PN-23: Diversity is All Your Need (arXiv 1802)


Title: DIVERSITY IS ALL YOU NEED: LEARNING SKILLS WITHOUT A REWARD FUNCTION
(都喜欢取这么花哨的title吗,Transformer - 《Attention is All Your Need》系列...)
核心思想:
对于RL来说,是否能够学到desired的policy通常极度依赖reward function design,另一方面,RL是对一个stationary MDP的learning,学习到的策略往往只能用于特定的任务。
受人类学习过程的启发,这篇文章研究,agent如何在没有task-dependent reward的情况下,也能学习到多样化的skill、policy。
paper将skill定义为latent-dependent policy,即以离散随机变量为条件的policy,为了使学习到的skills能够尽可能cover所有的behavior,作者希望skills尽可能多样化。
为此,提出了DIAYN方法,通过最大化skill与state之间的mutual information,来push不同的skill既diverse又distinguishable,确保有效的skills的学习,从而能够进一步作为好的parameter initialization和或应用于hierarchical learning/imitation learning
主要内容:
1)skill 的含义


感觉也可以理解成sub-policy,相应在文中policy的表示如下所示,z是代表skill类别的离散随机变量
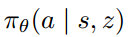
2)three key ideas
如何在没有reward的setting学习不仅diverse,而且有含义、有用的skill,文章提出的DIAYN构建于三个idea上
a. 不同task visit不同的states,因而skill是distinguishable的
b. 用states而不是actions来区分skills,因为许多动作可能导致环境发生相同的转移
c. 让skill尽可能diverse,尽可能随机的act,但始终要保持distinguishable
3)DIAYN
形式化定义如下所示,z~p(z)是作用在policy上的表示离散skill的随机变量,I和H分别表示mutual information和shannon entropy


a. 最大化skill和state之间的mutual information(此处paper中应该是符号错误),希望skill能够control agent visit的state。
另一个角度理解,最大化skill和state的mutual information表示我们能从当前的state推测出对应的skill
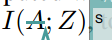
b. 最小化在给定state下skill和action的mutual information,强调不能以action来区分skill
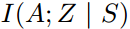
c. 最后为了encourage exploration,最大化所有skill的mixed policy的熵
总的来说,优化目标为:
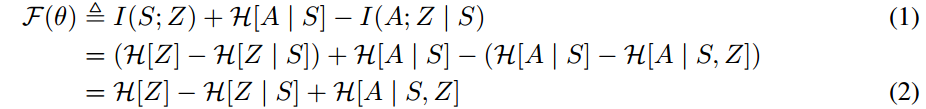

在式2的形式中,第一项表示了z的先验分布的entropy,这里fix p(z)是离散变量z上的均匀的分布,故此项为常数;第二项表示在state下要很容易能推测出skill(与skill-state的mutual information对应);第三项则表示,每个skill要尽可能随机。
由于无法对所有state和skill上对 p(z|s) 进行计算,paper提出用一个discriminator 来拟合这个后验分布,即

基于 Jensen's 不等式,替换真实后验分布,得到一个variational lower bound,如下:
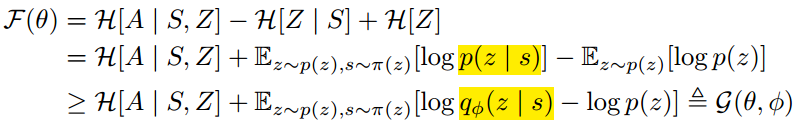

这就得到实际的优化目标
4)implementation
a. 基于soft ac 构建算法,soft ac 本身在policy 优化过程中,包括了对policy entropy的maximization,也就是对应objective G(\theta, \phi) 中的第一项
b. 将objective G(\theta, \phi) 中的第二项(expectation),替换为reward function,在soft ac的训练过程中进行优化:
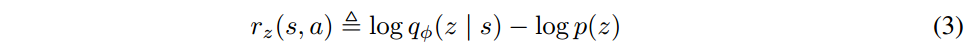

p(z) 是分类分布,每个episode 中,sample一个z,采样直到episode结束
c. discriminator从sample rollout的experience中,训练如何通过state来infer对应的skill;式3中的reward的直观含义是,agent应该到更新policy/skill,使得agent在特定skill下到达的state能够容易地推断出对应的skill
文章这边提到DIAYN在面对不同的random seed得到了稳定的convergence performance。这一点是因为policy和discriminator的adversarial unsupervised RL training,实际上形成了一个cooperative game,如果discriminator能更好地从state推断skill,skill获得reward也将更加稳定,从而引导policy update得到更加distinguishable的skills,这是一个趋于稳定的adversarial过程(个人理解)。
实验:
实验部分的分析主要包括两部分,首先是对DIAYN学到的diiverse skill的分析,其次是对downstream的application的evaluation
1)analysis of learned skills
a. Figure 2 中的4个task中,表现出train得skills的确如上文所愿,cover不同的state space,高度可区分且具有随机性;另外,在inverted pendulum和mountain car这两个classic control tasks中,unsupervised的DIAYN以及有一部分skill能够solve task了


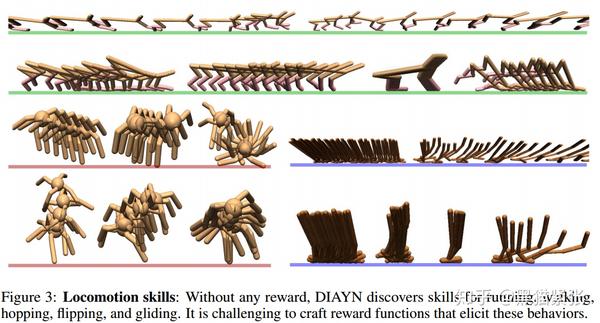
b. Figure 3 中表现了DIAYN在mujoco tasks中学习到的多种运动模式,例如向前跑,向后跑,扑倒等

c. 与相近的工作VIC的比较,也体现出,DIAYN保持z的prior 分布uniform所带来的更好的diversity
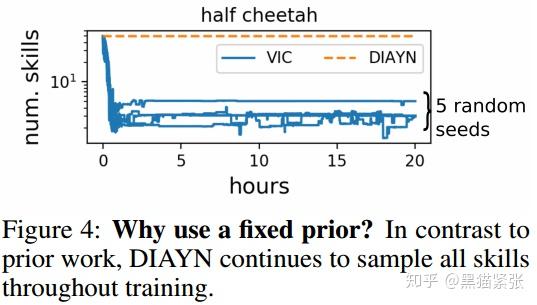

2)harnessing learned skills
a. policy initialization
对每个mujoco task选择reward 最高的skill作为policy 和value network的initialization,对比random initialization得到了更好的results


b. Hierarchical Reinforcement Learning
用DIAYN学到的skills作为HRL的low-level,用一个meta-controller训练high-level policy(HRL常规设定),在多个任务中,获得了很好的performance
这一点也正因为,DIAYN学到的skills是diverse的,且task-agnostic的,基于这些skill来train high-level policy 探索和优化都变容易进行,sparse reward和问题的复杂性,也因为被有效地约减






这里需要提到的一点是,DIAYN希望skill cover不同的state space,如果state dimension很高,skill很多,这样的HRL会不会无法进行。
作者这边给出的方案是,不一定需要condition 在原始的state space中,可以利用prior经验,以state的函数形式(或者compact representation)作为条件,Figure 7 Ant Navigation 中的DIAYN+prior就是condition在f(s),i.e.,ant的质心,而获得个good performance。
c. imitation learning
基于learned skills对expert policy进行imitation,假如给定一个state trajectory,
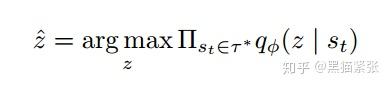
使用训练好的discriminator对最优可能生成这样的trajectory的skill进行esimate,然后返回control policy进行imitation
Figure 9 表明了这样的imitation成功模仿了4个expert中的3个


总结:
1)文章对mutual information的运用还挺impressive的,上一次接触mutual information还是Info-GAN,这一次加深了理解,考虑可以把mutual information用到合适的地方去
2)paper中的几个环境都很能够展示和验证方法的效果,尤其mujoco,skill与behavior的天然对应关系,十分合适作为实验环境。然而,对一般问题中 diverse skill的训练难度,和真正的效果,保留一定的疑问
