
ICLR 2023 | DIVERSIFY: 针对动态数据分布的OOD表征学习新范式

「分布外泛化」(Out-of-distribution generalization) 是机器学习中的一个重要问题。 特别地,有别于传统假设认为数据分布是给定的一个静态分布,我们认为真实生活中的数据应该是「动态变化」的。 例如,人的面部、地区的卫星图、人的声音等,均会随着时间进行动态变化。 已有的针对静态分布进行OOD泛化的工作无法处理此动态分布的情形。 以时间序列为例,本文尝试从分布的角度来看待此问题。 我们认为,针对分布动态变化的数据集而言,其复杂性可能归因于存在「未知的潜在分布」。 为此,我们提出 「DIVERSIFY」 用于动态分布的泛化表示学习。 通过挖掘数据的潜在分布,利用对抗的形式,DIVERSIFY获取的特征表示更加「多样」、「鲁棒」、「有效」。 我们从理论和经验上对所提出的方法给出支持。 对多个时间序列公开数据集进行实验验证,实验结果表明,DIVERSIFY获得的特征更多样鲁棒,可以获得更好的效果,且所提出的方法对场景依赖度低,更加通用、容易拓展到其他非时间序列数据,如图像和视频中。
该研究成果已被「ICLR 2023」接收。第一作者为微软亚洲研究院实习生、博士生卢旺,通讯作者为王晋东。其他作者来自复旦大学。
- 论文标题:Out-of-distribution representation learning for time series classification
- 链接:https://arxiv.org/abs/2209.07027
- Openreview:https://openreview.net/pdf?id=gUZWOE42l6Q
- 代码:https://github.com/microsoft/robustlearn


背景介绍
真实世界的数据分布是动态的,还是静态的?
绝大多数研究工作均假设给定的数据服从一个静态的环境分布。如,给定“简笔画”和“照片”两个分布下的图像,学习一个可以泛化到艺术画的分类器(图(a))。我们便想挑战这一点:来自“简笔画”中的所有图像,真的只服从一个数据分布吗?
另一方面,更一般的情形则不会「显式」给定训练数据的领域分布,即:给定一个训练集,其中可能包含若干个「未知的、不同的」数据分布,如何学习一个OOD分类器(图(b))?
我们将上述问题抽象为:动态分布数据的OOD泛化表征学习。
已有的OOD研究大多集中于给定数据分布下的泛化,在此方面有大量的研究工作。详细可参考我们的领域泛化综述文章。静态方法直接应用于动态数据,则会出现极大的误差(图(c))。 而由于动态数据的分布随时间不断变化,其自身包含「多样化」的分布信息,需加以利用才能实现更好的泛化效果。
在本文中,我们以时间序列为例对此问题进行研究。但需注意的是,我们的方法针对静态数据和其他模态的动态数据同样有效。
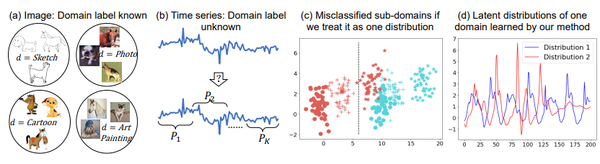
什么是动态的领域和分布偏移?
时间序列可能包含几个未知的潜在分布(域)。 例如,三个不同人的数据可能由于个体自身的差异性而属于不同的分布。 这可以理解为「空间分布偏移」。 令人惊讶的是,我们甚至在数据中发现了「时间分布偏移」,即一个人的数据分布在不同时间点可能存在差异。 由于非平稳属性,将时间序列数据视为同分布的常规方法无法获取域不变特征,因为它们忽略了数据自身分布的多样性。 如果不考虑潜在分布的差异性,直接使用常规方法获取的分类效果往往不好。 在上图 (d) 中,我们给出了一个案例。 因此,挖掘时间序列中的潜在分布,以学习更好的OOD特征,具有重要意义。此项工作是我们之前在CIKM 2021提出的AdaRNN方法的端到端延续和简化。
我们的方法:Diversify
在这项工作中,我们提出了 Diversify, 一种针对动态分布分布进行表示学习的OOD泛化方法。 DIVERSIFY通过「表征数据内部的潜在分布」来进行时间序列分类。 具体来说,DIVERSIFY 由一个「最小-最大对抗游戏」构成: 一方面,它通过最大化潜在分布差异性将时间序列数据分割成几个潜在的子域以保持多样性,即“最坏情况” 分布场景; 另一方面,它通过减少获得的潜在域之间的分布差异来学习域不变表示。 这种潜在分布广泛存在于时间序列中,例如,来自多个人的行为数据可能遵循不同的分布,来自一个人不同时间的行为数据也可能遵循不同的分布。 定性和定量实验结果证明了 DIVERSIFY 的优越性。
注意,整个方法的细节部分较多,我们在这里仅介绍最重要的部分。更多细节请看原论文。
整体框架
DIVERSIFY 的核心是表征潜在分布,然后最小化两两之间的分布差异。 整个算法通过迭代完成,首先从给定的数据集中获得“最坏情况”的分布,然后弥合每对潜在分布之间的分布差距。 下图描述了其主要过程,具体步骤如下:
- 预处理:该步骤采用滑动窗口将整个训练数据集分割成固定大小的窗口。 我们认为来自一个窗口的数据构成最小的数据单元。
- 细粒度特征更新:这一步使用建议的伪域类标签作为监督来更新特征提取器。
- 潜在分布表示: 这一步旨在识别每个实例的域标签以获得潜在分布信息。 它最大化不同的潜在分布的差异性以扩大多样性。
- 域不变表示学习:这一步利用上一步中的伪域标签来学习域不变表示,并获取泛化模型。

细粒度特征更新
在表征潜在分布之前,我们执行细粒度特征更新以获得细粒度表示,如上图蓝色部分所示。 我们提出了一个新概念:「伪域类标签」,作为特征提取器的监督,以充分利用域和类中包含的信息。 我们将每个域的每个类别视为一个新类别,标签为s,则有
s = d'\times C + y \\
其中d^\prime是伪域标签,C是类别数量,y是当前样本类别所属类别。 在第一次迭代中,没有初始域标签,我们简单地假设所有样本属于域0。 利用新定义的伪域类标签,我们更新整个模型,包含特征提取器。 注意为了计算效率,我们仅在这一步更新特征提取部分。
\mathcal{L}_{super} = \mathbb{E}_{(\mathbf{x},y)\sim \mathbb{P}^{tr}} \ell \left(h_{c}^{(2)}(h_{b}^{(2)}(h_f^{(2)}(\mathbf{x}))),s \right) \\
潜在分布表示
此步骤表征一个数据集中包含的潜在分布, 如上图绿色部分所示。 我们提出了一种改进的对抗训练版本,以将域特征与类特征分离。 采用自我监督的伪标记策略来获取域标签。 首先利用类不变特征获取各域初始中心。
\tilde{\mu}_k = \frac{\sum_{\mathbf{x}_i \in \mathcal{X}^{tr}} \delta_k(h_{c}^{(3)}(h_{b}^{(3)}(h_f^{(3)}(\mathbf{x}_i)))) h_{b}^{(3)}(h_f^{(3)}(\mathbf{x}_i))}{\sum_{\mathbf{x}_i\in \mathcal{X}^{tr}} \delta_k(h_{c}^{(3)}(h_{b}^{(3)}(h_f^{(3)}(\mathbf{x}_i))))} \\
然后获取每个样本所属域类别。
\tilde{d}'_i = \arg\min_k D(h^{(3)}_{b}(h^{(3)}_f(\mathbf{x}_i)), \tilde{\mu}_k) \\
再迭代一次,获取最终域标签。
\mu_k = \frac{\sum_{\mathbf{x}_i\in \mathcal{X}^{tr}} \mathbb{I}(\tilde{d}'_i=k) h^{(3)}_{b}(h^{(3)}_f(\mathbf{x}))}{\sum_{\mathbf{x}_i\in \mathcal{X}^{tr}} \mathbb{I}(\tilde{d}'_i=k)}, d'_i = \arg\min_k D(h^{(3)}_b(h^{(3)}_f(\mathbf{x}_i)), \mu_k) \\
获取域标签之后,采用类似DANN的对抗方式,进行类不变域特征学习。
\mathcal{L}_{self} + \mathcal{L}_{cls} = \mathbb{E}_{(\mathbf{x},y)\sim \mathbb{P}^{tr}} \ell(h^{(3)}_c(h^{(3)}_b(h^{(3)}_f(\mathbf{x}))),d') + \ell(h^{(3)}_{adv}(R_{\lambda_1}(h^{(3)}_b(h^{(3)}_f(\mathbf{x})))),y) \\
域不变表示学习
获得潜在分布后,我们学习域不变表示以进行泛化。 直接借鉴DANN,利用梯度反转层进行实现。
\mathcal{L}_{cls} + \mathcal{L}_{dom} = \mathbb{E}_{(\mathbf{x},y)\sim \mathbb{P}^{tr}} \ell(h_{c}^{(4)}(h_{b}^{(4)}(h_f^{(4)}(\mathbf{x}))),y) + \ell(h_{adv}^{(4)}(R_{\lambda_2}(h_{b}^{(4)}(h_f^{(4)}(\mathbf{x})))),d') \\
小结
重复上述步骤,直至收敛或达到最大迭代次数。 与现有方法不同的是,DIVERSIFY的最后两步只优化了最后几层线性层,而不优化特征提取器。 大部分可训练参数在模块之间共享。 推理预测时仅使用特征提取器和分类部分的线性层。 因此DIVERSIFY与现有方法具有相同的模型规模。
理论见解
我们还提供了理论见解,来说明为什么我们如此设计方法。
简而言之:关注下面的 target risk bound,其最后一项 maximum difference 恰恰是我们要优化的那个 worst-case distribution scenario,这与我们的假设是一致的,充分表明了此算法的理论正确性。


上式中,右边第一项可以被忽略,第二项是常见的分类监督损失。 第三项无法直接预估。为了减少第三项,我们可以尝试增大S的覆盖范围,这也是我们设计“最坏情况”的动机所在,对应DIVERSIFY第三步。 最后一项要求减小域间差异,也就对应DIVERSIFY的第四步。
实验结果
我们进行了充分的实验来证明我们方法的有效性。注意在实验中部分对比方法需要初始域标签,我们的方法则无需域标签,因此通用性更广。
肌电信号数据集(跨人)
从下表可以看出,在公平的对比下,我们的方法提高了 4.3%。 甚至与有更强特征提取器的AdaRNN相比,我们的方法仍然有提升。

语音识别数据集(一般情形)
从下图中可以看出,在公平的对比下,我们的方法分别提高超过 1% 和0.6%。

压力情绪检测数据集(大数据集)
从下图中我们可以看出,在公平的对比下,我们的方法提高超过8%。

行为识别数据集(单源、跨位置、跨数据集)
从下表中我们可以看出,在公平的对比下,我们的方法分别提高1.4%, 9.9%, 和 5.8%。

消融性分析
我们还进行了消融性实验,表明我们方法每个组成部分的有效性。

定性分析及可视化
我们还进行了定性分析及可视化。 从下图定性分析中,我们可以看出潜在分布的确广泛存在:一个未知的分布可以被我们学习出特定的隐藏分布!我们的方法获取的域间差异的确更大。

从下图可视化分析中,我们可以看出我们获取的潜在分布效果以及域不变特征效果更好,因此我们的方法最终效果自然而然更佳。

更多的实验和分析请参考原文。
总结
在本文中,我们提出 DIVERSIFY 来学习时间序列分类的域外泛化表示。 DIVERSIFY 采用一种对抗性游戏,可以获取“最坏情况”的潜在分布,同时最小化潜在分布两两之间的分布差异。 我们展示了Diversiy在不同应用场景中的有效性。 令人惊讶的是,不仅仅是混合数据,来自同一个人的数据也可能包含多个潜在分布。 表征这种潜在分布将大大提高模型对未见不可知数据集的泛化性能。 未来我们可能考虑将DIVERSIFY扩展到预测问题,可能尝试自动学习潜在分布的数量,可能考虑潜在分布背后的语义信息,以获取泛化能力更强、解释性更好、自动化程度更高的方法。
后记
本研究工作完成于2021年下半年、第一次投稿ICLR 2022就获得了866的分数,排在当年的Top 13%,似乎极有可能中稿。但是由于不可知的原因最终遗憾被拒。由此导致本文在接下来一年的时间里陆续辗转于ICML、NeurIPS,最终万幸被今年的ICLR 2023所接收。之前还被Google Research VP Corinna Cortes和"Foundations of ML"一书的作者Mehryar Mohri团队索要过代码表示进一步的兴趣。在这里作者特别感谢每一位合作者的坚持和支持者的帮助。中稿ICLR并不是结局,希望我们今后能对此研究进行更大的扩展、更希望此工作能启发到更多的研究者。
本文更多相关工作和介绍,请见迁移学习导论第二版:
References
[1] Jindong Wang , Cuiling Lan, Chang Liu, Yidong Ouyang, Tao Qin, Wang Lu, Yiqiang Chen, Wenjun Zeng, and Philip S. Yu. Generalizing to Unseen Domains: A Survey on Domain Generalization. TKDE 2022.
[2] Lu, Wang, Jindong Wang, Xinwei Sun, Yiqiang Chen, and Xing Xie. Out-of-distribution Representation Learning for Time Series Classification. In International Conference on Learning Representations. 2023.
