
Stata: 协整还是伪回归?

作者:许梦洁 (编译) (知乎 | 简书 | 码云)
Stata连享会 「现场班专题课程-爬虫-文本分析-空间计量」
连享会 最新专题 直播
Source: Ashish Rajbhandari → Cointegration or spurious regression?
连享会-知乎推文列表
Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15 主讲:王存同 (中央财经大学);司继春(上海对外经贸大学) 课程主页:https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13 主讲:杨海生 (中山大学);范巧 (兰州大学) 课程主页:https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)
时间序列数据经常是不平稳的而且序列之间往往有一定程度上的联动关系。一组时间序列协整意味着这组序列内存在一个长期的均衡关系。如果这种长期的均衡关系不存在,则表面上的联动则是无意义的。
分析多个不平稳的时间序列是否协整可以帮助理解它们的长期表现。把30年的美国政府债券的利率看作是长期利率,把3个月的同种债券的利率看做是短期利率。根据相关理论,长期利率应该是短期利率的未来预期收益的平均值。这意味着这两个利率之间在一定时间段内不可能有太大的偏离。也就是说,如果这两个利率有协整关系,任何影响短期利率的因素也将带来长期利率的调整。这个见解在做一些政策和投资决策的时候非常有用。
在协整分析中,我们会将一个不平稳的序列对一系列其他不平稳序列进行回归。令人惊讶的是,在有限样本中,用不平稳序列对其他不平稳序列进行回归往往都能得到很显著的系数和很高的 R^2 。这种情况虽然看起来很像协整,但实际上往往是伪回归。
在这篇文章中,我会用模拟数据来分别展示在协整和伪回归下 OLS 估计量的渐近性质,然后使用 Engle and Granger(1987) 的方法来检验协整关系。
1. 协整
我们考虑两个一阶协整的两个变量 y_t 和 x_t ,这意味着它们各自是 I(1) ,也就是说它们各自可以通过一阶差分变成平稳序列。
如果 y_t 和 x_t 的线性组合是 I(0) ,这意味着 \alpha[y_t,x_t]'=e_t ,其中 \beta 是协整向量, e_t 是平稳的均衡误差项。一般来说,在多变量的协整中可能不止存在一个协整关系。然而,Engle–Granger 方法假设不管有多少个变量都只存在一个协整关系。
一个标准的假设是将协整向量的其中一个系数标准化为1来唯一地识别一组完全共线的协整关系。这种标准化的设定决定了哪些变量会出现在等式左边,而哪些变量会出现在等式右边,显然标准化系数的选择并不会产生实质性影响。以 \alpha=(1,-\beta) 为例,这意味如下的回归设定:
y_t=\beta x_t+e_t \qquad (1) \\
上面的等式描述了 y_t 和 x_t 之间的长期关系,这也被称为“静态”回归因为假设该等式中没有其他变量的动态变化或误差项的序列相关。 OLS 估计量为 \hat{\beta}=\frac{\sum_{i=1}^{T}{y_{t}x_{t}}}{\sum_{i=1}^{T}{x_{t}^{2}}} 。由于 y_t 和 x_t 都是 I(1) ,当 T\rightarrow \infty 时,分子和分母都会收敛于复杂的布朗运动函数。然而,无论 x_t 是否和 e_t 相关, \hat{\beta} 都会收敛于真实的 \beta 。实际上,这种情况下的估计量 \hat{\beta} 具有超一致性,这意味着该估计量会以比平稳序列回归下的 OLS 估计量更快的速度收敛于真实值。推断 \hat{\beta} 的过程并不是很直接,因为它的渐近分布并不是标准分布同时也依赖于常数项和趋势项是否已经给出。
2. 蒙特卡洛模拟
我通过重复1000次的蒙特卡洛模拟画出了 OLS 估计量 \hat{\beta} 在协整和伪回归下的经验分布。在伪回归下, \hat{\beta} 的经验分布即使在扩大样本后也不会收敛到真实值,这意味着 OLS 估计量在伪回归下不具有一致性。相对地,如果序列是协整的,我们可以看到 \hat{\beta} 的经验分布会收敛到其真实值。
2.1 伪回归的数据生成过程
我通过以下设定生成了伪回归的 y_t 和 x_t :
y_{ t }=0.7x_{ t }+e_{ t } \qquad \quad\\
x_{ t }=x_{ t-1 }+\nu _{ xt } \qquad (2) \\
e_{ t }=e_{ t-1 }+\nu _{ yt } \qquad \quad\\
其中 \nu_{xt} 和 \nu_{yt} ~ i.i.d. N(0,1) 。 x_t 和 e_t 是相互独立的随机游走过程。由于 y_t 和 x_t 的线性组合 y_t-0.7x_t=e_t 是 I(1) 过程,所以该回归是伪回归。
2.2 协整的数据生成过程
我通过以下设定生成了协整的 y_t 和 x_t :
y_{ t }=0.7x_{ t }+e_{ yt } \qquad \quad\\
x_{ t }=x_{ t-1 }+e_{ xt } \qquad (3)\\
其中 x_t 是唯一的 I(1) 过程。通过将误差项 e_{xt} 和 e_{yt} 设定为有 1 阶滞后的 VMA 过程,我允许存在同期相关和序列相关。VMA 过程由以下设定给出:
e_{ yt }=0.3\nu _{ yt-1 }+0.4\nu _{ xt-1 }+\nu _{ yt }\\
e_{ xt }=0.7\nu _{ yt-1 }+0.1\nu _{ xt-1 }+\nu _{ xt }\\
其中, \nu_{yt} 和 \nu_{xt} 由正态分布生成,二者均值都为 0,方差-协方差矩阵为
\Sigma = \begin{bmatrix} 1& 0.7 & \\ 0.7& 1.5 & \end{bmatrix}\\
下图画出了经验分布,蒙特卡洛模拟的代码在附录中提供。
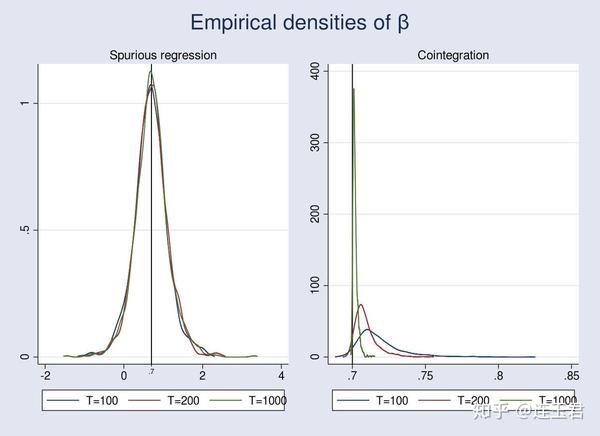

伪回归中的 OLS 估计量不具有一致性,因为即使把样本量从 100 扩大到 1000 后该估计量也不会收敛于其真实值 0.7。不仅如此,在有限样本中,伪回归的系数通常很显著并且有很高的 R^2 。事实上,Phillips(1986) 指出,当 T\rightarrow \infty 时,伪回归的 t 统计量和 F 统计量是发散的,因此在伪回归中以 t 统计量和 F 统计量为推断依据是不可信的。
在协整关系中,我人为地在误差项的生成过程中引入了序列相关,这导致在样本量为 100 时的结果有偏,而当样本量扩大到 200 时有所改善,当样本量扩大到1000 时有显著改善。由于协整关系中的 \hat{\beta} 仍然满足一致性,因此虽然此时 \hat{\beta} 的渐近分布不是标准分布,我们仍然可以用 \hat{\beta} 做统计推断。
连享会 最新专题 直播
2.3 协整关系的检验
我们在前面的部分我们看到了协整关系下 OLS 估计量具有一致性,甚至在误差项序列相关时仍然满足。为了检验协整关系,我们可以首先对模型 (1) 进行 OLS 估计得到残差项,然后检验该残差项是否存在单位根。如果序列是协整的,则误差项一定是平稳的,这种方法叫做 Engle–Granger 两步法。 ADF(Augmented Dickey–Fuller) 检验和 PP(Phillips–Perron) 检验可以用于第二步检验单位根的操作,见 「连享会推文 - Stata: 单位根检验就这么轻松」。
协整检验的原假设和备择假设分别为:
H_0: e_t=I(1) \qquad H_1:e_t=I(0)\\
原假设意味着 e_t 是非平稳的,也即是 y_t 和 x_t 之间不存在协整关系。备择假设则说明 e_t 是平稳的,也意味着协整关系的存在。 如果真实的协整向量 \alpha 已知,基于估计残差的 ADF 检验在原假设下不会服从标准的 DF 分布(Phillips and Ouliaris, 1990)。此外, Hansen(1992) 认为 ADF 统计量的分布也依赖于 y_t 和 x_t 中的常数和线性趋势项。 Hamilton(1994) 则提供了在这种情况下进行统计推断的临界值。
3. 例子
这里有两个之前进行蒙特卡洛模拟时生成的数据集。spurious.dta包含根据方程组 (2) 生成的两个用于伪回归的变量 x_t 和 y_t 。coint.dta 则包含根据方程组 (3) 生成的两个具有协整关系的变量 x_t 和 y_t 。
首先,我对数据集 spurious.dta 中的协整关系进行检验。
. use spurious, clear
. reg y x, nocons
Source | SS df MS Number of obs = 100
-------------+---------------------------------- F(1, 99) = 6.20
Model | 63.4507871 1 63.4507871 Prob > F = 0.0144
Residual | 1013.32308 99 10.2355867 R-squared = 0.0589
-------------+---------------------------------- Adj R-squared = 0.0494
Total | 1076.77387 100 10.7677387 Root MSE = 3.1993
------------------------------------------------------------------------------
y | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
x | -.1257176 .0504933 -2.49 0.014 -.2259073 -.0255279
------------------------------------------------------------------------------
x 的系数是负的且是显著的。我使用带 resid 选项的 predict 命令来获得残差,用 dfuller 命令来做ADF检验。我使用 noconstant 选项使回归中不包含残差项,用 lags(2) 选项来对序列相关做出调整。dfuller 命令中的 noconstant 选项意味着拟合随机游走模型。
. predict spurious_resd, resid
. dfuller spurious_resd, nocons lags(2)
Augmented Dickey-Fuller test for unit root Number of obs = 97
---------- Interpolated Dickey-Fuller ---------
Test 1% Critical 5% Critical 10% Critical
Statistic Value Value Value
------------------------------------------------------------------------------
Z(t) -1.599 -2.601 -1.950 -1.610
正如之前提到的,DF 分布的临界值在这种情况下并不适用。根据 Hamilton(1994) ,其 5% 临界值应为 -2.76。该检验统计量为 -1.60 意味着不能拒绝不存在协整关系的原假设。 我对数据集 coint.dta 也做了同样的检验:
. use coint, clear
. reg y x, nocons
Source | SS df MS Number of obs = 100
-------------+---------------------------------- F(1, 99) = 3148.28
Model | 4411.48377 1 4411.48377 Prob > F = 0.0000
Residual | 138.72255 99 1.40123788 R-squared = 0.9695
-------------+---------------------------------- Adj R-squared = 0.9692
Total | 4550.20632 100 45.5020632 Root MSE = 1.1837
------------------------------------------------------------------------------
y | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
x | .7335899 .0130743 56.11 0.000 .7076477 .7595321
------------------------------------------------------------------------------
. predict coint_resd, resid
. dfuller coint_resd, nocons lags(2)
Augmented Dickey-Fuller test for unit root Number of obs = 97
---------- Interpolated Dickey-Fuller ---------
Test 1% Critical 5% Critical 10% Critical
Statistic Value Value Value
------------------------------------------------------------------------------
Z(t) -5.955 -2.601 -1.950 -1.610
该DF检验统计量的值为 -5.95,显然大于临界值 -2.76,因此在 5% 水平下拒绝不存在协整关系的原假设。
3. 结论
在这篇文章中,我使用蒙特卡洛模拟展示了 OLS 估计量在协整关系下的一致性。同时,我还使用 Engle–Granger 两步法检验了模拟数据中的协整关系。
参考文献
- Engle, R. F., and C. W. J. Granger. 1987. Co-integration and error correction: Representation, estimation, and testing. Econometrica 55: 251–276.
- Hamilton, J. D. 1994. Time Series Analysis. Princeton: Princeton University Press.
- Hansen, B. E. 1992. Effcient estimation and testing of cointegrating vectors in the presence of deterministic trends. Journal of Econometrics 53: 87–121.
- Phillips, P. C. B. 1986. Understanding spurious regressions in econometrics. Journal of Econometrics 33: 311–340.
- Phillips, P. C. B., and S. Ouliaris. 1990. Asymptotic properties of residual based tests for cointegration. Econometrica 58: 165–193.
附录
伪回归代码
cscript
set seed 2016
local MC = 1000
quietly postfile spurious beta_t100 using t100, replace
forvalues i=1/`MC' {
quietly {
drop _all
set obs 100
gen time = _n
tsset time
gen nu_y = rnormal(0,0.7)
gen nu_x = rnormal(0,1.5)
gen err_y = nu_y in 1
gen err_x = nu_x in 1
replace err_y = l.err_y + nu_y in 2/l
replace err_x = l.err_x + nu_x in 2/l
gen y = err_y in 1
gen x = err_x
replace y = 0.7*x + err_y in 2/l
if (`i'==1) save spurious, replace
qui reg y x, nocons
}
post spurious (_b[x])
}
postclose spurious
协整代码
cscript
set seed 2016
local MC = 1000
quietly postfile coint beta_t100 using t100, replace
forvalues i=1/`MC' {
quietly {
drop _all
set obs 100
gen time = _n
tsset time
matrix V = (1,0.7\0.7,1.5)
drawnorm nu_y nu_x, cov(V)
gen err_y = nu_y in 1
gen err_x = nu_x in 1
replace err_y = 0.3*l.nu_y + 0.4*l.nu_x ///
+ nu_y in 2/l
replace err_x = 0.7*l.nu_y + 0.1*l.nu_x ///
+ nu_x in 2/l
gen x = err_x in 1
replace x = l.x + err_x in 2/l
gen y = 0.7*x + err_y
if (`i'==1) save coint, replace
qui reg y x, nocons
}
post coint (_b[x])
}
postclose coint
画图代码
/*Spurious regression*/
use t100, clear
quietly merge 1:1 _n using t200
drop _merge
quietly merge 1:1 _n using t1000
drop _merge
kdensity beta_t100, n(1000) generate(x_100 f_100) ///
kernel(gaussian) nograph
label variable f_100 "T=100"
kdensity beta_t200, n(1000) generate(x_200 f_200) ///
kernel(gaussian) nograph
label variable f_200 "T=200"
kdensity beta_t1000, n(1000) generate(x_1000 f_1000) ///
kernel(gaussian) nograph
label variable f_1000 "T=1000"
graph twoway (line f_100 x_100) (line f_200 x_200) ///
(line f_1000 x_1000), legend(rows(1)) ///
subtitle("Spurious regression") ///
saving(spurious, replace) xmlabel(0.7) ///
xline(0.7, lcolor(black)) nodraw
/*Cointegration*/
use t100, clear
quietly merge 1:1 _n using t200
drop _merge
quietly merge 1:1 _n using t1000
drop _merge
kdensity beta_t100, n(1000) generate(x_100 f_100) ///
kernel(gaussian) nograph
label variable f_100 "T=100"
kdensity beta_t200, n(1000) generate(x_200 f_200) ///
kernel(gaussian) nograph
label variable f_200 "T=200"
kdensity beta_t1000, n(1000) generate(x_1000 f_1000) ///
kernel(gaussian) nograph
label variable f_1000 "T=1000"
graph twoway (line f_100 x_100) (line f_200 x_200) ///
(line f_1000 x_1000), legend(rows(1)) ///
subtitle("Cointegration") ///
saving(cointegration, replace) ///
xline(0.7, lcolor(black)) nodraw
graph combine spurious.gph cointegration.gph, ///
<section id="nice" data-tool="mdnice编辑器" data-website="https://www.mdnice.com" style="font-size: 16px; color: black; padding: 10px; line-height: 1.6; word-spacing: 0px; letter-spacing: 0px; word-break: break-word; word-wrap: break-word; text-align: left; font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, 'PingFang SC', Cambria, Cochin, Georgia, Times, 'Times New Roman', serif;"><p data-tool="mdnice编辑器" style="font-size: 16px; padding-top: 8px; padding-bottom: 8px; margin: 0; line-height: 26px; color: black;"><a href="https://www.lianxh.cn" style="text-decoration: none; color: #1e6bb8; word-wrap: break-word; font-weight: bold; border-bottom: 1px solid #1e6bb8;">连享会</a> <a href="https://gitee.com/arlionn/Course/blob/master/README.md" style="text-decoration: none; color: #1e6bb8; word-wrap: break-word; font-weight: bold; border-bottom: 1px solid #1e6bb8;">最新专题</a> <a href="https://gitee.com/arlionn/Live" style="text-decoration: none; color: #1e6bb8; word-wrap: break-word; font-weight: bold; border-bottom: 1px solid #1e6bb8;">直播</a></p>
</section>相关课程
连享会-直播课 上线了!
http://lianxh.duanshu.com
免费公开课:
- 直击面板数据模型 - 连玉君,时长:1 小时 40 分钟
- Stata 33 讲 - 连玉君, 每讲 15 分钟.
- 部分直播课 课程资料下载 (PPT,dofiles 等)

课程一览
支持回看,所有课程可以随时购买观看。
连享会 - 文本分析与爬虫 - 专题视频
主讲嘉宾:司继春 || 游万海


连享会 - 效率分析专题
已上线:可随时购买学习+全套课件,课程主页 已经放置板书和 FAQs
主讲嘉宾:连玉君 | 鲁晓东 | 张宁
课程主页,微信版 https://gitee.com/arlionn/TE


Note: 部分课程的资料,PPT 等可以前往 连享会-直播课 主页查看,下载。

关于我们
- Stata 连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。直播间 有很多视频课程,可以随时观看。
- 连享会-主页 和 知乎专栏,300+ 推文,实证分析不再抓狂。
- 公众号推文分类:计量专题 | 分类推文 | 资源工具。推文分成 内生性 | 空间计量 | 时序面板 | 结果输出 | 交乘调节 五类,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。

连享会小程序:扫一扫,看推文,看视频……

扫码加入连享会微信群,提问交流更方便

