当我们谈C++中的变量、指针和引用时,我们到底在谈什么?

问题
先看一段代码:
int a=1;
cout<<"普通变量:"<<"值:"<<a<<" 址:"<<&a<<endl;
return 0;
}
上述代码,首先定义了一个整型变量a,并赋值为1,然后打印出变量a的值和地址。程序的运行结果如下:
普通变量:值:1 址:0x6dfef8众所周知,变量a存放于主存中,当CPU执行到以a为操作数的指令时,指令的地址码字段即为a在主存中的地址,这被称为是直接寻址。根据上述运行结果,可以分析出变量a在主存中的布局情况,如下图所示:


从上图中,可以看到,变量a存放于主存中地址为0x6dfef8的存储单元中,值为1。那么,当变量的类型是指针类型时,它在内存中的布局是什么情形呢?再看一段代码:
int a=1;
cout<<"普通变量:"<<"值:"<<a<<" 址:"<<&a<<endl;
int *b=&a;
cout<<"指针变量:"<<"值:"<<b<<" 址:"<<&b<<endl;
return 0;
}
上述代码在之前的基础上,又定义了一个指针变量b,它指向变量a,然后打印出变量b的值和地址。程序的运行结果如下:
普通变量:值:1 址:0x6dfef8
指针变量:值:0x6dfef8 址:0x6dfef4可以看到,变量b的值为0x6dfef8,地址为0x6dfef4。据此绘制出此时的内存分布如下图所示:


我们发现,变量b的内容恰好是变量a的地址,因为b是指向a的指针。此外,变量b的地址比a小4,这说明局部变量表所对应的栈是向下增长的。注意到,0x6dfef8-0x6dfef4=4,也就是说,a和b的地址之差为4,而通常存储器是以字节作为最小的寻址单位,因此可以认为b占据4个字节。而b的值,也就是0x6dfef8却只占用3个字节,那剩下的字节是干什么了呢?这可能有两种原因,其一是,CPU对主存按照内存对齐的方式进行访问,从而用4个字节存储b;其二是,0x6dfef8不是物理地址,而是逻辑地址,最常见的一种逻辑地址方式是基址寻址,此时的逻辑地址等于相对于基址的偏移量。更重要的是,指针定义了“”运算符,在我们的例子中,在我们的例子中,b=a,从汇编语言的角度看,*运算就是间接寻址,也就是说,b保存着操作数地址的地址,在指令执行前,要将b的值取出来,再送入指令寄存器的地址码字段中。最后,我们再看一下引用变量的情况,代码、结果和内存布局分别如下所示:
int main(){
int a=1;
cout<<"普通变量:"<<"值:"<<a<<" 址:"<<&a<<endl;
int *b=&a;
cout<<"指针变量:"<<"值:"<<b<<" 址:"<<&b<<endl;
int &c=a;
cout<<"引用变量:"<<"值:"<<a<<" 址:"<<&c<<endl;
return 0;
}
普通变量:值:1 址:0x6dfef8
指针变量:值:0x6dfef8 址:0x6dfef4
引用变量:值:1 址:0x6dfef8
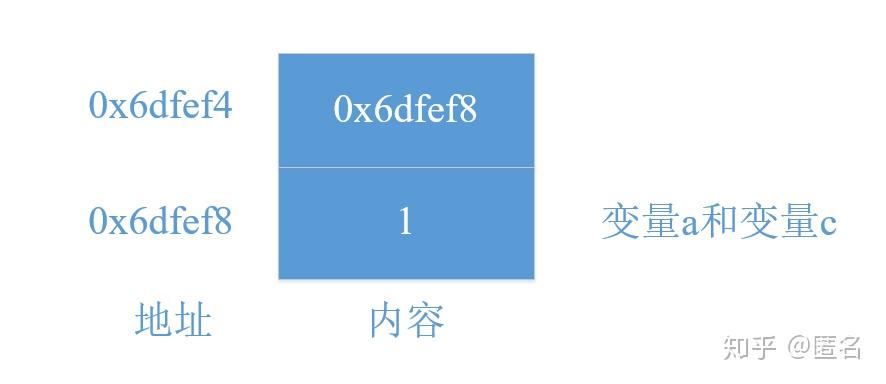

可以认为,变量a和变量c就是同一个变量,因为二者的值、址,以及在程序中的作用方式完全一致,因此在C++ Primer中说“引用变量就是变量的别名”。但不同之处在于,引用变量要有初始化过程。
总结
上述的分析相对细致,却十分啰嗦,看到C++中随处可见的变量时,是不可能想这么多的。这里做一下总结:变量对应着某个存储单元,具有地址和值。对普通变量的访问,访问的是它的值;而对指针变量的访问(*操作),访问的是它所指向的变量的值;引用变量就是变量别名。此外,我们说普通变量和指针作为函数参数时,是传值,而引用变量才是传址。所谓传值,是指改变形参变量的内容,而传址,是指改变形参变量的地址,也就是改变它所对应的存储单元。指针寻址方式,对于计算机实现来说很容易,但对于人理解却不太容易。这可能是Java中不采用指针的原因之一吧,但实际上Java中的引用就是C++中的指针,遗憾的是,Java中没有C++中的引用,在一些情况下会使得代码比较复杂。