![Linux中的Anonymous Pages和Swap [一]](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
Linux中的Anonymous Pages和Swap [一]

在进程的地址空间中,包括heap, stack和通过mmap匿名映射的区域,这些区域在建立的时候只有虚拟地址,当它们真正被访问到的时候,内核才会为其分配物理页面,这种方式被称作demand allocation(按需分配),它和page cache的demand paging的概念是对应的。这部分物理页面由于没有对应外部存储介质上的文件,因此被统称为anonymous pages。
Anonymous pages同page cache一样,也是可以被回收的,但由于没有对应的后备文件,因此在回收anonymous pages的时候,不能像只读的page cache(比如text段)一样直接discard,或者像可读写的page cache(比如data段)一样flush同步后discard,而是需要保存这些anonymous pages的内容,这样才能在以后再次访问这些页面的时候,获得它们被回收前所包含的数据。
为此,磁盘上会开辟专门的swap space作为这些页面内容的backing store。swap space由若干的swap areas组成,swap area的最大数目由"MAX_SWAPFILES"确定(在4.19内核中这个宏的值为32)。
swap area可以有两种类型:swap partition和swap file,区别是swap partition在磁盘上是连续分布的,就像一个「裸」的磁盘设备一样,而swap file的内容则不一定连续分布,更像是基于磁盘设备的一个文件(参考这篇文章,需要注意的是,有时内核中会用"swapfile"这个术语统称这两者)。
Swap Area的创建
以生成swap file为例,首先使用"dd"命令创建一个空的文件,设置其路径名称(假设为"/swapfile1")和大小(假设为1GB)。
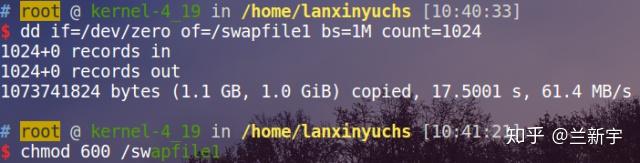

而后使用"mkswap"命令(源码位于util-linux-ng工具集中)在这个文件上创建swap area,最后使用"swapon"命令来初始化和激活这个swap area。

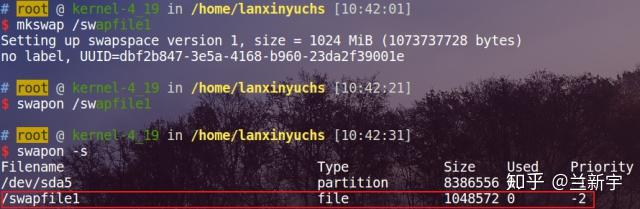
可通过"cat /proc/swaps"或者"swapon -s"命令获知系统包含的所有swap areas,在我的系统中,只有一个swap area,且其类型为swap partition:


如果有多个swap area,那么"Priority"高的swap area将被优先使用。
Swap Area的构成
这些swap areas分散在不同的块设备上,这样有助于实现硬件的并行访问。一个swap area在内核中由一个swap_info_struct结构体来描述和管理,整个swap space可以用swap_info[]数组表示。
/* The in-memory structure used to track swap areas. */
struct swap_info_struct {
// 在swap_info[]中的索引编号
signed char type; /* strange name for an index */
// 数组指针,指向存储page引用计数的数组
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
// 所处的块设备
struct block_device *bdev; /* swap device or bdev of swap file */
...
}
每个swap area又由若干的slots(也叫swap entry)组成,每个slot的大小和内存page的大小相同,其中第一个slot比较特殊,里面存放的是这个swap area的控制信息,用swap_header表示(类似于ELF header)。
swap_map作为指针,指向一个长度等于swap area中slots数目的数组,其主要作用将体现在下文将要介绍的swap in的过程中。
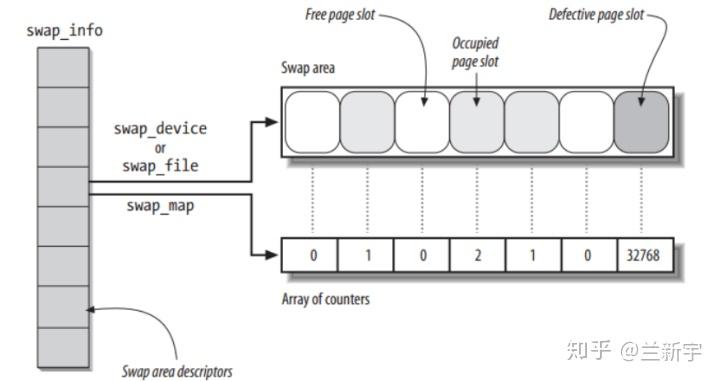

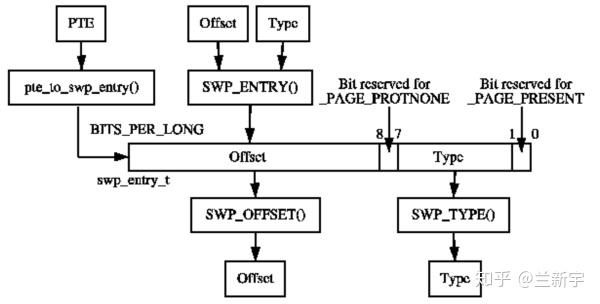
一个slot在磁盘上的位置,由它所在的swap area,以及它在这个swap area中的编号决定,两者合在一起就构成了swp_entry_t,其实就是一个整形数而已。
typedef struct {
unsigned long val;
} swp_entry_t;
内核使用了其中6个bits作为swap_info[]数组的索引,用于查找对应的swap area,索引值用swp_type()函数从swp_entry_t中提取。把索引命名为"type"也是挺奇怪的,这在上面介绍swap_info_struct结构体的"type"的注释中也能看出。
struct swap_info_struct *swap_info[MAX_SWAPFILES];
struct swap_info_struct *sis = swap_info[swp_type(swp_entry_t)];
24个bits作为swap area内的索引,用于查找对应的slot,索引值用swp_offset()函数从swp_entry_t中提取。
unsigned long offset = swp_offset(swp_entry_t);

Swap Out - 从内存到磁盘
内核在回收anonymous pages前,会把它们的内容复制到一个swap area的某个slot中保存起来,这个过程叫做swap out,对应的执行函数是add_to_swap()。


首先需要调用get_swap_page()函数从swap area中分配空余的slot,然后增加swap cache(交换缓存)对准备swap out的页面的指向,并标记这个页面的状态为"dirty"。由于swap cache的作用主要体现在swap in的过程中,因此将放在下文详细介绍。
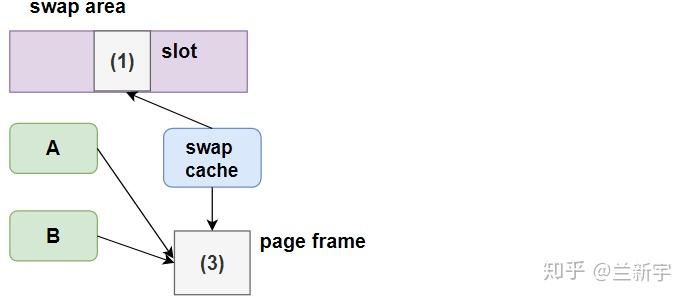
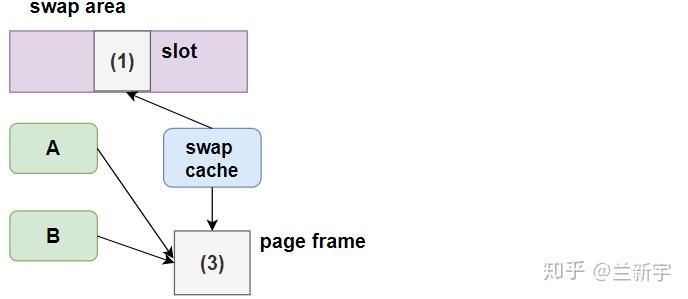
等到调用swap_writepage(),才会执行真正的I/O操作,将页面的内容写入外部的swap area,然后清除swap cache对页面的指向,释放页面所占的内存。
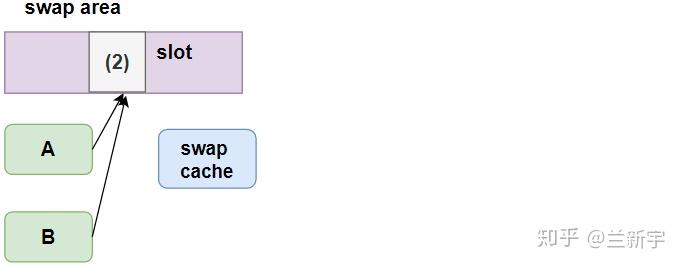
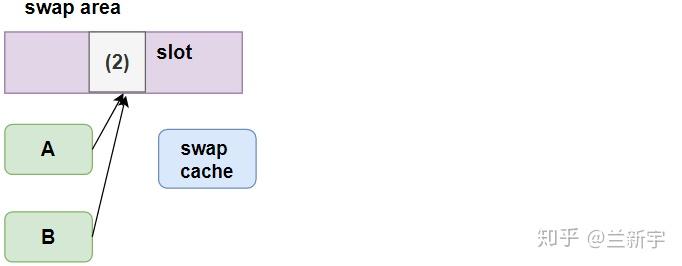
关于在此过程中vma的"vm_page_flags", PTE, page的"flags"的变化,请参考这张图片。
从swap area中寻找空闲的slot的过程,其实和内存分配时寻找空闲的page很像。接下来将以SSD作为外部存储介质为例,讲解分配swap slot的具体方法。
【swap cluster】
对于传统的磁盘设备,最好将访问的数据连续分布,以加快读写速度,减少磁盘碎片。对于特性与磁盘完全不同的SSD来说,随机读写的速度也是很快的,把数据集中放在物理相邻的位置不仅没必要,反倒对SSD需要的损耗均衡(wear leveling)是不利的。
为此,在内核3.12版本上加入了一项特性,当swap子系统知道它正在使用SSD时,它会将设备划分为clusters,每个cluster包括"SWAPFILE_CLUSTER"个pages(4.19内核中这个宏的值是256)。
"swap_info_struct"结构体中和cluster相关的域如下(各项的具体含义将在后面的描述中逐渐解释):
/* Only for SSD */
struct swap_cluster_list free_clusters; /* free clusters list */
unsigned int cluster_next; /* likely index for next allocation */
unsigned int cluster_nr; /* countdown to next cluster search */
每个CPU有对应的cluster,由swap_cluster_info结构体管理。
struct swap_cluster_info {
spinlock_t lock;
unsigned int data:24;
unsigned int flags:8;
};
CPU会从自己的cluster上分配slot,这样既可以减少CPU之间的竞争,增加swap out时系统总的througout,也可以让数据在SSD上的分布更加分散,更详细的介绍请参考这篇文章。
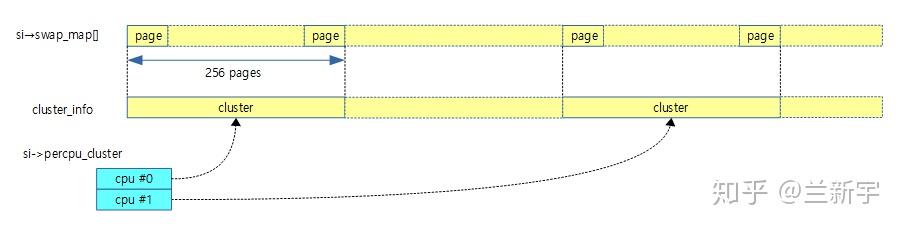

伴随使用过程中slot的释放,cluster中会出现若干空闲的slots,但如果分配时从这些空闲的slots中寻找,效率较低,因此采用的是从cluster中未分配的slots查找(未分配的slots数目由"cluster_nr"表示)。
当一个cluster耗尽后("cluster_nr"的值为0),可调用swap_alloc_cluster()函数从"free_clusters"中获取一个新的cluster("cluster_next"是下一个要使用的cluster的第一个slot的编号)。如果已经没有新的cluster,再从既有的clusters中进行更细粒度的空闲slots查找。
当一个CPU的cluster用完时,也可能会使用其他CPU的cluster,这就是为什么"swap_cluster_info"中存在spinlock的原因。为了加快分配速度,可以采用swap slot cache(注意区别于swap cache)。
在swap area找到空闲的slot后,swp_entry_t就确定下来了,那这个swp_entry_t的信息保存在什么地方呢,请看下文分解。
参考:
http://jake.dothome.co.kr/swap-1/
原创文章,转载请注明出处。
