
基于BERT的KBQA探索

引言
了解知识图谱的基本概念,也做过一些demo的实践,毕竟是做问答方向的,所以就比较关注基于知识图谱的问答。其实构建知识图谱的核心在于命名实体识别和关系抽取,围绕这两个方面也有很多细致的工作,比如如何解决实体的歧义,进行实体消歧;如何进行多关系的抽取等。从最近各大公司举行的比赛,我们也可以看出来,今年的主要工作就在这上面,这也是技术落地的一个重要标志。最近也在捣鼓BERT,想着就将基于KB的QA流程撸一遍,于是就有了这个demo。
项目地址:
转载请注明出处:QA Weekly
数据集介绍[1]
NLPCC全称自然语言处理与中文计算会议(The Conference on Natural Language Processing and Chinese Computing),它是由中国计算机学会(CCF)主办的 CCF 中文信息技术专业委员会年度学术会议,专注于自然语言处理及中文计算领域的学术和应用创新。
此次使用的数据集来自NLPCC ICCPOL 2016 KBQA 任务集,其包含 14 609 个问答对的训练集和包含 9 870 个问答对的测试集。 并提供一个知识库,包含 6 502 738 个实体、 587 875 个属性以及 43 063 796 个 三元组。知识库文件中每行存储一个事实( fact) ,即三元组 ( 实体、属性、属性值) 。各文件统计如下:
训练集:14609
开发集:9870
知识库:43063796知识库样例如下所示:
"希望之星"英语风采大赛|||中文名|||“希望之星”英语风采大赛
"希望之星"英语风采大赛|||主办方|||中央电视台科教节目中心
"希望之星"英语风采大赛|||别名|||"希望之星"英语风采大赛
"希望之星"英语风采大赛|||外文名|||Star of Outlook English Talent Competition
"希望之星"英语风采大赛|||开始时间|||1998
"希望之星"英语风采大赛|||比赛形式|||全国选拔
"希望之星"英语风采大赛|||节目类型|||英语比赛原数据中本只有问答对(question-answer),并无标注三元组(triple),本人所用问答对数据来自该比赛第一名的预处理https://github.com/huangxiangzhou/NLPCC2016KBQA。构造Triple的方法为从知识库中反向查找答案,根据问题过滤实体,最终筛选得到,也会存在少量噪音数据。该Triple之后用于构建实体识别和属性选择等任务的数据集。
问答对样例如下所示:
<question id=1> 《机械设计基础》这本书的作者是谁?
<triple id=1> 机械设计基础 ||| 作者 ||| 杨可桢,程光蕴,李仲生
<answer id=1> 杨可桢,程光蕴,李仲生
==================================================
<question id=2> 《高等数学》是哪个出版社出版的?
<triple id=2> 高等数学 ||| 出版社 ||| 武汉大学出版社
<answer id=2> 武汉大学出版社
==================================================
<question id=3> 《线性代数》这本书的出版时间是什么?
<triple id=3> 线性代数 ||| 出版时间 ||| 2013-12-30
<answer id=3> 2013-12-30
==================================================技术方案[2]
基于知识图谱的自动问答拆分为2 个主要步骤:命名实体识别步骤和属性映射步骤。其中,实体识别步骤的目的是找到问句中询问的实体名称,而属性映射步骤的目的在于找到问句中询问的相关属性。
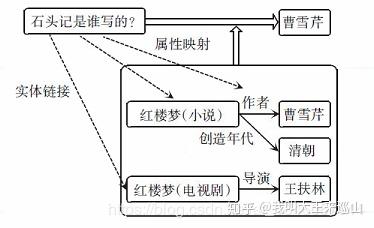
- 命名实体识别步骤,采用BERT+BiLSTM+CRF方法(另外加上一些规则映射,可以提高覆盖度)
- 属性映射步骤,转换成文本相似度问题,采用BERT作二分类训练模型
技术细节
- 命名实体识别
构造NER的数据集,需要根据三元组-Enitity 反向标注问题,给数据集中的Question 打标签。我们这里采用BIO的标注方式,因为识别人名,地名,机构名的任务不是主要的,我们只要识别出实体就可以了,因此,我们用B-LOC, I-LOC代替其他的标注类型。
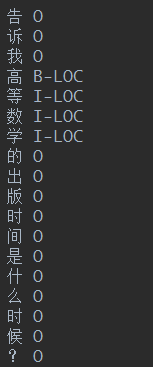
- 属性映射
构造测试集的整体关系集合,提取+去重,获得 4373 个关系 RelationList;
一个 sample 由“问题+关系+Label”构成,原始数据中的关系值置为 1;
从 RelationList 中随机抽取五个属性作为 Negative Samples;


- 模型总体架构
1、 实体检索:输入问题,ner得出实体集合,在数据库中检索出与输入实体相关的所有三元组
2、 属性映射:bert分类/文本相似度
+ 非语义匹配:如果所得三元组的关系(attribute)属性是输入问题字符串的子集(相当于字符串匹配),将所得三元组的答案(answer)属性与正确答案匹配,correct +1
+ 语义匹配:利用bert计算输入问题(input question)与所得三元组的关系(attribute)属性的相似度,将最相似的三元组的答案作为答案,并与正确的答案进行匹配,correct +1
目前这2个是一起做的,更注重的是测试性能,所以并没有像Retrieval QA那样做召回+排序,其实修改一下很简单,也就那回事。
总结
- 目前不足
- 在命名实体识别的时候,进行eval,最后的结果是nan,如下:
INFO:tensorflow:evaluation_loop marked as finished
INFO:tensorflow:***** Eval results *****
INFO:tensorflow: eval_f = nan
INFO:tensorflow: eval_precision = nan
INFO:tensorflow: eval_recall = nan
INFO:tensorflow: global_step = 1当然,predict是没有什么问题的。
- 反思
- 其实用question和attribute进行一个相似度计算做排序是有缺陷的,毕竟question的句子明显更长,语义明显比attribute更丰富,单拿attribute进行匹配有种断章取义的感觉,所以不提倡,但是也适用。
- 在用BERT online做命名实体识别的时候,速度有点慢,如何提高线上速度是个问题。


目前bert只跑了一个epoch,如果多跑几个epoch,效果会更好!
3. 目前的测试效果还行,多训练几轮效果更好.


Results:
total: 9870, recall: 9088, correct:7698,
accuracy: 84.70510563380282%, ambiguity (属性匹配正确但是答案不正确):681
- TO DO
- 完成KB_QA的online模式
- 完成排序+召回模式
Reference:
暂时就想到这些,后续如果被苹果砸了一下脑袋就更新一下,最后,嗯,如果觉得对您有帮助就点个赞鼓励一下吧!
转载请注明出处:QA答案选择-Read&Share
