手把手教你使用TF服务将TensorFlow模型部署到生产环境

摘要: 训练好的模型不知道如何布置到生产环境?快来学习一下吧!


介绍
将机器学习(ML)模型应用于生产环境已成为一个火热的的话题,许多框架提供了旨在解决此问题的不同解决方案。为解决这一问题,谷歌发布了TensorFlow(TF)服务,以期待解决将ML模型部署到生产中的问题。
本文提供了一个关于服务于预先训练的卷积语义分割网络的实践教程。阅读本文后,你将能够使用TF服务来部署和向TF训练的深度CNN发出请求等操作。另外,本文将概述TF服务的API及其工作原理。如果你想学习本教程并在计算机上运行示例,请完整了解本文。但是,如果你只想了解TensorFlow服务,你可以专注于前两部分。
TensorFlow服务库-概述
首先我们需要花一些时间来了解TF Serving如何处理ML模型的整个生命周期。在这里,我们将介绍TF服务的主要构建块,本部分的目标是提供TF服务API的介绍。如需深入了解,请访问TF服务文档页面。
TensorFlow服务由一些抽象组成,这些抽象类用于不同任务的API,其中最重要的是Servable,Loader,Source和Manager,让我们来看看他们之间是如何互动的:
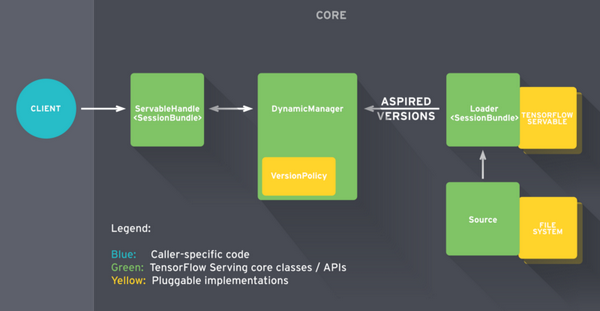

简单来说,当TF Serving识别磁盘上的模型时,Source组件就开始工作啦,整个服务生命周期也算开始了,Source组件负责识别应加载的新模型。实际上,它会密切关注文件系统,以确定新模型版本何时到达磁盘。当它看到新版本模型时,它会为该特定版本的模型创建一个Loader。
总之,Loader几乎了解模型的所有内容,包括如何加载以及如何估计模型所需的资源,例如请求的RAM和GPU内存。Loader还有一个指向磁盘上模型的指针以及用于加载它的所有必要的元数据。但是有一个问题:加载器不允许加载模型。创建Loader后,Source会将其作为Aspired Version发送给Manager。
收到模型的Aspired Version后,Manager继续执行服务过程。这里有两种可能性,一个是推送第一个模型版本进行部署,在这种情况下,Manager将确保所需的资源可用,完成后,Manager会授予Loader加载模型的权限;第二是我们推出现有模型的新版本,在这种情况下,管理员必须先咨询版本策略插件,然后再继续操作,版本策略确定如何进行加载新模型版本的过程。
具体来说,在第一种情况下,我们可以确保我们的系统始终可用于传入客户的请求。此时,我们同时加载了两个模型版本,只有在加载完成后,Manager才会卸载旧版本,并且可以安全地在模型之间切换。另一方面,如果我们想通过不使用额外缓冲区来节省资源,我们可以选择保留数据。最后,当客户端请求模型的handle时,管理器返回Servable的handle。
在接下来的部分中,我们将介绍如何使用TF服务提供卷积神经网络(CNN)。
导出服务模型
为TensorFlow构建的ML模型提供服务的第一步是确保它的格式正确,为此,TensorFlow提供了SavedModel类。
SavedModel是TensorFlow模型的通用序列化格式,如果你熟悉TF,则可以使用TensorFlow Saver来保留模型的变量。
TensorFlow Saver提供了将模型的检查点文件保存到磁盘或从磁盘恢复的功能。实际上,SavedModel包装了TensorFlow Saver,它是导出TF模型进行服务的标准方式。
SavedModel object有一些很好的功能。首先,它允许你将多个元图保存到单个SavedModel对象,换句话说,它允许我们为不同的任务提供不同的图表。例如,假设你刚刚完成了模型的训练。在大多数情况下,要执行推理,你的图表不需要某些特定于训练的操作。这些操作可能包括优化器的变量,学习速率调度张量,额外的预处理操作等。此外,你可能希望为移动部署提供量化版本的图形。
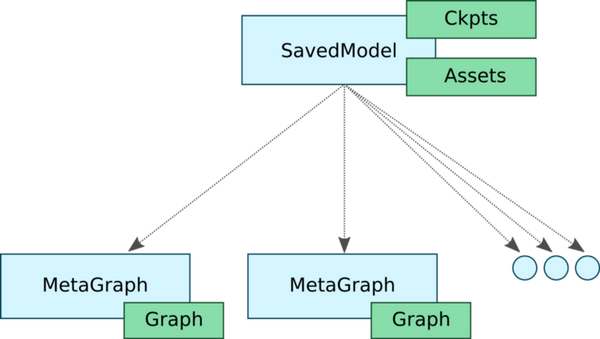

在此环境中,SavedModel允许你使用不同的配置保存图形。在我们的例子中,我们有三个不同的图形和相应的标签,如“训练”、“推理”和“移动”。此外,这三个图形为了提升内存效率还共享相同的变量集。
就在不久前,如果我们想在移动设备上部署TF模型时,我们需要知道输入和输出张量的名称,以便向模型提供数据或从模型获取数据。这需要强制程序员在图的所有张量中搜索他们所需的张量。如果张量没有正确命名,那么任务可能非常繁琐。
为了简化操作,SavedModel提供对SignatureDefs的支持,SignatureDefs定义了TensorFlow支持的计算的签名。它确定了计算图的正确输入和输出张量,也就是说使用这些签名,你可以指定用于输入和输出的确切节点。要使用其内置的服务API,TF Serving要求模型包含一个或多个SignatureDefs。
要创建此类签名,我们需要提供输入,输出和所需方法名称的定义,输入和输出表示从字符串到TensorInfo对象的映射。在这里,我们定义了默认张量,用于向图表输入数据和从图表接收数据。
目前,有三种服务API:分类,预测和回归。每个签名定义都与特定的RPC API相匹配,Classification SegnatureDef用于Classify RPC API,Predict SegnatureDef用于Predict RPC API等等依此类推。
对于分类签名,必须有输入张量(接收数据)和两个可能的输出张量中的至少一个:类或分数。Regression SignatureDef只需要一个张量用于输入,另一个用于输出。最后,Predict signature允许动态数量的输入和输出张量。此外,SavedModel支持数据存储,以用于ops初始化依赖于外部文件的情况,它还具有在创建SavedModel之前清除设备的机制。
现在,让我们看看我们如何在实践中做到这一点。
设置环境
在开始之前,我们需要从Github克隆此TensorFlow DeepLab-v3。DeepLab是谷歌最好的语义分割ConvNet,网络可以将图像作为输入并输出类似掩模的图像,该图像将某些对象与背景分开。
该版本的DeepLab在Pascal VOC分段数据集上进行了训练,因此,它可以分割和识别多达20个类。如果你想了解有关语义分段和DeepLab-v3的更多信息,请查看深入深度卷积语义分段网络和Deeplab_V3。
与服务相关的所有文件都存在于:./deeplab_v3/serving/。在那里,你会发现两个重要的文件:deeplab_saved_model.py和deeplab_client.ipynb。
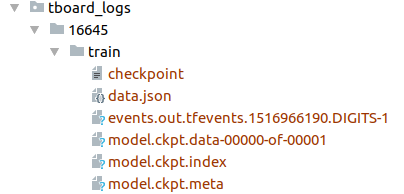
在进一步研究之前,请务必下载Deeplab-v3预训练模型。前往上面的GitHub存储库,单击checkpoints链接,你应该有一个名为tboard_logs /的文件夹,其中包含16645 /文件夹。
现在,我们需要创建两个Python虚拟环境,一个用于Python 3,另一个用于Python 2,请确保安装必要的依赖项。你可以在serving_requirements.txt和client_requirements.txt文件中找到它们。
你可能很好奇为什么需要两个Python env,因为我们的模型DeepLab-v3是在Python 3下开发的,而TensorFlow Serving Python API仅针对Python 2发布。因此,要导出模型并运行TF服务,我们使用Python 3 env 。
请注意,你可以使用bazel中的Serving API放弃Python 2 env。有关更多详细信息,请参阅TF服务实例。完成这一步后,让我们从真正重要的事情开始吧。
实例教程
TensorFlow提供了一个易于使用的高级实用程序类使用SavedModel,类名为SavedModelBuilder。SavedModelBuilder类提供了保存多个元图,关联变量和数据的功能。让我们来看一个如何导出Deep Segmentation CNN模型进行服务的运行示例。
如上所述,要导出模型,我们使用啦SavedModelBuilder类。它将生成SavedModel协议缓冲区文件以及模型的变量和资源。
让我们剖析一下代码:
# Create SavedModelBuilder class
# defines where the model will be exported
export_path_base = FLAGS.export_model_dir
export_path = os.path.join(
tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(FLAGS.model_version)))
print('Exporting trained model to', export_path)
builder = tf.saved_model.builder.SavedModelBuilder(export_path)SavedModelBuilder接收(作为输入)保存模型数据的目录。这里,export_path变量是为了连接export_path_base和model_version。因此,不同的模型版本将保存在export_path_base文件夹内的单独目录中。
假设我们在生产中有我们模型的基础版本,但我们想要部署它的新版本。因为我们已经提高了模型的准确性,并希望为我们的客户提供这个新版本。要导出同一模型的不同版本,我们只需将FLAGS.model_version设置为更高的整数值即可。然后将在export_path_base文件夹中创建一个不同的文件夹(保存我们模型的新版本)。
现在,我们需要指定模型的输入和输出Tensors。为此,我们使用SignatureDefs,签名定义了我们要导出的模型类型。它提供了从字符串(逻辑Tensor名称)到TensorInfo对象的映射。我们的想法是,客户端可以引用签名定义的逻辑名称,而不是引用输入/输出的实际张量名称。
为了服务语义分段CNN,我们将创建一个预测签名。请注意,build_signature_def()函数采用输入和输出张量的映射以及所需的API。
SignatureDef需要指定:输入,输出和方法名称,我们期望输入有三个值:一图像,另外两个张量指定其尺寸(高度和宽度)。对于输出,我们只定义了一个结果-分段输出掩码。
# Creates the TensorInfo protobuf objects that encapsulates the input/output tensors
tensor_info_input = tf.saved_model.utils.build_tensor_info(input_tensor)
tensor_info_height = tf.saved_model.utils.build_tensor_info(image_height_tensor)
tensor_info_width = tf.saved_model.utils.build_tensor_info(image_width_tensor)
# output tensor info
tensor_info_output = tf.saved_model.utils.build_tensor_info(predictions_tf)
# Defines the DeepLab signatures, uses the TF Predict API
# It receives an image and its dimensions and output the segmentation mask
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': tensor_info_input, 'height': tensor_info_height, 'width': tensor_info_width},
outputs={'segmentation_map': tensor_info_output},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))请注意,字符串‘image',‘height',‘width'和‘segmentation_map'不是张量。相反,它们是引用实际张量input_tensor,image_height_tensor和image_width_tensor的逻辑名称。因此,它们可以是你喜欢的任何唯一字符串。此外,SignatureDefs中的映射与TensorInfo protobuf对象有关,而与实际张量无关。要创建TensorInfo对象,我们使用实用程序函数:tf.saved_model.utils.build_tensor_info(tensor)。
现在我们调用add_meta_graph_and_variables()函数来构建SavedModel协议缓冲区对象,然后我们运行save()方法,它会将模型的快照保存到包含模型变量和资源的磁盘。
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict_images':
prediction_signature,
})
# export the model
builder.save(as_text=True)
print('Done exporting!')现在我们可以运行deeplab_saved_model.py来导出我们的模型。
如果一切顺利,你将看到文件夹./serving/versions/1,请注意,“1”表示模型的当前版本。在每个版本子目录中,你将看到以下文件:
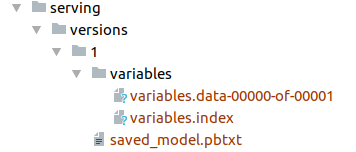
·saved_model.pb或saved_model.pbtxt,这是序列化的SavedModel文件。它包括模型的一个或多个图形定义,以及签名定义。
·变量,该文件夹包含图形的序列化变量。
现在,我们已准备好启动我们的模型服务器。为此,请运行:
$ tensorflow_model_server --port=9000 --model_name=deeplab --model_base_path=<full/path/to/serving/versions/>该model_base_path指的是输出模型保存,另外,我们不在路径中指定版本文件夹,模型版本控制由TF服务处理。
生成客户端请求
客户端代码非常简单,看一下:deeplab_client.ipynb。首先,我们读取要发送到服务器的图像并将其转换为正确的格式。接下来,我们创建一个gRPC存根,存根允许我们调用远程服务器的方法。为此,我们将实例化prediction_service_pb2模块的beta_create_PredictionService_stub类。此时,存根保持调用远程过程的必要逻辑,就像它们是本地的一样。
现在,我们需要创建和设置请求对象。由于我们的服务器实现了TensorFlow Predict API,因此我们需要解析Predict请求。要发出Predict请求,首先,我们从predict_pb2模块中实例化PredictRequest类。我们还需要指定model_spec.name和model_spec.signature_name参数。该名称参数是当我们推出的服务器定义的“模型名称”的说法,而signature_name是指分配给逻辑名称signature_def_map()的参数add_meta_graph()函数。
# create the RPC stub
channel = implementations.insecure_channel(host, int(port))
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
# create the request object and set the name and signature_name params
request = predict_pb2.PredictRequest()
request.model_spec.name = 'deeplab'
request.model_spec.signature_name = 'predict_images'
# fill in the request object with the necessary data
request.inputs['images'].CopyFrom(
tf.contrib.util.make_tensor_proto(image.astype(dtype=np.float32), shape=[1, height, width, 3]))
request.inputs['height'].CopyFrom(tf.contrib.util.make_tensor_proto(height, shape=[1]))
request.inputs['width'].CopyFrom(tf.contrib.util.make_tensor_proto(width, shape=[1]))接下来,我们必须提供服务器签名中定义的输入数据。请记住,在服务器中,我们定义了一个Predict API来预期图像以及两个标量(图像的高度和宽度)。为了将输入数据提供给请求对象,TensorFlow提供了实用程序tf.make_tensor_proto(),此方法是从Python/numpy创建的TensorProto对象,我们可以使用它将图像及其尺寸提供给请求对象。
看起来我们已经准备好调用服务器了。为此,我们调用Predict()方法(使用存根)并将请求对象作为参数传递。gRPC支持:同步和异步调用。因此,如果你在处理请求时想要做一些工作,我们可以调用Predict.future()而不是Predict()。
# sync requests
result_future = stub.Predict(request, 30.)
# For async requests
# result_future = stub.Predict.future(request, 10.)
# Do some work...
# result_future = result_future.result()现在我们可以获取并享受结果。


以上为译文,由阿里云云栖社区组织翻译。
文章原标题《how-to-deploy-tensorflow-models-to-production-using-tf-serving》
作者:Thalles Silva,译者:虎说八道,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
本文为云栖社区原创内容,未经允许不得转载。
