
Deep Metric Learning

小结一下Deep Metric Learning. 目前不包括Re-id和Face recognition的文章. 仅仅是前段时间要做presentation稍微了解了一下,理解不对的望指正.
Introduction
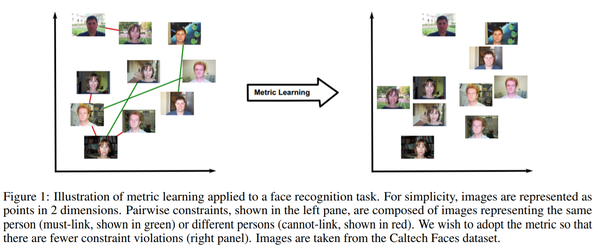
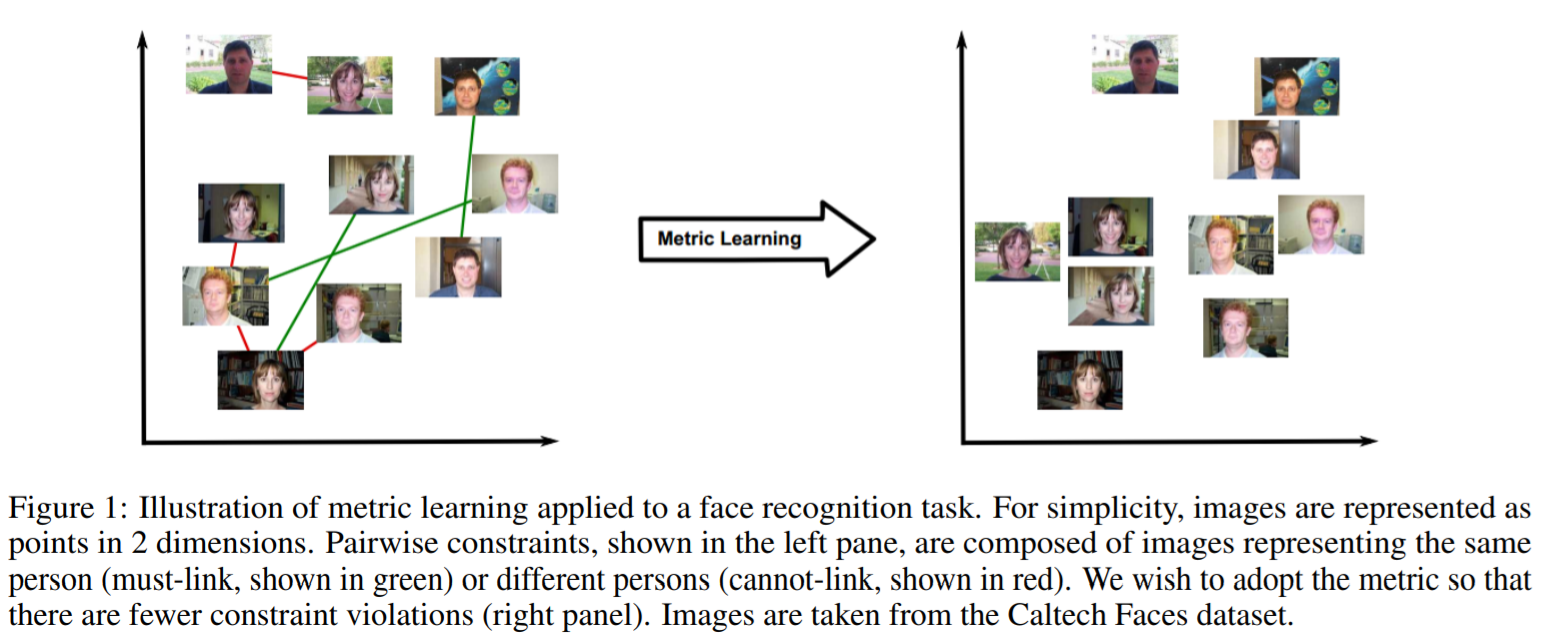
Metric learning 是学习一个度量相似度的距离函数:相似的目标离得近,不相似的离得远. Deep metric learning目前主要是用网络提取embedding,然后在embedding space用L2-distance来度量距离,见下图. 这两个稍微有点不一样,因为还有很多工作是在找距离函数,而不是L2-distance.
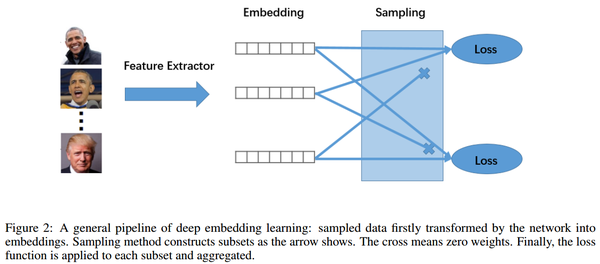
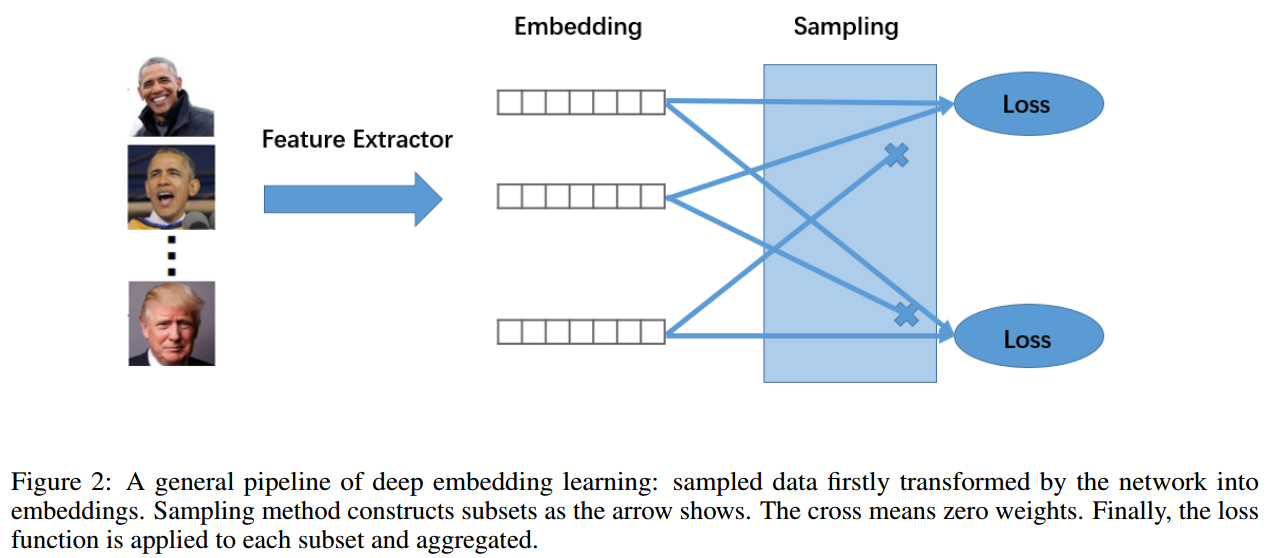
General Pipeline
一般来说,DML包含三个部分:特征提取网络来map embedding,一个采样策略来将一个mini-batch里的样本组合成很多个sub-set,最后loss function在每个sub-set上计算loss.如下图.
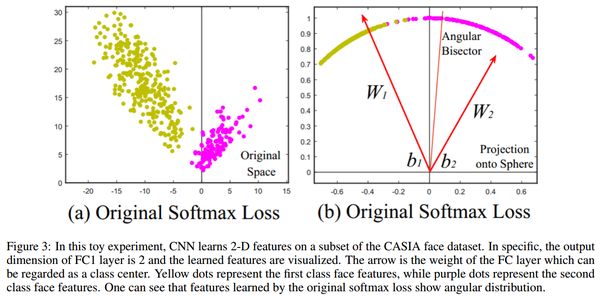
Sample mini-batch一般是C类每类挑K个,共N个.然后通过网络得到embedding.通用的做法是会用L2-normalization来归一化网络的输出,这样得到了单位向量,其L2距离就和cos相似度成正比.很多face recognition的相似的就是基于cos相似度来的.同时也因为softmax会产生这种结构.见下图.

然后就是采样策略,这里我看做是将一个mini-batch里的样本组合成很多个sub-set. 大体步骤如下. 详细的会在后面的具体的采样策略里具体说一下.做这个采样的作用可以提高数据的利用率来加速网络收敛.或者笼统的按[]中说的:In short, sampling matters. It implicitly defines a rather heuristic objective function by weighting samples. Such an approach makes it hard to reproduce and extend the insights to different datasets, different optimization frameworks or different architectures. 最后loss function就是各种特殊的损失函数了.
- 计算embedding distance metric
- 将每个样本都当做一个anchor
- 根据距离挑一部分同类做正样本,一部分其他类做负样本组成sub-set.
- 对每个anchor要么是一个大的sub-set里基本包含整个mini-batch(N个样本)只是权重不同,要么是N个更小的数据对.总的来说计算复杂度是(N*N).
Loss function
Contrastive loss
让网络学到将同类样本map到同一个点,然后不同类样本之间有一个fix的距离.
l ^ {{contrast}} ( i , j ) : = y _ { i j } D _ { i j } ^ { 2 } + \left( 1 - y _ { i j } \right) \left[ \alpha - D _ { i j } ^ { 2 } \right] _ { + } ^ { 2 } \quad y _ { i j } \in \{ 0,1 \}
Triplet Loss
考虑一个anchor+同类样本(正样本)+不同类样本(负样本),triplet loss让负样本的embedding比正样本的embedding离anchor远一个. 此时就不是L2空间中的绝对距离而是相对距离了.同时它不让所有同类样本map到同一点,因为这是没有必要的.
l ^ { t r i p l e t } ( a , p , n ) : = \left[ D _ { a p } ^ { 2 } - D _ { a n } ^ { 2 } + \alpha \right] _ { + }
Margin Based Loss
相对于triplet loss,用一个 来决定正负样本对之间的边界.同时其对偶形式是保序回归(isotonic regression),即关注相对关系而不是绝对关系. 是一个对类adaptive的参数,通过其它超参调节.关于该对偶式推导如下:
\begin{split} & Rewrite\ margin\ loss\ with\ slack \ variable \ \varepsilon \\ & l ^ {margin} : = \sum \left( D _ { i j } - \beta + \alpha - \varepsilon _ { i j } \right) + \left( - D _ { k l } + \beta + \alpha - \varepsilon _ { k l } \right) \\ & st. \\ & \varepsilon _ { i j } \in \left\{ ( i , j ) : y _ { i j } = 1 \right\} \varepsilon _ { k l } \in \left\{ ( i , j ) : y _ { k l } = - 1 \right\} \varepsilon \geq 0 \\ & D _ { i j } - \beta + \alpha - \varepsilon _ { i j } \leq 0\\ & - D _ { k l } + \beta + \alpha - \varepsilon _ { k l } \leq 0\\ & Dual\ form\ i\ isotonic\ regression: \\ & l ^ {margin} : = \sum \varepsilon \\ & st. \\ & \varepsilon _ { i j } \in \left\{ ( i , j ) : y _ { i j } = 1 \right\} \varepsilon _ { k l } \in \left\{ ( i , j ) : y _ { k l } = - 1 \right\} \varepsilon \geq 0 \\ & D _ { k l } + \varepsilon _ { k l } - D _ { i j } + \varepsilon _ { i j } \geq 2 \alpha \\ \end{split}
理解
以上三个算是比较有名的了loss函数了.像n-pairs,lifted我更倾向于是在采样策略,或者说构建sub-set上做的工作.三者目前来说是margin based最好了,关于为什么好下图给了一点自己的理解.
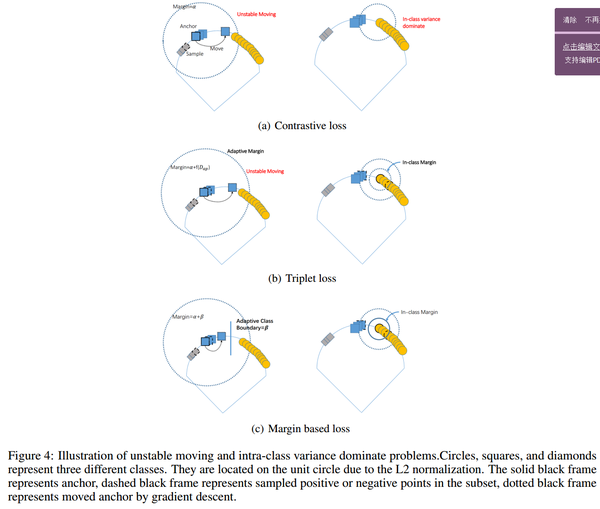
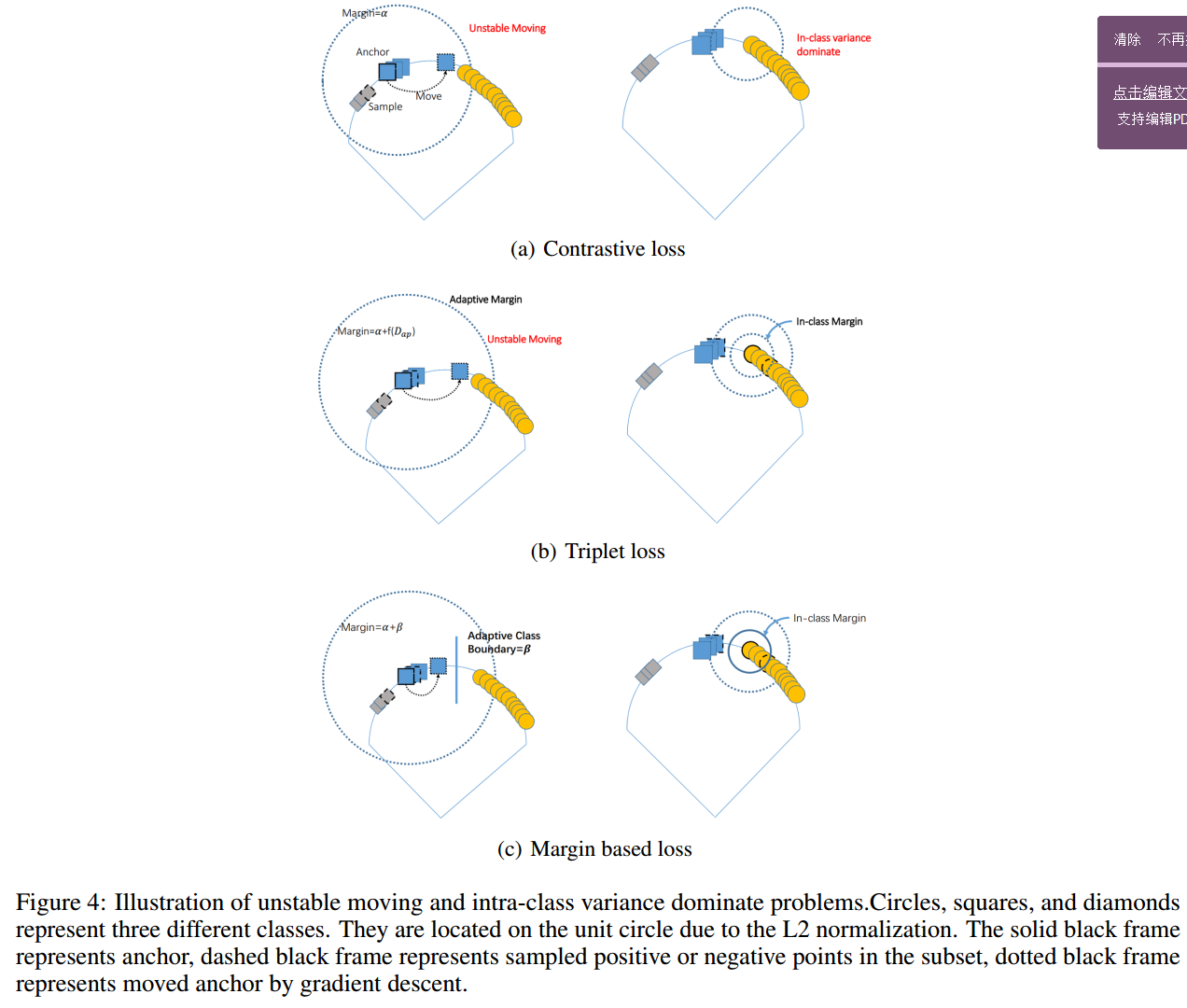
下图是loss function的函数图,margin based 较之前两者主要是gradient 更稳定了,然后margin是相对距离.


采样策略
Naive Sample
最自然的就是按loss里面的项每一对样本都算距离,那么就是N*N对. 对triplet loss来说就是正样本两两之间然后再随机采样(随机不加说明就是均匀采样)一个负样本,也是N*N个triplet个.很多文章说triplet loss不好就是说这个负样本是随机采样的,然后说下面提到的semi-hard不好就是说在采样负样本时只考虑了一个正样本.
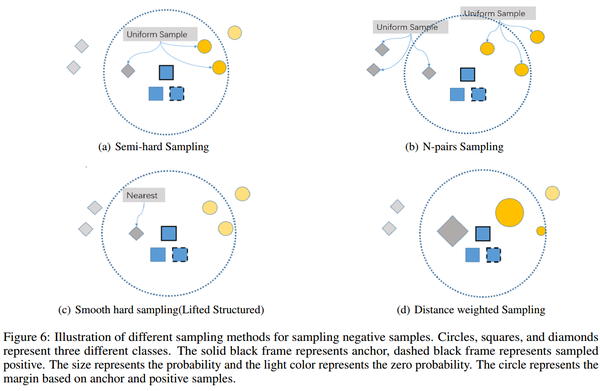
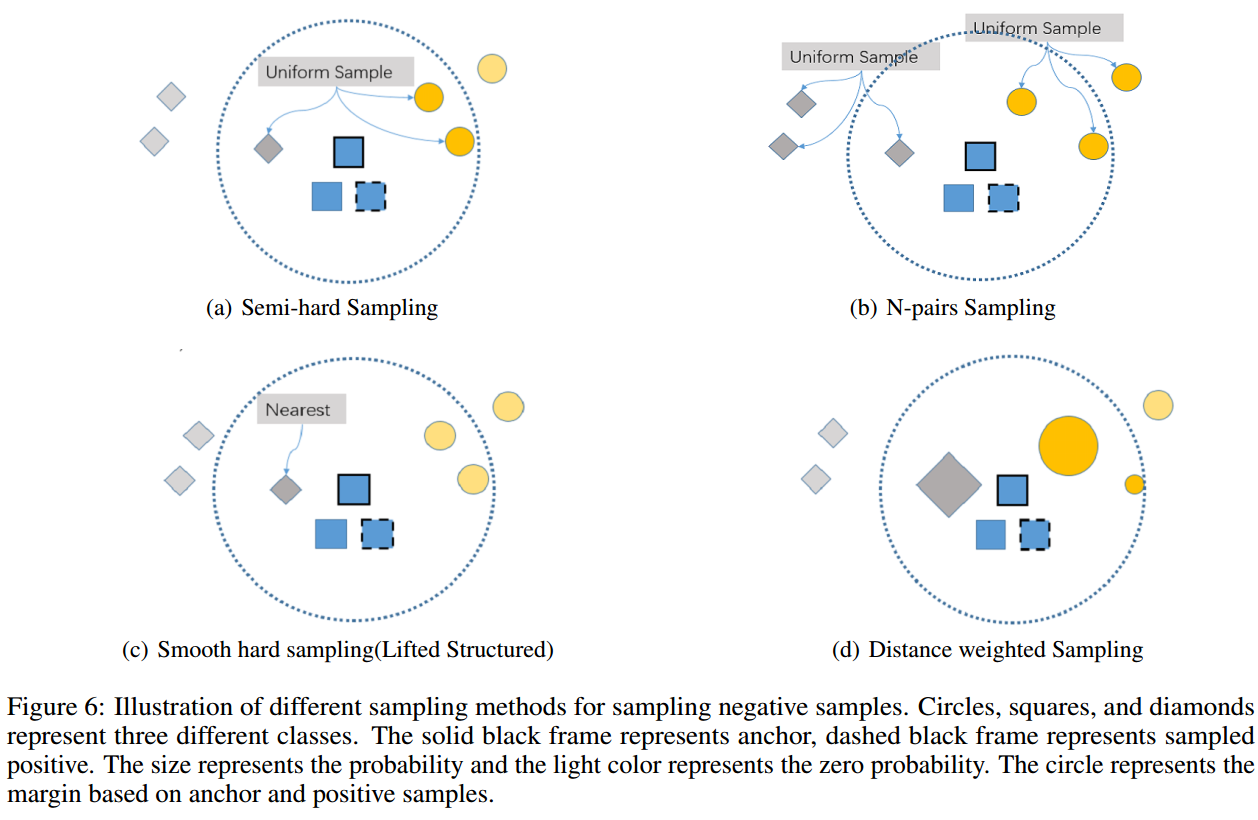
Semi-hard sampling
对一个anchor,loop所有剩下正样本就构建了N个正样本对,然后每对正样本对采样一个负样本,采样规则如下:在相对正样本距离比margin()里的负样本随机采样一个.
\operatorname { Pr } \left( n ^ { \star } = n | a \right) = \frac{\mathbb{I}^S_n}{\# S} \quad S : = \left\{ n : D _ { a n } - D _ { a i } < \alpha, y_{an}=0 \right\}
N-pairs sampling
基于anchor后每类挑个,为了充分利用数据,.其实从期望角度看也可以看做每类随机挑一个.
Smooth hard sampling(Lifted Structured)
Lifted Structured 就是平滑了的挑最难的样本(离anchor最近的负样本,离正样本最近的负样本,然再挑最近的那个),如下:用log-exp-sum函数平滑max函数.
\begin{split} & Nearest \\ & J _ { i j } = \max \left( \max _ { ( a , i ) } \alpha - D _ { a i } , \max _ { ( p , j ) } \alpha - D _ { p j } \right) + D _ { a p } \\ & Smooth \ nearest \\ & J _ { i j } = \log \left( \sum _ { ( a , i ) } \exp \left\{ \alpha - D _ { a i } \right\} +\sum _ { ( p , j ) } \exp \left\{ \alpha - D _ { p j } \right\} \right) + D _ { a p }\\ \end{split}
Distance weighted sampling
按离anchor的远近给负样本不同概率权重,越近越大.还可以和semi-hard结合,只考虑相对距离小的负样本然后再加权.表达式如下:
\operatorname { Pr } \left( n ^ { \star } = n | a \right) \propto \min \left( \lambda , q ^ { - 1 } \left( D _ { a n } \right) \right)
下面是一些是上述策略的示意图:
Experiment Setting
一般的实验都用ImageNet上pre-trained的Resnet50或者Inception v2配上L2-normalization.
常见dataset是Stanford Online Products, CARS196, and the CUB200-2011.
Eval一般是Recall@K和NMI(一般用k-means聚类),都是[0,1]之间,越大越好.具体解释如下:
For Recall@K,Each test image (query) first retrieves K nearest neighbors from the test set and receives score 1 if an image of the same class is retrieved among the K nearest neighbors and 0 otherwise. Recall@K averages this score over all the images \cite{lifted}.NMI is normalized mutual information to evaluate the clustering result with given ground truth clustering . and denotes mutual information and entropy respectively.
Eval时有一个很坑的点是在CARS196和CUB200-2011,有的会将目标抠出来有的不会,这样消除了背景影响效果就会很不错.然后有的论文有时候就拿别人没抠的自己抠了的比,或者不提自己有没有抠图.....
Reference Paper
以上主要参照了以下论文,括号内是文章引用的概念
- A survey on metric learning for feature vectors and structured data (Figure 1)
- Deep metric learning using Triplet network (triplet loss)
- FaceNet: A Unified Embedding for Face Recognition and Clustering (semi-hard,L2-normalization)
- Deep Metric Learning via Lifted Structured Feature Embedding (Lifted Structured)
- Improved Deep Metric Learning with Multi-class N-pair Loss Objective (N-pairs sampling)
- Sampling Matters in Deep Embedding Learning (margin-based loss,Distance weighted sampling)
- SphereFace: Deep Hypersphere Embedding for Face Recognition (Figure 2)
脑洞
单纯讲DML的话就是
- 更好的网络,还有训练策略了
- 更好的loss function.从保序回归那边拿点东西来?
- 最后就是所谓的采样策略到的是不是真的非常重要了,在Sampling Matters in Deep Embedding Learning论文里讲了半天sampling matters然后实验结果一看,远没有loss函数影响大.可能是加速了训练?其实应该就是恰当的hard mining有效吧,然后define好什么是hard,比如配n-pairs来更全局的挑hard而不像semi-hard一样很local的. 那其实考虑考虑些类别之间的relation也感觉不错,比如人和猪的距离比人和凳子的小?
应用的话其实应该是比较重要的,结合不同可以用的问题来针对性优化,设计损失函数让metric learning loss和其它loss匹配. 这里看了一下tracking这边很多相似度度量,然后滤波的tracking还有挺多应用的,Siamese Net这边感觉不多?
然后就是在比较新的Zero/few-shot/meta learning上的应用了,自己这几个领域读的不多.
还有就是在测试时明显抠了比不抠好很多,说明背景影响还是挺大的.因此一个更robust的,能克服occlusion and background influence等等问题的embedding应该应用的话更好,比如在前面提到的tracking.不知道简单的抠图贴图的augmentaiton有没有效果,最近没事的话可以随便试一下
2019
说一下今年我看了的几篇相关的
Signal-to-Noise Ratio: A Robust Distance Metric for Deep Metric Learning(cvpr poster)
把信噪比当距离,而不是L2距离.不知道为什么信噪比不取log对数,还要用L1 regularization来将embedding 0均值化. 结果是在比较低的(Alexnet)benchmark上比的,而且embedding的dim很低.不过看着有一点涨点.(不推荐阅读) 还因为是中国人写的被嘲讽了,虽然我也觉得确实不太好.....头疼
Ranked List Loss for Deep Metric Learning(cvpr poster)
文章写得还不错,可以当某个综述来看.然后就是感觉故意漏了margin-based loss. 因为论文用的loss基本一样,只是fix了. 然后这样用了同样的Distance weighted sampling 配上一个temperature T的超参调节权重 .
论文在Inception v2上配上三个特征层融合特征效果还是不错的.(超参在SOP数据集上调节,所以SOP效果最好,另外两个就一般). 所以当当入门综述可以看看.
Hardness-Aware Deep Metric Learning(cvpr oral)
通过在feature空间插值来构造一些困难的负样本来促进学习.直接的插值无法保证生成的负样本label是正确的,要将其映射到正确的label域:就是学一个分类器了.具体的结合论文自己画了一下流程图:
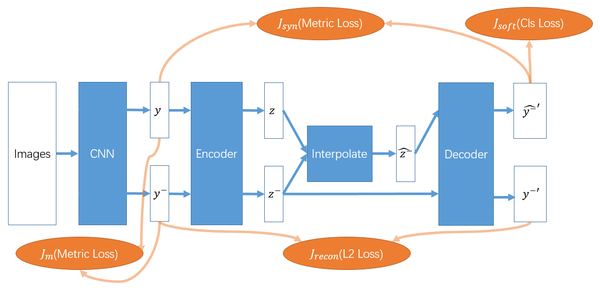
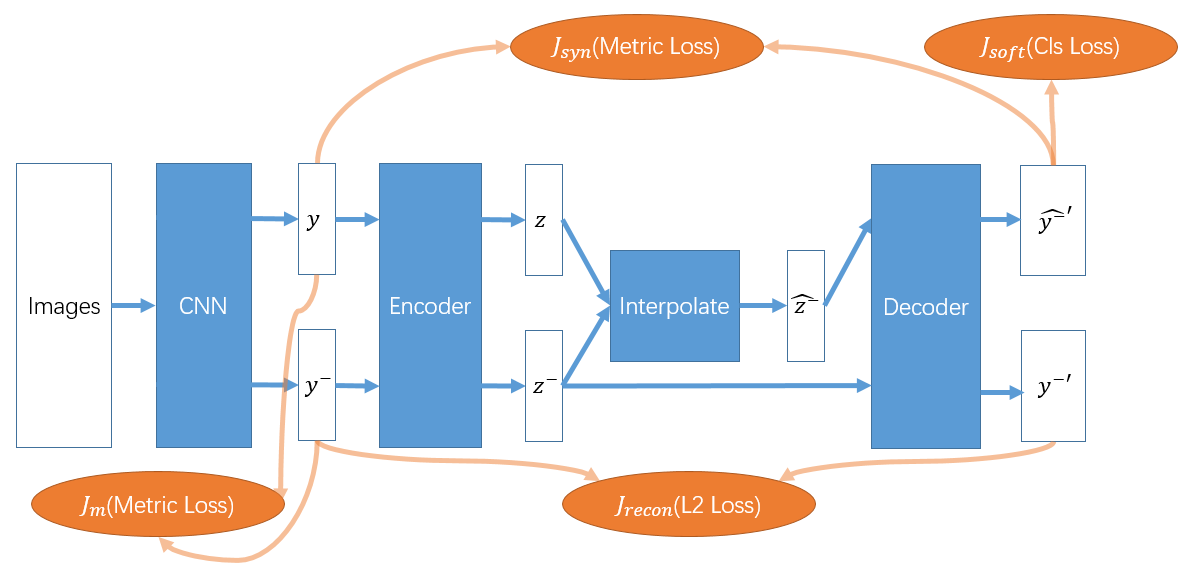
- 首先概念提的不错,但是实际就是把生成模型套上去了.弄的流程比较复杂,而且一堆先验设计+超参.倒不是说把生成模型用进来不好,感觉就是没有insight,然后这个生成模型到底起了什么样的作用不清楚吧.
- 很多DML换个backbone就能上好几个点,这样加上去额外的结构里面包含的参数不比把Inceptionv2换成Resnet50要少吧.
- 另外加了结构涨点也不算是很显著的稳定.对R1,Cars196数据集上比N-pairs涨了10个点,因为很多超参是在这个数据集上调的,在CUB200上就只涨了1.8个点.
今年CVPR19几篇论文都是所谓生成恰当的负样本.但是怎么证明说你把生成模型套进来了确实有效而不是说单纯的其实就是加了额外的监督(分类)或者参数量导致的涨点都没有看见论文在考虑这些个问题.
Deep Metric Learning Beyond Binary Supervision(cvpr oral)
Energy confused Adversarial Metric Learning for Zero-Shot Image Retrieval and Clustering(AAAI Spotlight)
课程小项目:
Robust deep metric learning by disentangling background augmentation: 就是用inpainting来换背景训练. 主要是想看bg的影响. 贴一下划水的poster:


其它
存一下其它有关的文章:
FaceNet 源码解读,看select_triplets函数的semi-hard实现: https://blog.csdn.net/liyuan123zhouhui/article/details/71427799
Face recognition loss和embedding的有趣可视化
一个pytorch实现的DML的集合,跑了一下结果都是对的,挺不错的.思路也算是分离成了loss和sampling,可以两两之间拼着试一下.
然后发现整个训练过程基本第一个epoch就到了很高,比如44然后最后也就到50.后面可能是在学精细化特征,然后显然train的不太好?
