
挖掘商品关联性(2): FP-growth算法

初学者机器学习资料分享Q群(718566626)
1. 背景
在前面我们介绍了一种简单的挖掘商品关联性算法Apriori算法。今天要介绍的是更高效的FP-growth算法(FP指的是Frequent Pattern),它可以用到搜索词提醒,常用词,挖掘强关联性商品,商品推荐等领域上。挖掘商品关联系或者词语之间的关联性,需要做的事是构造各种商品组合然后分析出这种组合是否是高频率出现。Apriori算法每产生一种组合都要遍历一次数据库来判断当前组合是否是高频记录(如果你对这句话不理解建议看下这篇文章:易懂机器学习Apriori算法商品关联性分析)。这个在大量数据面前是很耗时间。。
2. FP-growth执行过程
初衷:现在我们需要做的事是构造各种商品组合然后分析出这种组合是否是高频率出现。由于Apriori算法每次构造出一种组合都要遍历一遍数据集来统计当前这种组合出现次数这个耗费时间过大。那我们能不能把数据集压缩呢?假设是账单数据集。那么肯定会有很多账单会有大量公共商品组合。如果我们把这些公共商品作为前缀,那么就能压缩数据集。压缩数据集的好处就是可以减少我们统计某种组合出现次数所花费的时间。FP-growth算法就是这么做的,它数据构造成一颗树。相同商品在上层节点,并且每个节点记录了当前节点重复利用次数,以方便统计出现频率。
还是拿这个举例子:
{啤酒 鸡蛋 尿布 西红柿} {香烟 尿布 鸡蛋 啤酒 } {土豆 西红柿 洋葱 醋 鸡蛋}
先将它们编号:[1]啤酒 [2]鸡蛋 [3]尿布 [4]西红柿 [5]香烟 [6]土豆 [7]洋葱 [8]醋
上面这个数据集用编号表示就是
[ [1, 2, 3, 4], [5, 3, 2, 1], [6,4,7,8, 2] ]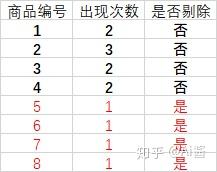
- 从这一步开始与Apriori算法不一样了。根据频率将每条账单内的商品按频率排序(并且剔除低频率商品)。
[ [2,1, 3,4], [2, 1, 3], [2,4] ]3. FP树如何构造
- 根据上面那个排序好并且筛选过的逐个账单构造一棵树。节点格式:{物品编号}-节点重复经过次数
加入第一个账单
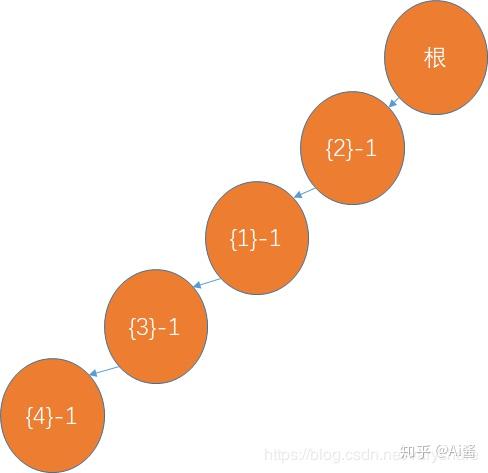

加入第二个账单:(与第一个账单前缀重合,所以重复利用节点,相关节点利用次数+1)


加入第3个账单(商品{2}是重合的前缀,商品{4}需要重新开一个节点):
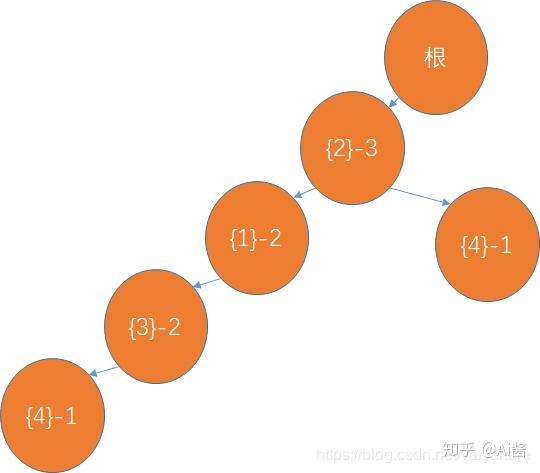

FP树有什么用(计算某种组合出现的次数不用重复查账单,只需要根据FP树来计算)
比如我有一个商品组合{2,3,1}我想看看它的出现频率。此时我完全不用从账单里面找哪些账单包含{2,3,1}这三个物品。先对这个组合按照物品出现频率排序即排序为{2,1,3}。然后我只需要之间看树上的相应节点即可。{2}->{1}->{3}这条路径重复利用了2次(第3个节点重复利用次数是2所以这条路径重复利用次数是2)。证明{2,1,3}这个组合出现2次。
那么问题来了。{4}这个节点有两个,我们怎么方便的找到以{4}开头的商品组合呢?用一个表来存储含有某个物品的节点的编号。假设我们对各个节点进行了编号(n1,n2,n3…)
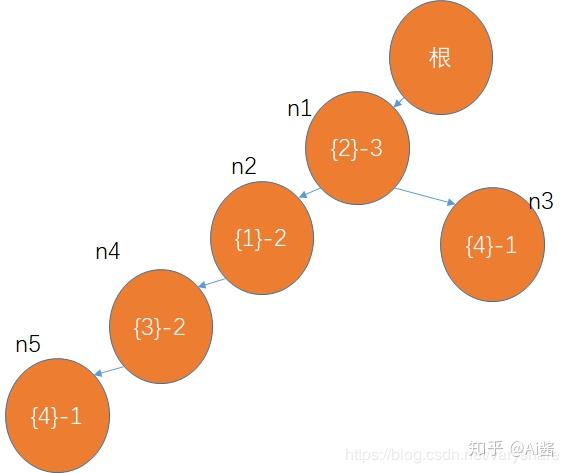

然后我们构造的表是。如果我们要找{4}开头的组合的频率那么只用从n5和n3这两个节点开始往下找:
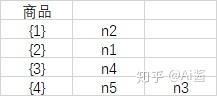
Python代码实现构造FP树和上面那个表(建议先看原理后自己实现,而不是先看代码)
我的代码思路是,用字典来构造树,构造树的方式是采用递归的方式来构造。
每个节点包含两个属性:child(它的孩子节点)和repeats(当前节点重复利用次数)。你知道思路即可,然后按照自己学习到的思路实现。
学习算法建议最好不要逐行敲书上或者博客的代码,一定要自己把原理悟出来算法每一步做什么后按自己的思路去编程实现(这样学得最快)。
直接敲书上的代码只适合学应用型编程(做网页APP后台等)而不是算法型(数据结构机器学习等)编程。算法型编程往往难点在算法逻辑上,而不是程序设计。最后,你的赞是我分享的动力。
# -*- coding: utf-8 -*-
"""
@author: @Ai酱
"""
import numpy as np
data = [
[1, 2, 3, 4],
[5, 3, 2, 1],
[6,4,7,8, 2]
]
# 1. 设定大于等于多少才是高频率
high_freq = 2
# 2. 统计各商品出现次数
max_goods_id = 8
goods_num = {}
for i in range(max_goods_id):
goods_id = i+1
for item in data:
if goods_id in item:
if goods_id in goods_num.keys():
goods_num[goods_id] +=1
else:
goods_num[goods_id] =1
pass
pass
pass
# 6. 删除账单中低频商品,并且按商品频率排序
for i in range(len(data)):
# 删除低频(<high_freq)的商品
tmp = data[i].copy()
for goods_id in tmp:
if goods_num[goods_id]<high_freq:
data[i].remove(goods_id)
# 按频率从高到低
data[i] = sorted(data[i])
data[i] = sorted(data[i],key=lambda x: goods_num[x], reverse=True)
# 7. 构造FP树
def addNode(root, goods_list,table):
if len(goods_list)==0:
return
# 将第一商品加入到树中
# 如果,当前商品已经在孩子节点中那么只需要将孩子节点重复次数+1
# 否则,用当前这个商品id来创建孩子节点,设置重复次数为1
if goods_list[0] in root['child']:
root['child'][goods_list[0]]['repeats']+=1
else:
root['child'][goods_list[0]]={'child':{}}
root['child'][goods_list[0]]['repeats']=1
# 当前这种商品增加了那新的节点记录到表里面方便根据前缀查树
table[goods_list[0]].append(root['child'][goods_list[0]])
# 递归的添加下一个商品
addNode(root['child'][goods_list[0]],goods_list[1:len(goods_list)],table)
pass
fptree = {'child':{}}
table = {i+1:[] for i in range(max_goods_id)}
for tmp_goods_list in data:
addNode(fptree,tmp_goods_list,table)
print(fptree)
'''
输出结果:
{
'child':{
2:{
'child':{
1:{
'child':{
3:{
'child':{
4:{
'child':{
},
'repeats':1
}
},
'repeats':2
}
},
'repeats':2
},
4:{
'child':{
},
'repeats':1
}
},
'repeats':3
}
}
}
'''相关文章:
Ai酱:机器学习算法之k-means(k均值)Python代码实现
Ai酱:[易懂机器学习]KNN,k-Nearest Neighbor (k近邻算法)[分类算法]
Ai酱:[易懂]如何理解论文中的那些评估方法性能指标概念名词{召回率 ROC AUC 交叉验证}
Ai酱:{高中生能看懂的}再见香农,决策树的本质是什么,ID3决策树Python实实现逻辑异或功能
本文首发于:挖掘商品关联性(2): FP-growth算法
