS/roi_pooling
[3]、https://blog.csdn.net/xunan003/article/details/86597954
