
美团酒旅图谱构建及应用

导读:本次分享的内容是美团酒旅图谱的构建与应用。在美团酒旅业务的垂直搜索中,用户的需求大致可分为两类:明确找店、找具有某些属性的同类商户(泛场景需求)。为解决传统文本检索对于泛场景需求效果不佳的问题,我们以生活服务领域海量评论数据、搜索日志等作为主要数据源,通过标签挖掘、标签关系判别及标签商户关联等技术,梳理用户的场景需求,完成初版图谱构建;并将图谱应用到搜索场景中,提升用户体验和场景认知能力。
今天的介绍会围绕下面四点展开:
1. 背景与简介
2. 酒旅图谱构建
3. 酒旅图谱应用
4. 总结与展望
分享嘉宾|彦虹羽 美团 算法开发
编辑整理|周杰 国防科技大学
出品社区|DataFun
01/背景与简介
首先和大家分享下酒旅业务的背景与简介。
1. 酒旅业务的业务特点
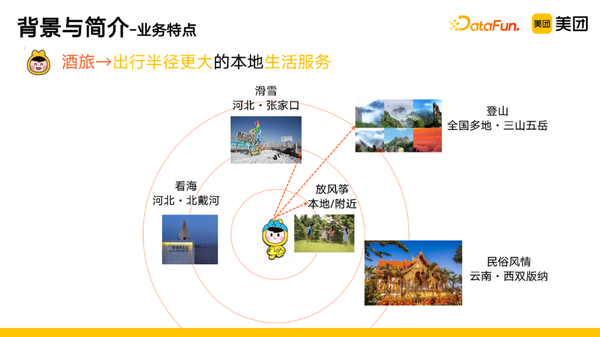

对于酒旅业务,我们可以把它理解成出行半径更大的本地生活服务。以我个人为例,我的常驻城市是北京,如果我周末想要去放风筝,那么我会选择离我比较近的公园或广场;如果想去滑雪、看海,那就要去远一点的张家口、北戴河;如果还想去打卡三山五岳,那就会涉及全国多个省份。在这个过程中,出行半径不断地扩大。




在酒旅的垂直业务搜索领域中,用户和美团app交互的主体主要是实体店家,我们称之为POI。举一个例子,用户找酒店的方式有三种:
- 商家/品牌,如昆泰酒店。
- 地标/商圈,如搜索望京附近的酒店。
- 泛场景(类型/设施/房型),根据自己特定的需求搜索,如电竞酒店。
2. 酒旅场景的认知
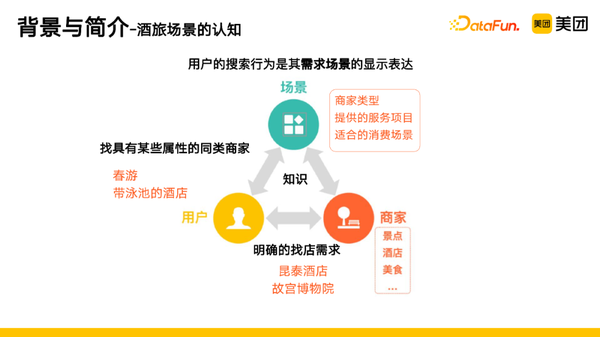

用户的搜索行为是其需求场景的显示表达,所以可以将上述的需求大致分为两类:
- 明确的找店需求,具体的酒店、美食等搜索。
- 找具有某些属性的同类商家,比如能够提供某些服务项目的一类商家。
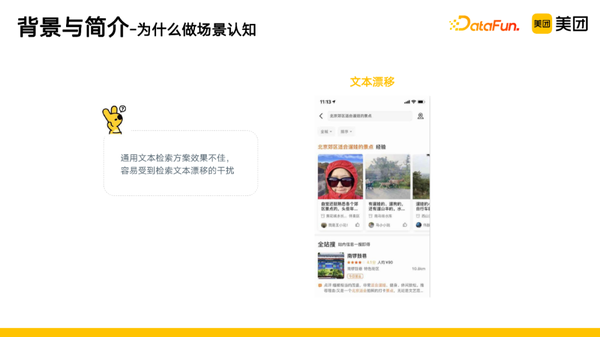
为什么要做场景认知?主要有以下几个原因:
- 通用文本检索方案效果不佳,容易受到检索文本漂移的干扰,比如在搜索“北京郊区适合遛娃的景点”时,返回“南锣鼓巷”,但这并不是一个郊区景点。

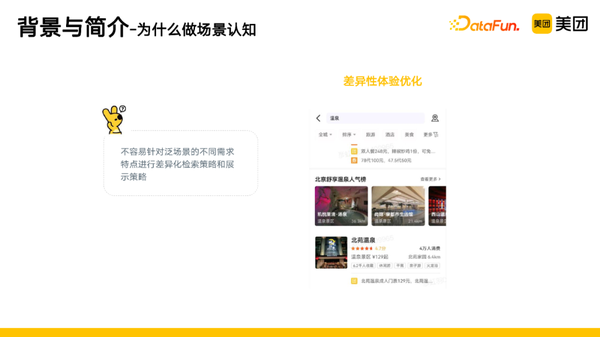
- 不容易针对泛场景的不同需求特点进行差异化检索策略和展示策略,比如会有一些“榜单”类的需求。

3. 场景认知的难点
对于场景认知,主要有两大难点:
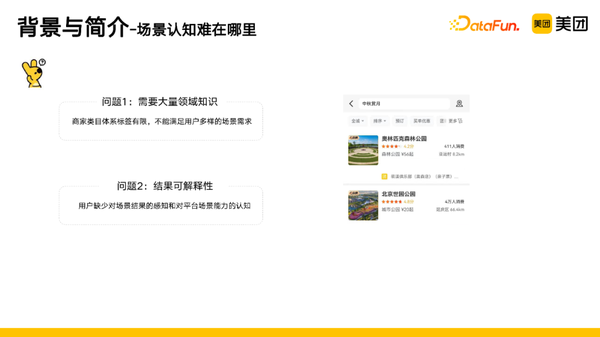

- 对于泛场景类的需求理解,我们需要拥有大量的领域知识,在美团的平台内部会有一些类目的体系标签,但是数据有限,无法满足用户多样性的需求。如图中右边的例子,用户的需求是中秋赏月,我们需要提前知道哪些商户是适合赏月的。
- 结果可解释性。如果返回的结果可解释性不足,会导致用户缺少对我们场景结果的感知以及对于平台场景能力的认识。如右边的例子,如果没有可解释性,用户就会不知道为什么这些商户可以满足自己的需求。


所以,我们启动了酒旅图谱的探索,将文本相关性转变为场景相关性。
--
02/酒旅图谱构建
1. 酒旅图谱特点
酒旅图谱主要有三大特点:
- 节点类型丰富,不仅包括传统的服务类项目,还涉及酒旅场景特有的类型:历史事件(九一八事变)、人物(杜甫)、作品(会当凌绝顶)。
- 相比于餐饮/休娱类POI,酒旅类POI结构化/半结构化数据少,主要集中于非结构化数据,如用户评论、搜索日志等,导致挖掘难度较大。
- 时空特性强,酒旅业务与季节、地域等时空特征的结合较为紧密,在实际应用中,需考虑时效性特点。
2. 酒旅图谱概览
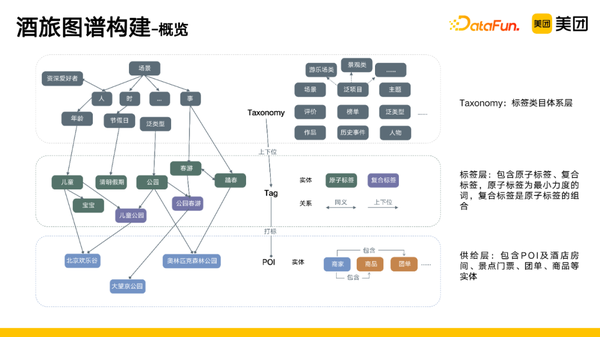

酒旅图谱大致分为三层:
- 第一层是 Taxonomy:标签类目体系层,可以通过算法以及人工的方式构建出类目体系。
- 第二层是标签层:扩充体系下的标签,包含原子标签、复合标签,原子标签为最小力度的词,复合标签是原子标签的组合。这一层主要涉及的关系是同义关系和上下位关系。
- 当有了大量的标签之后,我们需要和供给层进行关联,主要包含 POI 及酒店房间、景点门票、团单、商品等实体。
目前构建的酒旅图谱现状是,有1000万+的节点,1亿+的关系,对于核心关系的准确率达到95%左右。
3. 酒旅图谱构建的技术模块--知识挖掘
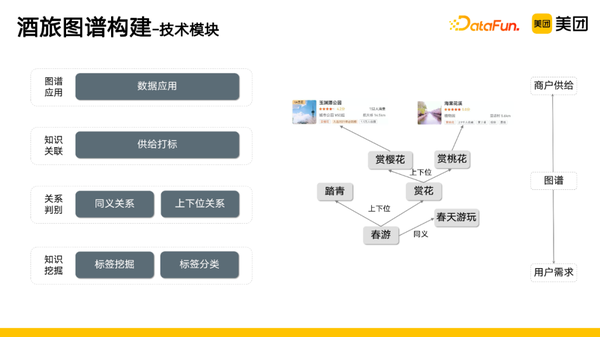

酒旅图谱主要分为四个模块,分别是:
- 知识挖掘,涉及标签的挖掘以及分类。
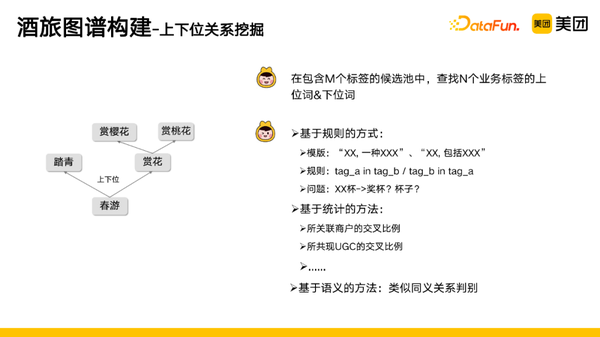
- 关系判别,判别同义关系和上下位关系,比如图右边的例子,春游的下位词是赏花、踏青,赏花的下位词有赏桃花、赏樱花等,春游的同义词是春天游玩。
- 知识关联,将挖掘的知识和供给进行打标。
- 图谱应用。


在知识挖掘层中,主要的数据源来自:
- 结构化数据,平台内部中有商户的名字、所在城市、类别。
- 半结构化数据,从百度百科等收集进行整理。
- 平台内部大量的非结构化数据,包括搜索日志、问答、评论、攻略等。
基于上面的数据源,首先进行知识抽取工作,在此基础上进行知识分类。比如图上的泰山风景区,涉及一些活动场景、作品、人物类节点;这些节点再细分,又涉及到人群、主题、文章诗词、诗人作家等节点。
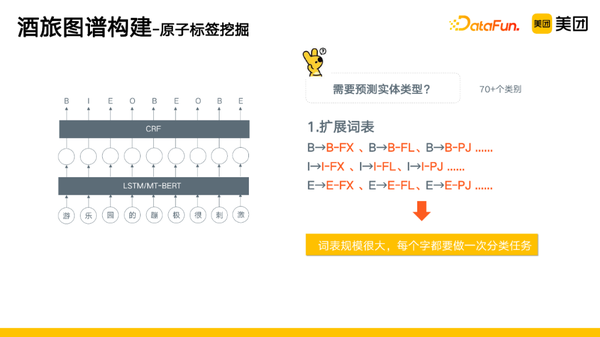
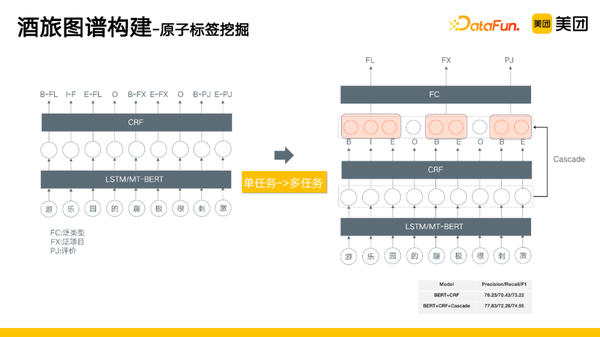
那么,原子标签是怎么挖掘的?在我们的场景中,我们需要预测实体类型,有以下几种方案:
- 扩展词表:将B扩展为多种类别,将I扩展为多种类别,但是这会导致词表规模很大,每个字都需要做一次分类任务,不仅带来耗时增长,同时准确率也会有一点降低。

- 对挖掘片段进行分类:如将公园分到[泛类型],将创极速光轮分到[泛项目-游乐场类]。这是一个短文本分类问题,因为缺少上下文,难度较大。


- 在我们的场景下,将单任务转化为多任务问题
- ,首先去挖掘一些想要的片段,再回去查找这些片段的表示层,再接全连接层进行分类。实验效果看,耗时降低较明显,精确率和F1值都有提升。

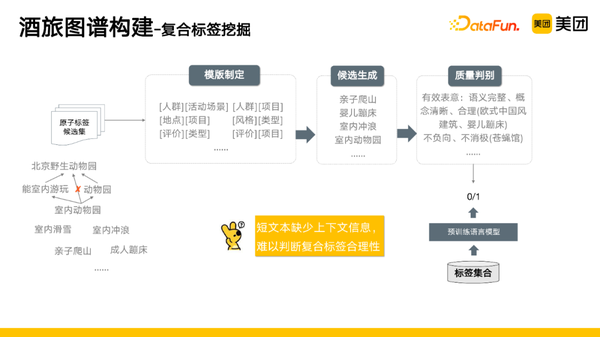
但是原子标签并不能够满足用户的需求,比如,用户会有一些复合类的场景需求,像室内滑雪、亲子爬山。如果仅是将这些原子标签进行组合,通常会出现语义漂移的问题,比如“室内动物园”,用户想找的可能是室内的萌宠乐园,但是返回的组合结果是有室内项目的动物园——“北京野生动物园”。因此我们采取的做法是,首先去制定一些模板,然后生成大量的候选,再进行质量判别,去除那些语意不完整、概念不清晰等语意表达不清的标签。但是短文本缺少上下文信息,很难判别复合标签的合理性。

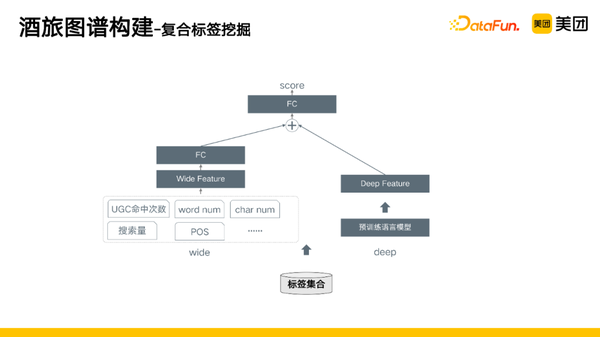
因此,我们从deep和wide两个角度去挖掘特征,再通过全连接层得到最终分数。
- deep,用预训练语言模型去挖掘深层次的语义特征。
- wide,加入一些统计信息、词性信息生成 wide 特征。

4. 酒旅知识图谱构建的技术模块--关系判别
关系判别主要是判别同义关系和上下位关系。
首先是同义词挖掘。
- 任务定义:在包含M个标签的侯选池中,查找N个业务标签的同义词。
- 方法:①整合结构化、半结构化数据库,如百度百科、同义词词林等;②基于规则的相似度计算方法,如利用编辑距离、词向量相似度计算等。
- 目标:通用性强、泛化性强的标签同义词挖掘方案。
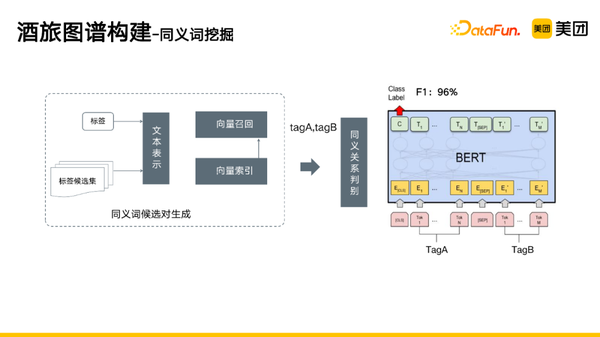

具体过程如下:首先将标签和标签候选集的到文本的向量表示,通过向量索引、相似度计算等,得到向量召回的结果,这样就生成了一些同义词候选对。
还有一些小tips:
- 在同义词挖掘中,要明确同义词的定义是什么,在这里我们只需要定义需求上的同义,比如“游泳池”和“有游泳池”都是要找有游泳池的地方,所以这三个是可以同义的。所以我们要先明确任务的粒度大小,然后定义好边界,再逐渐去构造一些有难度的正负样本,然后通过训练方法,使用样本去靠近分类的边界。
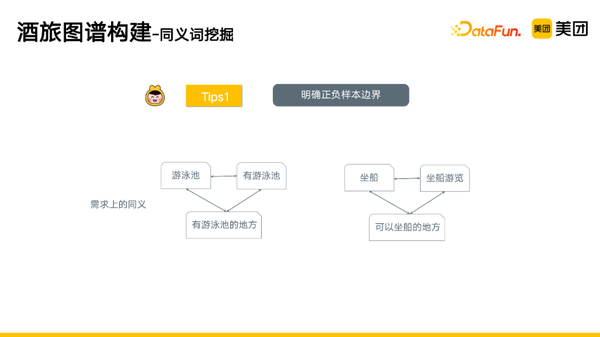

- 数据增强。清洗样本,避免过拟合极端样本;扩充样本,对称扩充、传递扩充等;引入对抗训练等。
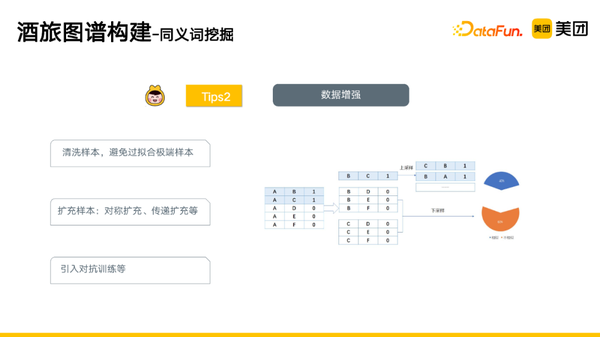

- 采用主动学习的方法,提升标注效率,降低标注成本。具体地,我们采用了一种UCS的主动学习方法。


然后是上下位关系挖掘:
- 任务定义:在包含M个标签的侯选池中,查找N个业务标签的上位词和下位词。
- 方法:①基于规则的方式,给定模板和规则;②基于统计的方法,如所关联商户的交叉比例、所共现UGC的交叉比例;③基于语义的方法,类似同义关系判别。

5. 酒旅知识图谱的技术模块--知识关联
知识关联是将我们挖掘的知识和我们的供给进行打标。


- 供给打标任务定义:有大量的商户和标签,需要将标签和商户进行关联,商户评论和团单等就是标签和商户连接的纽带。有基于统计的方法,如果一个标签出现在一个商户下出现一定比例后,认为是相关的,但是这个阈值是难以确定的,并且频率高也不一定是相关的。
- 解决方案:对于商户打标,数据主要是分为三个层面,商户、商户类目、用户评论。
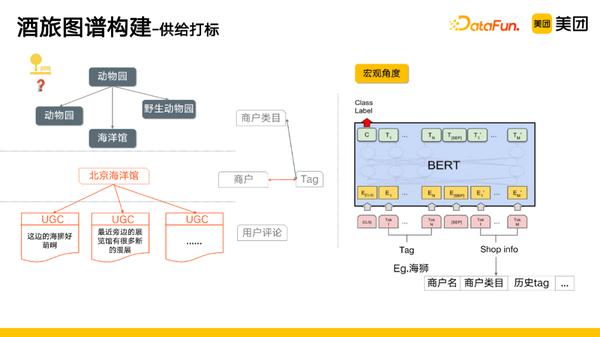

- 宏观角度,将商户和标签进行关联。
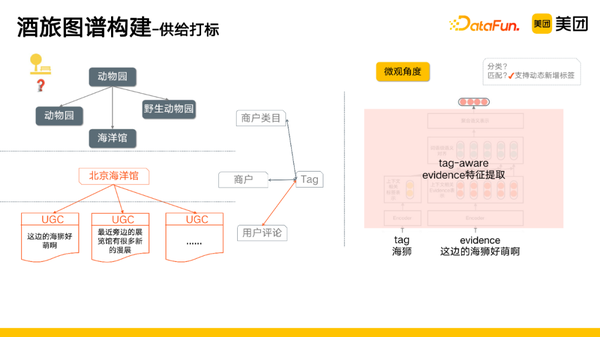

- 微观角度,商户下会包括评论信息,评论信息可以将标签和商户进行连接。
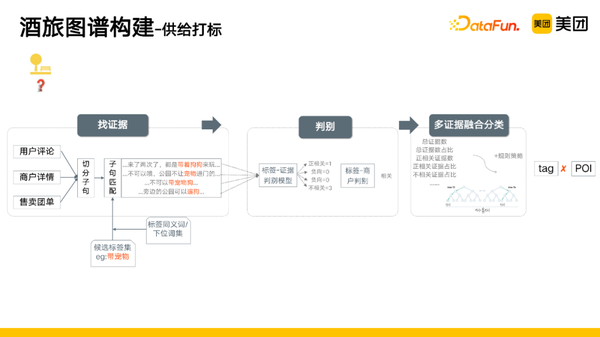

供给打标的整个流程如下:
- 找证据,从用户评论、商户详情、售卖团单等进行子句切分,子句匹配,这里将标签的同义词、下位词一起匹配,扩充召回。得到匹配标签对。
- 判别,对得到的匹配标签对进行判别,有标签-证据判别、标签-商户判别。
- 多证据融合分类,得到文本类特征和统计类特征后,再利用树模型进行分类。
--
03/酒旅图谱应用
1. 搜索


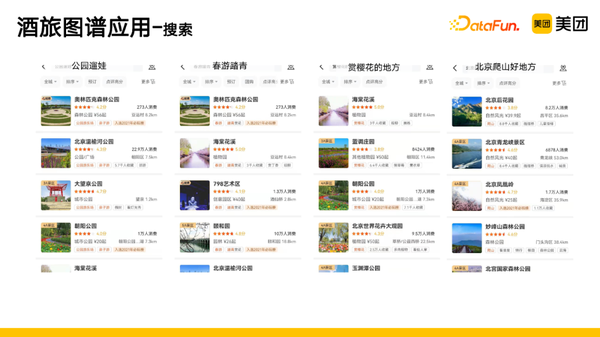

在搜索上,可以满足用户的复合标签需求,返回带有相关标签的结果。
2. 时效性标签展示策略
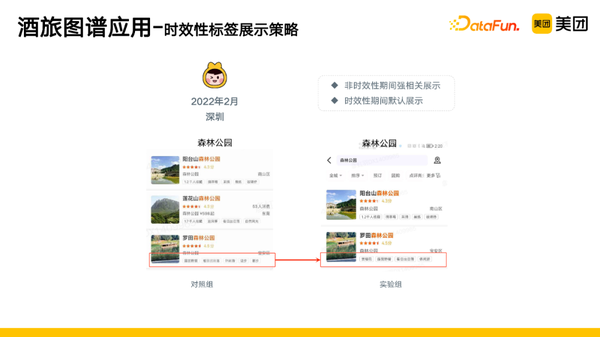

在非时效性期间内进行强相关展示,搜索和这个标签相关的query才进行展示;在时效性期间默认展示,即使没有搜索相关query,也进行展示。
3. 榜单
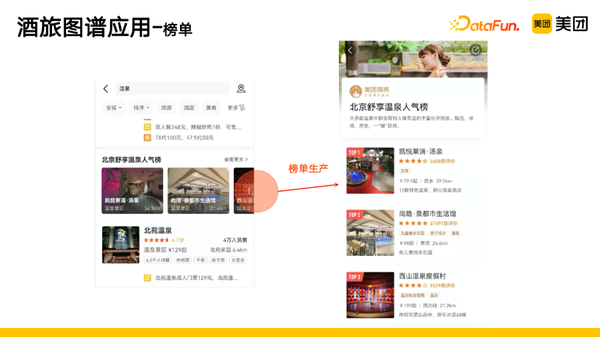

将生产的一些标签和生产的一些关系推送到榜单的生产上,像图中搜索温泉,会推送一个温泉的人气榜。
4. sug应用


原本,在搜索“北京爬山”,会展示“鸽子台登山步道”、“登山农家院”这种和场景需求相关度较低的结果。将泛场景的信号应用到sug后,召回会有较强的相关性,召回一些和爬山相关的公园、景区等。
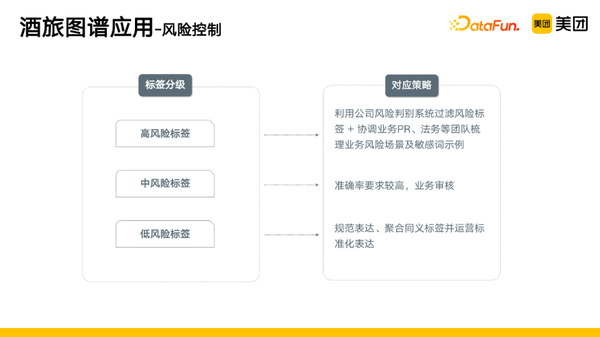
5. 风险控制


在具体应用的过程中,我们不仅要考虑知识图谱的挖掘,还要考虑知识图谱的风险问题。
- I类风险:标签名称本身有风险,如农村人、台独、情趣等。
- II类风险:标签名称本身无风险,与某些商家关联后有风险,如室内玩乐--> xxx遗址陈列馆,陪父母-->xxx烈士陵园。
还有一些应用问题。

- I类问题:标签名称不规范,如油菜花vs赏桃花、赏樱花。
- II类问题:相同语义标签冗余展示,如爬山、登山 --> 爬山,隔音好、房间安静 --> 隔音好。
针对上述问题,我们采取了一些策略,首先是标签分级,然后针对不同等级的标签制定不同的对应策略。
- 高风险标签,标签的名称比较敏感,容易引发社会的舆论或者是会带来误导的一些标签,如农村人。利用公司风险判别系统过滤风险标签+协调业务PR、法务等团队梳理业务风险场景及敏感词示例。
- 中风险标签,标签名称本身没有问题,标签的含义带有一些约定俗成的意思,如三山五岳。这些标签准确率要求较高,需要业务审核。
- 低风险标签,除上述标签外的一些主客观类的标签。这些标签需要规范表达、聚合同义标签并运营标准化表达。
--
04/总结与展望
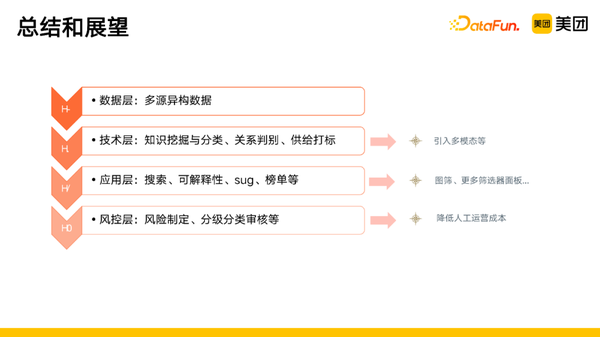

我们从四个方面对酒旅图谱进行了构建,首先是数据层,我们采用了多源异构数据;然后是技术层,通过知识挖掘与分类、关系判别、供给打标等技术图谱进行了构建;然后是应用层,我们的图谱可以应用到搜索、可解释性、sug、榜单等;最后是风控层,来屏蔽一些有风险的标签,然后对标签进行分类的审核。
未来的方向有,在技术层引入多模态特征,在应用层将图谱应用到图筛和更多筛选器面板上,在风控层,可以引入更多的算法能力,来降低我们的人工运营成本。
--
05/问答环节
Q1:如何判断一个图谱做的质量好坏,有没有相应的标准或是KPI?
A:从覆盖率的角度上评价,有节点的数量和关系的数量;从准确率的角度评价,有节点和节点之间关系的准确率,以及节点是不是一个合理的节点;从应用角度评价,通过在应用层对供给覆盖率、需求理解覆盖率进行评价。
Q2:目前企业已经做了很多标签,构建了自己的标签体系,如何使用知识图谱对现在的标签体系进行改造,是否具备改造的可能和意义?
A2:标签体系和业务是紧密相关的,在构建标签体系的时候,是掺杂了很多业务的知识,随着业务发展的过程中,考虑业务的需求看是不是需要改进标签体系。
Q3:召回是针对什么?
A3:在美团搜索中,用户搜索一个query,我们返回满足用户需求的供给。
Q4:不同来源的数据在图谱中是怎样融合的?
A4:首先是结构化数据,映射到图谱中就是供给的基本信息;然后半结构化的数据,我们去挖掘一些实体以及实体的关系,通过相关算法,挂到图谱的类目体系下;对于非结构化数据,通过一些知识挖掘的方式将想要的知识给挖掘出来。
Q5:标签是如何总结出来的?
A5:问题可以理解为,将什么样的片段定义为标签,需要结合不同业务场景。在我们的场景中,标签可能会有两个类型,一个类型是商户的基础信息,比如说他的一些门票信息,成人票和儿童票这种,另外一类就是和用户场景需求相关的泛需求的标签。都是要结合具体的业务场景去判断。
Q6:不用图数据库,用关系型数据库存储,对于上亿的关系,查询效率可以满足业务要求吗?
A6:其实我们并不是将所有的节点都应用到搜索上,因为这是一个非常大的量级,对于我们的索引有非常大的考验,我们只需要将一些高频的标签应用到线上就可以了。
Q7:知识图谱检索过程中,是否需要定义大量的 SQL 查询模板,进行模板匹配?
A7:在线上应用层面上,针对实时的 query,有一个候选的标签集,通过向量计算的方式将这个 query 和候选集合进行一个相似度计算,然后召回一些最相关的标签。
Q8:在构建图谱的过程中,有什么经验可以分享,能够保证图谱有比较好的扩展性。
A8:第一,我们需要定义清楚节点要覆盖什么样的知识,也就是节点的体系,像酒旅知识图谱需要有一些像榜单、作品、人物等和景点强相关的知识;第二,考虑体系下面节点的扩充,如果没有已经标注好的文本,我们可以依靠远程监督的方式去构造一些训练集,然后用训练集训练模型,再通过一些主动学习的方法不断为模型提供高质量数据,为模型提升效果;第三,考虑图谱的应用层面,如果图谱已经构建较完善了,我们不知道他的应用点在哪里的话,也是不太行的。所以一开始构建的时候就需要结合我们的应用点,对我们的图谱做一些定制化的迭代等等。
Q9:多模态知识图谱的价值是什么?
A9:举个例子,像创极速光轮,我们从文本角度很难去知道它是一个过山车,如果能结合图片信息,加入多模态特征,去训练模型,更好地提升识别能力。
今天的分享就到这里,谢谢大家。
分享嘉宾


彦虹羽|美团 算法开发
学历:哈尔滨工业大学(深圳)硕士
工作履历:2020年加入美团酒旅搜索组,主要负责的工作内容:美团酒旅图谱的构建及应用。
