双向LSTM+Attention文本分类模型(附pytorch代码)


风控算法方向,可内推
深度学习里的Attention模型其实模拟的是人脑的注意力模型。举个例子来说,当我们阅读一段话时,虽然我们可以看到整句话,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很少的几个词,也就是说这个时候人脑对整句话的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。具体的可以去阅读Attention模型的论文。
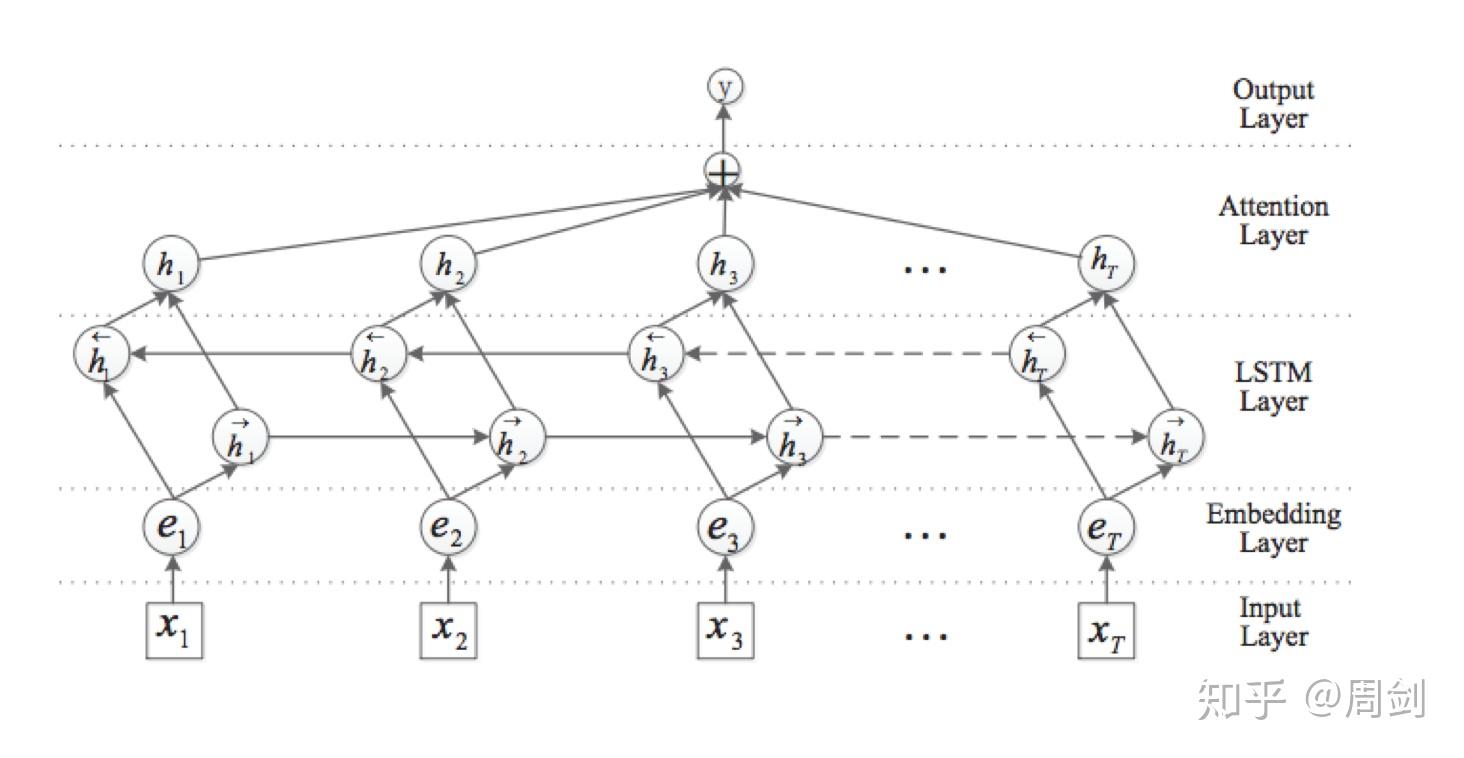
使用Attention模型进行文本分类,可以借助传统的LSTM。双向LSTM+Attention模型如下图:

我将具体的代码放在了我的github,欢迎大家下载:
代码中的训练和测试数据一共有6000多条,有6个labels。使用随机的初始词向量,最终的准确率在90%左右。
本文主要说明一下model.py中的代码,如下:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn import functional as F
import numpy as np
import const
class bilstm_attn(torch.nn.Module):
def __init__(self, batch_size, output_size, hidden_size, vocab_size, embed_dim, bidirectional, dropout, use_cuda, attention_size, sequence_length):
super(bilstm_attn, self).__init__()
self.batch_size = batch_size
self.output_size = output_size
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.embed_dim = embed_dim
self.bidirectional = bidirectional
self.dropout = dropout
self.use_cuda = use_cuda
self.sequence_length = sequence_length
self.lookup_table = nn.Embedding(self.vocab_size, self.embed_dim, padding_idx=const.PAD)
self.lookup_table.weight.data.uniform_(-1., 1.)
self.layer_size = 1
self.lstm = nn.LSTM(self.embed_dim,
self.hidden_size,
self.layer_size,
dropout=self.dropout,
bidirectional=self.bidirectional)
if self.bidirectional:
self.layer_size = self.layer_size * 2
else:
self.layer_size = self.layer_size
self.attention_size = attention_size
if self.use_cuda:
self.w_omega = Variable(torch.zeros(self.hidden_size * self.layer_size, self.attention_size).cuda())
self.u_omega = Variable(torch.zeros(self.attention_size).cuda())
else:
self.w_omega = Variable(torch.zeros(self.hidden_size * self.layer_size, self.attention_size))
self.u_omega = Variable(torch.zeros(self.attention_size))
self.label = nn.Linear(hidden_size * self.layer_size, output_size)
# self.attn_fc_layer = nn.Linear()
def attention_net(self, lstm_output):
#print(lstm_output.size()) = (squence_length, batch_size, hidden_size*layer_size)
output_reshape = torch.Tensor.reshape(lstm_output, [-1, self.hidden_size*self.layer_size])
#print(output_reshape.size()) = (squence_length * batch_size, hidden_size*layer_size)
attn_tanh = torch.tanh(torch.mm(output_reshape, self.w_omega))
#print(attn_tanh.size()) = (squence_length * batch_size, attention_size)
attn_hidden_layer = torch.mm(attn_tanh, torch.Tensor.reshape(self.u_omega, [-1, 1]))
#print(attn_hidden_layer.size()) = (squence_length * batch_size, 1)
exps = torch.Tensor.reshape(torch.exp(attn_hidden_layer), [-1, self.sequence_length])
#print(exps.size()) = (batch_size, squence_length)
alphas = exps / torch.Tensor.reshape(torch.sum(exps, 1), [-1, 1])
#print(alphas.size()) = (batch_size, squence_length)
alphas_reshape = torch.Tensor.reshape(alphas, [-1, self.sequence_length, 1])
#print(alphas_reshape.size()) = (batch_size, squence_length, 1)
state = lstm_output.permute(1, 0, 2)
#print(state.size()) = (batch_size, squence_length, hidden_size*layer_size)
attn_output = torch.sum(state * alphas_reshape, 1)
#print(attn_output.size()) = (batch_size, hidden_size*layer_size)
return attn_output
def forward(self, input_sentences, batch_size=None):
input = self.lookup_table(input_sentences)
input = input.permute(1, 0, 2)
if self.use_cuda:
h_0 = Variable(torch.zeros(self.layer_size, self.batch_size, self.hidden_size).cuda())
c_0 = Variable(torch.zeros(self.layer_size, self.batch_size, self.hidden_size).cuda())
else:
h_0 = Variable(torch.zeros(self.layer_size, self.batch_size, self.hidden_size))
c_0 = Variable(torch.zeros(self.layer_size, self.batch_size, self.hidden_size))
lstm_output, (final_hidden_state, final_cell_state) = self.lstm(input, (h_0, c_0))
attn_output = self.attention_net(lstm_output)
logits = self.label(attn_output)
return logits可以看到在代码中主要是由attention_net函数进行构建注意力模型。
注意力模型的公式如下:
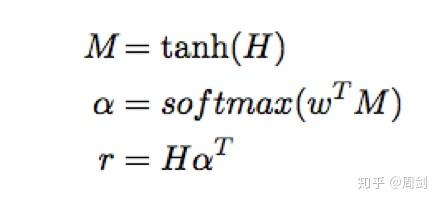
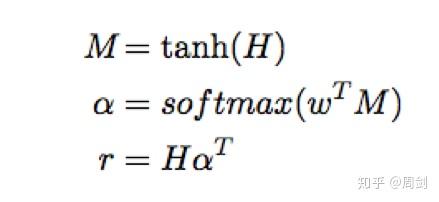
代码主要就是根据这三个公式写的。其中需要注意的是每次计算后tensor的size(在程序中我已经全部标明。)使用reshape函数,是为了更加直观地看出当前tensor的size。
第二个公式中的softmax,很多人直接调用torch中的sotfmax函数,我的代码中为了更加直观,没有调用softmax函数,全是手写的。
发布于 2019-04-15 16:25