
在集群上训练一个机器学习模型(以lightGBM为例)


看过并按照我的上一篇文章
的说明做的话,现在你应该已经有一个可以运行的集群了,这一次我们尝试探索如何在集群上进行一些机器学习的流程。
机器准备:一个可运行集群
系统准备:ubuntu 16.04
软件准备:spark-2.4.0-bin-hadoop2.7,hadoop 2.8.5,mmlspark 0.17, python 3.6
MMLSpark
微软开发了MMLSpark,为Apache Spark提供了一些深入的学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像预测和分析模型和文本数据集。
微软针对 Spark 生态系统,做了以下三个主要的贡献:
(1)将机器学习组件 CNTK、LightGBM 和 Spark 统一;
(2)集成了 Azure 云端的 Cognitive Services 和实现了 Spark 的 HTTP 服务;
(3)部署所有的 Spark 计算,作为一种分布式的 web 服务。
更详细的介绍请参考官网
在集群上运行代码
有三种方法可以在集群上运行python代码:
- 使用pyspark
- 使用spark-submit
第一种方法代码运行在可交互的console上,可用于调试和理解集群运行方法;第二种方法无法交互,提交任务直接执行。因为pyspark和spark-submit的参数相同,这里我们只介绍pyspark。要运行spark-submit时只要把对应参数复制过去,再指定运行文件即可。
启动pyspark
先启动你的hadoop和spark进程。如果你已经正确配置pyspark,你应该可以直接运行pyspark命令
pyspark --help如果系统没有找到该命令,在环境变量里加入$SPARK_HOME/bin,具体方法不再详述。
pyspark有很多可选参数,以下是几个比较重要的参数:
--deploy-mode 部署模式,包括本地模式“local”,客户端模式“client”和集群模式“cluster”。这里我们默认用client
--master MASTER_URL 集群的master url,设定后任务就会提交到指定的集群运行,一般设置好的集群url都是spark://master:7077
--packages 加载外部包,pyspark会在启动时自动下载包文件,这样启动后才可以导入相应包。这里我们用的时mmlspark的0.12版本。
--num-executors 该参数用于设置Spark作业总共要用多少个Executor进程来执行。根据集群情况尽可能的取大一点的数值
--total-executor-cores Spark作业一共会用到的Executor的总核数
--driver-cores 递交任务的Driver使用的核数,一般不用取太大
--driver-memory 该参数用于设置Driver进程的内存。Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要
使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
--executor-memory 该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常
,也有直接的关联。num-executors乘以executor-memory,是不能超过队列的最大内存量的。
--executor-cores 该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core
同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。Executor的CPU core数量
设置为2~4个较为合适。
--conf spark.default.parallelism 该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
Spark作业的默认task数量为总核数的2~3倍比较好你可以根据你的集群的环境情况,调整参数。由于pyspark跟spark-submit的参数一样,调整好的参数可以直接用到spark-submit上去
我的运行命令如下:
pyspark --master=spark://master:7077 --packages Azure:mmlspark:0.12 --driver-cores 2 --total-executor-cores 12 --conf spark.default.parallelism=25如果你是第一次进入,会看到控制台开始下载mmlspark的相应依赖,如下:
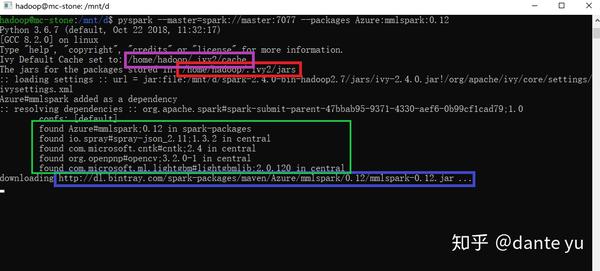
一般直接用pyspark自动下载速度非常慢(至少我是如此),所以大家可以选择自己手动下载,下载地址如下图蓝框所示;然后把依赖放入对应的地址,根据提示行,我们可以知道依赖下载的放置地址~/.ivy2/cache/(红色是安装好后的包位置,不要混淆了),如下图紫框所示,同时在绿框内找到对应的文件的放置地址(如cntk-2.4.jar对应com.microsoft.cntk#cntk;2.4,则jar文件放在~/.ivy2/cache/com.microsoft.cntk/cntk/jars/,即绿框内的名字中的#改成/后的路径下的jars文件夹):

待全部依赖下载完毕,即进入pyspark控制台如下:

运行代码简析
以下是使用kaggle比赛的数据作为演示,比赛简介地址点这里。下面代码中所使用的train_all3.csv和test_all3.csv是已经经过特征工程后整合的数据文件。
from mmlspark import LightGBMRegressor
import pyspark.ml.feature as ft
from pyspark.ml import Pipeline
import pyspark.ml.evaluation as ev
import pyspark.sql.types as typ
# 如果你是通过spark-submit来运行,则需要先实例化一个spark session对象, 在pyspark中spark session对象已经默认生成
# from pyspark import SparkConf, SparkContext
# from pyspark.sql import SparkSession
# conf = SparkConf().setMaster("spark://master:7077").setAppName("MMLSPARK")
# sc = SparkContext(conf = conf)
# spark = SparkSession \
# .builder \
# .appName("MMLSPARK") \
# .enableHiveSupport() \
# .getOrCreate()
# 读取csv数据,这里读取的是事先使用hadoop fs -put命令上传到hadoop里的数据
app_train = spark.read.csv("/homecredit/train_all3.csv", header='true', inferSchema='true')
# 数据预处理, 将本来应该是数字的字符串数据转化数据类型,并替代空值
for col, t in app_train.dtypes:
if t == "string":
app_train = app_train.withColumn(col, app_train[col].cast("double"))
app_train = app_train.withColumn("TARGET", app_train["TARGET"].cast("int"))
app_train = app_train.fillna(999999)
# 跟在普通单机上做训练时不同,spark做训练时所有特征列需要通过VectorAssembler转换成特征矩阵,才能用来训练
featuresCreator = ft.VectorAssembler(
inputCols=[col for col in app_train.columns[1:] if col != "TARGET"],
outputCol='features'
)
# 实例化一个LightGBM Regressor, 其参数和单机版本类似但不尽相同, 文档可以在以下链接找到:
# https://mmlspark.azureedge.net/docs/pyspark/LightGBMRegressor.html
lgbm = LightGBMRegressor(numIterations=120, objective='binary',
learningRate=0.007, baggingSeed=50,
boostingType="goss", lambdaL1=0.4, lambdaL2=0.4,
baggingFraction=0.87, minSumHessianInLeaf=0.003,
maxDepth=9, featureFraction=0.66, numLeaves=47,
labelCol="TARGET"
)
# 建立一个pipeline,简化训练步骤
pipeline = Pipeline(stages=[
# 特征整理
featuresCreator,
# 模型名称
lgbm])
# 这里是将数据分成训练集和验证集,测试模型预测效果
tr, te = app_train.randomSplit([0.7, 0.3], seed=666)
vmodel = pipeline.fit(tr)
t_model = vmodel.transform(te)
evaluator = ev.BinaryClassificationEvaluator(
rawPredictionCol='prediction',
labelCol='TARGET')
print(evaluator.evaluate(t_model,
{evaluator.metricName: 'areaUnderROC'}))
# 实际训练过程
model = pipeline.fit(app_train)
# 测试集的数据预处理和训练
app_test = spark.read.csv("/homecredit/test_all3.csv", header='true', inferSchema='true')
for col, t in app_test.dtypes:
if t == "string":
app_test = app_test.withColumn(col, app_test[col].cast("double"))
app_test = app_test.fillna(999999)
prediction = model.transform(app_test)
# 测试集结果输出,从hadoop里将预测数据下载到本机
res = prediction.select("SK_ID_CURR", "prediction")
res = res.withColumn("TARGET", res["prediction"])
res = res.select("SK_ID_CURR", "TARGET")
res.coalesce(1).write.csv("/homecredit/cluster_lgbm.csv", header='true')以上便是使用mmlspark进行数据挖掘的一个简单demo,欢迎大家对文章指正或提出改进意见!