8.9 启发式搜索


在人工智能领域经典的状态空间规划算法是决策时规划,这类算法也被总称为启发式搜索。本节将介绍什么是启发式搜素以及启发式搜索的应用。
启发式搜索
在启发式搜索中,每当遇到一个状态,就可能出现的很多后续的状态,这些状态和分支就构成了一棵树。树叶子节点的值是近似值函数,然后向前备份直到当前的状态。一旦计算出了每个节点的备份值,我们就选择具有组好备份值的动作作为当前的动作,然后所有备份值都被丢弃了。
所有我们可以看到,启发式搜索其实和前面讲的n-step TD算法很像,尤其是前面讲的树备份算法。除了不保存备份值。实际上,在启发式搜索中值函数通常是人为设计的,并且保持不变。但是,更合理的做法是利用搜索过程中的备份值,或者书中讲的其他方法来逐渐的改变值函数。
如果考虑启发式搜索备份的过程,其实贪婪算法, \varepsilon -贪婪算法或者是UCB行为选择方法和启发式搜索也很像,这是规模小一些。例如,给定环境模型和一个状态值函数,为了选择贪婪的行为,我们必须往前看一步,找到所有可能的下一个状态(搜索),然后利用当前回报和估计的下一个状态的值函数(备份)来选择最佳的动作(其实就是one-step的值迭代)。传统的启发式搜索也是同样的思路,只是不保存备份值。因此,启发式搜索可以看成是贪婪策略的多步扩展。
为什么不用单步搜索,而是往更深的搜索,目的在于获得更好的动作选择。如果我们有一个完美的模型和一个步准确的值函数,那么搜索越深通常会得到更好的策略。怎么理解呢?模型是理想的意味着我们搜索的方向是对的,值函数不准确会影响我们备份值的计算。但是搜索越深,值函数对于备份值的影响就越小了,如果一直搜索到一个episode的末尾,那么就类似于MC方法,得到的备份是精确的,不再受到值函数的影响。当然如果搜索到第 k 层,且\gamma^k 足够小,那么得到的动作也是接近最优的。这是因为\gamma^k 足够小,那么 \gamma^k V(S_{t+k}) 对于备份值的影响也很小了。所以得到的动作依然是接近最优的。但是另一个方面,搜索的越深,需要的计算量也越大,响应时间就越慢。一个例子就是Tesauro编写的下双陆棋的程序。这个系统利用TD学习方法来学习afterstate值函数,使用启发式搜索来决定如何走每一步。对于模型,TD-Gammon 假设对手总是选择TD-Gammon 认为最好的动作。Tesauro发现搜索的越深,TD-Gammon就表现的越好,但是每一步花费的时间也越长。TD-Gammon具有很多的分支,导致其计算量随着搜索深度增长很快。因此通常它只能搜索几步。但是即使这样,搜索也会明显的改善动作的选择。
为什么启发式搜索会如此高效?
启发式搜索的一个特点是:专注于当前的状态。在你下棋的时候,无论你采取什么样的策略,你总是最关心当前这一步该怎么走,当前状态的值函数是否准确也是最为紧要的。而启发式搜索总是通过搜索来更新当前状态的值。这样就能将计算资源和内存资源优先使用在我们关系的当前状态上,因此十分高效。
深度优先搜索
启发式搜素一种可能的情形如下:
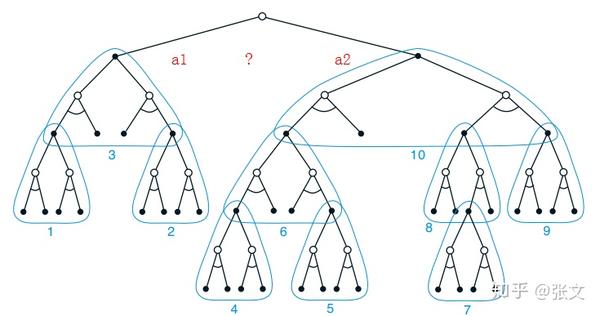

我们通过自下向上的单步更新(注意1到10的每一步都是一个单步的更新),通过拼接这些更新,获得上一层的更新,最终得到根节点的值函数,这种更新次序叫做深度优先启发式搜索(depth-first heuristic search)。比如上图中1,2,3对应更新的状态形成了一个子树。更新4-10形成了另一棵树。通过两个子树的更新,分别得到a1的值为8,a2的值为10,那么启发式搜索就会在当前状态选择a2,然后继续下一步的搜索。
