
Pytorch 单机并行训练

未经授权,严禁转载!
另外,近一年没用过这个了,所以内容自己也记不得了,各位读者朋友们,抱歉不能回答你们的问题。
个人主页:
参考:
CUDA 基本使用
查看 GPU 信息
更多接口,参考 torch.cuda。
torch.cuda.is_available() # 判断 GPU 是否可用
torch.cuda.device_count() # 判断有多少 GPU
torch.cuda.get_device_name(0) # 返回 gpu 名字,设备索引默认从 0 开始
torch.cuda.current_device() # 返回当前设备索引torch.device
torch.device 表示 torch.Tensor 分配到的设备的对象。其包含一个设备类型(cpu 或 cuda),以及可选的设备序号。如果设备序号不存在,则为当前设备,即 torch.cuda.current_device() 的返回结果。
可以通过如下方式创建 torch.device 对象:
# 通过字符串
device = torch.device('cpu')
device = torch.device('cuda:1') # 指定类型及编号。注意,代码不会检查编号是否合法
device = torch.device('cuda') # 默认为当前设备还可以通过设备类型加上编号,来创建 device 对象:
device = torch.device('cuda', 0)
device = torch.device('cpu', 0)配置 CUDA 访问限制
可以通过如下方式,设置当前 Python 脚本可见的 GPU。
在终端设置
CUDA_VISIBLE_DEVICES=1 python my_script.py实例
Environment Variable Syntax Results
CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional
CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
CUDA_VISIBLE_DEVICES="" No GPU will be visible在 Python 代码中设置
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 2"使用函数 set_device
import torch
torch.cuda.set_device(id)官方建议使用CUDA_VISIBLE_DEVICES,不建议使用set_device函数。
单机单卡训练
用 GPU 训练
默认情况下,使用 CPU 训练模型。可以通过如下方式,通过 GPU 进行训练。使用 GPU 时,模型和输入必须位于同一张 GPU 上。
.to(device) 和 .cuda() 的区别如下:
.to()中的参数必不可少- 对于
module而言,.to()是inplace的,而.cuda()不是;而对于tensor而言,两者一致。
注:实测,两者时间消耗持平。
方式 1 :
device = torch.device("cuda:1") # 指定模型训练所在 GPU
# 将 GPU 转移至 GPU
if torch.cuda.is_available() and use_gpu:
net = net.cuda(device) # 默认在第一块 GPU 上训练
# 同时将数据转移至 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.cuda(device)
labels = labels.cuda(device)方法 2 :
device = torch.device("cuda:1") # 指定模型训练所在 GPU
# 将 GPU 转移至 GPU
if torch.cuda.is_available() and use_gpu:
net = net.to(device) # 默认在第一块 GPU 上训练
# 同时将数据转移至 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.to(device)
labels = labels.to(device)存在的问题
batch size 太大
当想要用大批量进行训练,但是 GPU 资源有限,此时可以通过梯度累加(accumulating gradients)的方式进行。
梯度累加的基本思想在于,在优化器更新参数前,也就是执行 optimizer.step() 前,进行多次反向传播,是的梯度累计值自动保存在 parameter.grad 中,最后使用累加的梯度进行参数更新。
这个在 PyTorch 中特别容易实现,因为 PyTorch 中,梯度值本身会保留,除非我们调用 model.zero_grad() 或 optimizer.zero_grad()。
修改后的代码如下所示:
model.zero_grad() # 重置保存梯度值的张量
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # 前向计算
loss = loss_function(predictions, labels) # 计算损失函数
loss.backward() # 计算梯度
if (i + 1) % accumulation_steps == 0: # 重复多次前面的过程
optimizer.step() # 更新梯度
model.zero_grad() # 重置梯度model 太大
当模型本身太大,以至于不能放置于一个 GPU 中时,可以通过梯度检查点 (gradient-checkpoingting) 的方式进行处理。
梯度检查点的基本思想是以计算换内存。具体来说就是,在反向传播的过程中,把梯度切分成几部分,分别对网络上的部分参数进行更新。如下图所示:
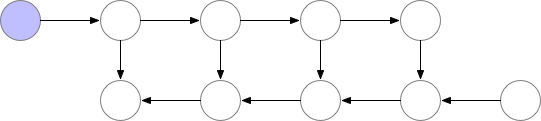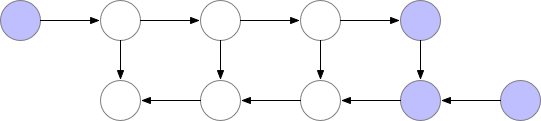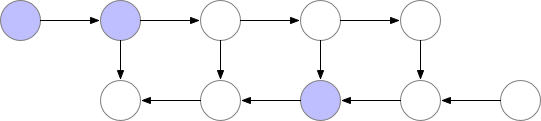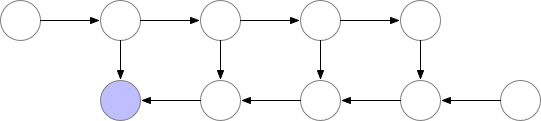

这种方法速度很慢,但在某些例子上很有用,比如训练长序列的 RNN 模型等。
具体可参考:From zero to research — An introduction to Meta-learning
单机多卡训练 —— 并行训练
单机多卡训练,即并行训练。并行训练又分为数据并行 (Data Parallelism) 和模型并行两种。
数据并行指的是,多张 GPU 使用相同的模型副本,但是使用不同的数据批进行训练。而模型并行指的是,多张GPU 分别训练模型的不同部分,使用同一批数据。
两者对比如下图所示:
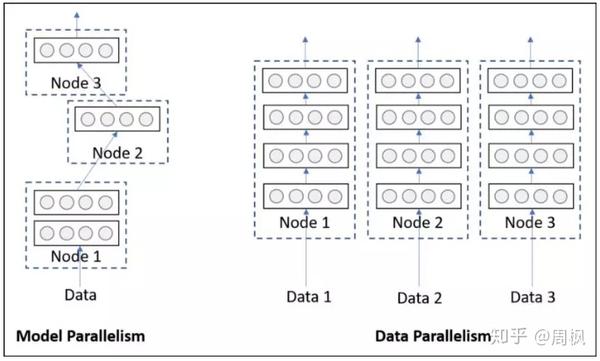

数据并行
Pytorch API
【Class 原型】
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)【参数】
- module :要进行并行的
module。这里隐含了一点 ,即网络中的某一层也是可以进行数据并行的,但是一般不会这么使用。 - device_ids :
CUDA列表,可以为torch.device类型,也可以是编号组成的int列表。默认使用全部 GPU - output_device : 某一
GPU编号或torch.device。指定输出的GPU,默认为第一个,即device_ids[0]
【返回值】
要进行并行的模型。
【基本使用方式】
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
>>> output = net(input_var) # input_var can be on any device, including CP数据并行的原理
数据并行的具体原理流程为:
- 将模型加载至主设备上,作为
controller,一般设置为cuda:0
- 在每次迭代时,执行如下操作:
- 将
controller模型复制(broadcast)到每一个指定的GPU上
- 将总输入的数据
batch,进行均分,分别作为各对应副本的输入 (scatter)
- 每个副本独立进行前向传播,并进行反向传播,但只是求取梯度
- 将各副本的梯度汇总(
gather)到controller设备,并进行求和 (reduced add)During the backwards pass, gradients from each replica are summed into the original module.
- 更具总体度,更新
controller设备上的参数
注意事项
【警告 1】
- 设置的
batch size为总的批量尺寸,其必须大于GPU数量。 - 在
parallelized module运行之前,必须保证其在controller设备上,存在参数和buffers。 - 并行的
GPU列表中,必须包含主GPU - 当
forward()中,module返回一个标量,那么并行的结果将返回一个vector,其长度等于device的数量,对应于各个设备的结果。
【警告 2】
在每次前向传播过程中,module 都先会被复制到每一个 device 上。因此,在前向传播中,任何对该运行的 module 的副本的更新,在此后都将会丢失。
比方说,如果 module 有一个 counter 属性,每次前向传播都会进行累加,则它将会保持为初始值。因为更新是发生在模型的副本(在其他 device 上的副本)上的,并且这些更新在前向传播结束之后将会被销毁。
然而,DataParallel 保证 controller 设备上的副本的参数和 buffers 与其他并行的 modules 之间共享存储。因此,如若对 controller device 的 参数和 buffers 的更改,将会被记录。例如,BatchNorm2d 和 spectral_norm() 依赖于这种行为来更新 buffers。
【警告 3】
定义于 module 及其子 module 上的前向传播和反向传播 hooks,将会被调用 len(device_ids) 次,每个设备对应一次。
具体来说,hooks 只能保证按照正确的顺序执行对应设备上的操作,即在对应设备上的 forward() 调用之前执行,但是不能保证,在所有 forward)() 执行之前,通过 register_forward_pre_hook() 执行完成所有的 hooks。
【警告 4】
任何位置和关键字 (positional and keyword) 输入都可以传递给 DataParallel,处理一些需要特殊处理的类型。
tensors 将会在指定维度(默认为 0)上被 scattered。 tuple, list 和 dict 类型则会被浅拷贝。其他类型则会在不同的线程之间进行共享,且在模型前向传播过程中,如果进行写入,则可被打断。
【警告 5】
当对 pack sequence -> recurrent network -> unpack sequence 模式的 module 使用 DataParallel 或 data_parallel 时,有一些小的问题。
每个设备上的 forward 的对应输入,将仅仅是整个输入的一部分。因为默认的 unpack 操作 torch.nn.utils.rnn.pad_packed_sequence() 只会将该设备上的输入 padding 成该设备上的最长的输入长度,因此,将所有设备的结构进行汇总时,可能会发生长度的不匹配的情况。
因此,可以利用 pad_packed_sequence() 的 total_length 参数来保证 forward() 调用返回的序列长度一致。代码如下所示:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class MyModule(nn.Module):
# ... __init__, other methods, etc.
# padded_input is of shape [B x T x *] (batch_first mode) and contains
# the sequences sorted by lengths
# B is the batch size
# T is max sequence length
def forward(self, padded_input, input_lengths):
total_length = padded_input.size(1) # get the max sequence length
packed_input = pack_padded_sequence(padded_input, input_lengths,
batch_first=True)
packed_output, _ = self.my_lstm(packed_input)
output, _ = pad_packed_sequence(packed_output, batch_first=True,
total_length=total_length)
return output
m = MyModule().cuda() # 设置 controller 模型
dp_m = nn.DataParallel(m) # 进行副本拷贝示例程序
下面是使用 DataParrel 的核心代码,其余部分与一般的训练流程一致。
# 设置当前脚本可见的 GPU 列表
# 这里设置 0 号和 1 号 GPU 对当前脚本可见。
# 此时,若 DataParallel 中指定使用其他 GPU 资源,额外的编号将会被忽略
os.environ["CUDA_VISIBLE_DEVICES"] = "0, 1"
# 使用数据并行
# 1. 将 model 转移到某 GPU 上 -- net.cuda()
# 2. 指定并行训练要用到的 GPU -- device_ids=[0, 1]
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
net = nn.DataParallel(net.cuda(), device_ids=[0, 1])
# 将数据转移到 controller 所在 GPU
if torch.cuda.is_available() and use_gpu:
inputs = inputs.cuda(device)
labels = labels.cuda(device)模型的加载
def _Single2Parallel(self, origin_state):
"""
将串行的权值参数转换为并行的权值参数
:param origin_state : 原始串行权值参数
:return : 并行的权值参数
"""
converted = OrderedDict()
for k, v in origin_state.items():
name = "module." + k
converted[name] = v
return converted
def _Parallel2Single(self, origin_state):
"""
将并行的权值参数转换为串行的权值参数
:param origin_state : 原始串行权值参数
:return : 并行的权值参数
"""
converted = OrderedDict()
for k, v in origin_state.items():
name = k[7:]
converted[name] = v
return converted模型并行
如果模型本身较大,一张 GPU 放置不下时,要通过模型并行来处理。模型并行指的是,将模型的不同部分,分别放置于不同的 GPU 上,并将中间结果在 GPU 之间进行传递。
尽管从执行时间上来看,将模型的不同部分部署在不同设备上确实有好处,但是它通常是出于避免内存限制才使用。具有特别多参数的模型会受益于这种并行策略,因为这类模型需要很高的内存占用,很难适应到单个系统。
基本使用
下面,我们以一个 toy 模型为例,讲解模型并行。模型并行的实现方式如下所示:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features_1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True), # 30
......
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # 12
).to('cuda:0')
self.features_2 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True), # 5
......).to('cuda:1') # 1
self.classifier = nn.Sequential(
nn.Dropout(),
......
nn.Linear(1024, class_num)).to('cuda:1')
def forward(self, x):
out = self.features_1(x.to('cuda:0'))
out = self.features_2(out.to('cuda:1'))
out = out.view(-1, 384)
out = self.classifier(out)
out = F.softmax(out, dim=1)
return out上面的 toy 模型看起来和在单个 GPU 上运行的模型没什么区别,只不过用 to(device) 来将模型内的不同层分散到不同的 GPU 上进行运行,并且将中间结果转移到对应的 GPU 上即可。
backward() 和 torch.optim 将会自动考虑梯度,与在一个 GPU 上没有区别。
注意:在调用loss函数时,labels与output必须在同一个GPU上。
# 此时,不在此需要使用 model = model.cuda()
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
for data in trainloader:
images, labels = data
# 要处理的部分
images = images.to('cuda:0')
labels = labels.to('cuda:1') # 必须与输出所在 GPU 一致
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()模型并行的性能分析
以上的实现解决了单个模型太大,不能存放于一个 GPU 的情况。然而,需要注意的是,相较于在单个 GPU 上运行,其速度更慢。因为任何时候,只有一个 GPU 在工作,而另一个则闲置。而当中间结果在 GPU 之间进行转移时,速度会进一步下降。
下面同时实例分析。以 resnet50 为例,用随机生成的数据输入,比较两个版本的运行时间。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
import numpy as np
import timeit
num_repeat = 10
stmt = "train(model)"
setup = "model = ModelParallelResNet50()"
# globals arg is only available in Python 3. In Python 2, use the following
# import __builtin__
# __builtin__.__dict__.update(locals())
mp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)
setup = "import torchvision.models as models;" + \
"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)
def plot(means, stds, labels, fig_name):
fig, ax = plt.subplots()
ax.bar(np.arange(len(means)), means, yerr=stds,
align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xticks(np.arange(len(means)))
ax.set_xticklabels(labels)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig(fig_name)
plt.close(fig)
plot([mp_mean, rn_mean],
[mp_std, rn_std],
['Model Parallel', 'Single GPU'],
'mp_vs_rn.png')结果如下所示。模型并行相较于单 GPU 训练的模型,训练时间开销多出 4.02/3.75-1=7% 左右。当然,这存在优化空间,因为多 GPU 中,每一时刻只有一个 GPU 进行训练,其他闲置。而在中间数据转移过程中,又消耗一定的时间。
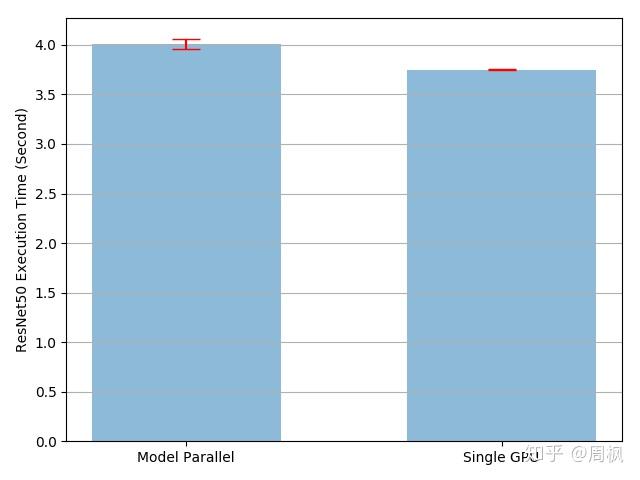

输入流水线
解决上面的问题的最直接的方式就是使用流水线技术,即 GPU-0 输出到 GPU-1 之后,在 GPU-1 训练的同时,GPU-0 接收下一批数据,这样就可以多 GPU 同时执行了。
下面,我们将 120 个样本的 batch 再次细分,分为 20 张样本每份的小 batch。由于 Pytorch 同步启动 CUDA 操作,因此,该操作不需要使用额外的多线程来处理。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')需要注意的是,device-to-device 的 tensor copy 操作是同步的。如果创建多个数据流,则需要保证 copy 操作以合适的同步方式进行。
在完成 tensor 拷贝之前,对 source tensor 进行写入,或者对 target tensor 进行读写,都可能会导致不可预期的行为。上面的实现中,在源和目标设备中,均只使用了默认的 stream,因此无需额外的强化同步操作。


如上图所示,流水线输入确实加速了训练进程,大约 3.75/2.51-1=49%,但距离 100% 的加速相去甚远。由于我们在流水线并行实现中,引入了一个新的参数 split_sizes,但是并不知晓其对训练时间的影响。
直觉上来说,使用一个小的 split_sizes 将会导致许多微小的 CUDA 内核的启动,而使用较大的 split_sizes,则会导致较长的空闲时间。下面是一个搜索最佳 split_sizes 的实验。
means = []
stds = []
split_sizes = [1, 3, 5, 8, 10, 12, 20, 40, 60]
for split_size in split_sizes:
setup = "model = PipelineParallelResNet50(split_size=%d)" % split_size
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
means.append(np.mean(pp_run_times))
stds.append(np.std(pp_run_times))
fig, ax = plt.subplots()
ax.plot(split_sizes, means)
ax.errorbar(split_sizes, means, yerr=stds, ecolor='red', fmt='ro')
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xlabel('Pipeline Split Size')
ax.set_xticks(split_sizes)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig("split_size_tradeoff.png")
plt.close(fig)实验结果如下所示:
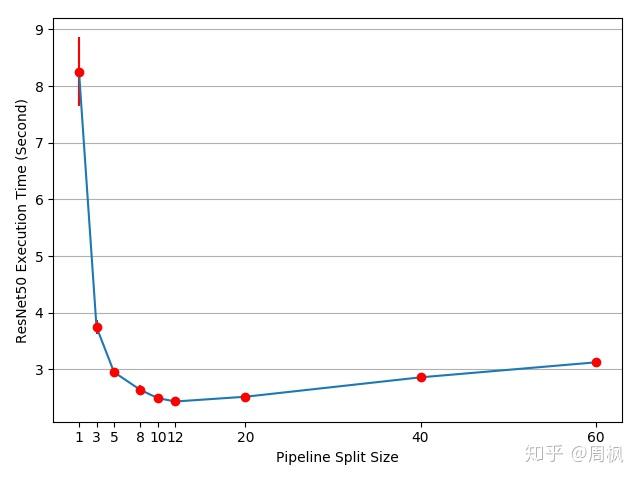

如上图所示,最佳的参数为 12,其将导致 3.75/2.43-1=54% 的加速。但这仍存在加速的可能。例如,所有在 cuda:0 上的操作放在默认的 stream 上。这意味着,在下一个 split 上的计算,不能与上一个 split 的 copy 操作进行重叠。然而,由于 next_split 和 prev_plit 是不同的 tensor,因此这不存在问题。
该实现需要在每个 GPU 上使用多个 stream,并且模型中不同的子网络需要使用不同的 stream 管理策略。
