
目标检测20年

本文篇幅较长,如果觉得对您有帮助,欢迎关注我的专栏~
作为计算机视觉中的最基础也是最具有挑战性的任务,目标检测在过去的20年间获得了长足的发展,取得了显著的进步。本文不局限于一个方面的提升,而是站在宏观的角度看待目标检测。这篇由美国密歇根大学、北京航空航天大学、滴滴出行共同撰写的论文,引经据典,通过400+篇相关论文的引用,为我们勾勒出了目标检测从理论,架构,技术细节一直到应用落地,未来发展趋势等一系列的发展历程,对于志在学习目标检测的我们是很好的参考。
*原文的内容十分全面详尽,我在这里只是截取近几年主流的目标检测的相关内容,此外还结合自己的阅读,有所增减。如果想要了解更多,可以点击阅读原文。
1. INTRODUCTION
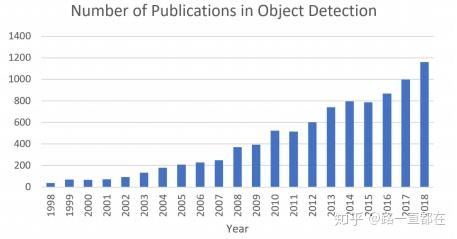
给定一张图片,告诉我目标的类别和位置。“What objects are where”,这是目标检测最朴素也是最本质的内容。同时,作为计算机视觉中的基础任务,目标检测为诸如目标跟踪,实例分割等任务提供了支撑。目标检测可以划分为两大范畴:一般目标检测("general object detection")和检测应用("detection application")。其中,一般目标检测的目的是探索在统一的框架下检测不同类型物体的方法,以模拟人类的视觉和认知,更偏理论。检测应用侧重于技术在现实生活的应用,比如行人检测,人脸检测等。近年来随着深度学习的爆发,越来越多目标检测的应用开始落地,自动驾驶,监控安防,机器视觉等取得了长足的进步,下图对比了20年来有关目标检测的文章发表量,可以清楚的看到,数量上的急剧上升。

2. OBJECT DETECTION IN 20 YEARS
在这一章节中,将会分别介绍目标检测的发展历程,经典算法网络,常用数据集等内容。
- A Road Map of Object Detection(发展历程)
如下图所示,以2014年为界,可以将目标检测的发展历程分为两大部分:传统目标检测时期,基于深度学习的目标检测时期。
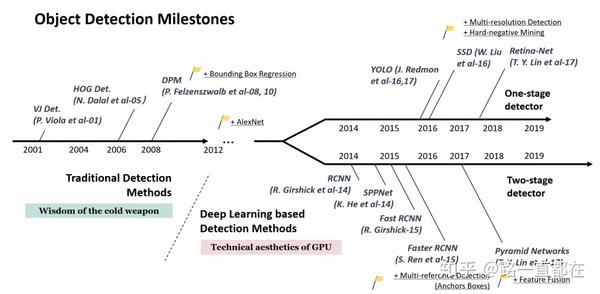

关于2014之前的传统方法就不过多赘述,主要介绍一下基于深度学习的目标检测方法。
(1) Faster R-CNN
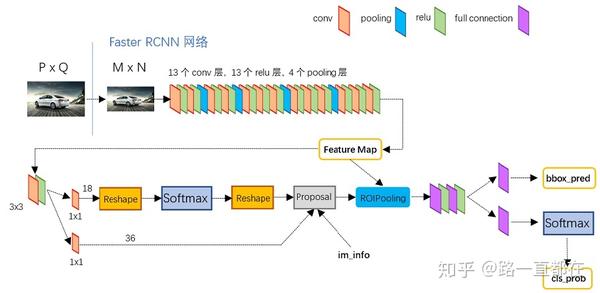
经历了R-CNN,Fast R-CNN的历练发展,2015年的Faster R-CNN给足了我们惊喜。Faster R-CNN是第一个端到端的训练,速度近乎达到的实时的检测器。在COCO数据集上mAP达到42.7%,在VOC12上mAP达到70.4%,速度有17fps。在结构上,Faster R-CNN创造性的引入了RPN(Region Proposal Networks),而在RPN中,引入了“anchor“的概念,彻底颠覆了之前SS等算法思想,大幅提升了性能,也为之后的算法提供了很有价值的借鉴。Faster R-CNN将区域提取,特征提取,bounding box回归等模块融合到一个端到端的统一框架中,十分有创新性和开创性。

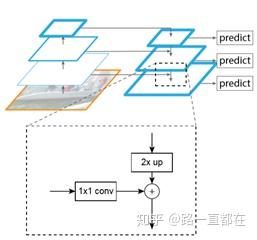
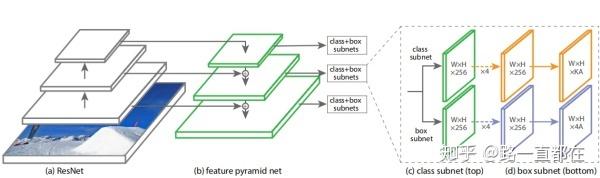
(2)FPN(Feature Pyramid Networks)
在Faster R-CNN的基础上,2017年,FPN网络出现。FPN也就是特征金字塔网络,又将目标检测向前推了一步。在FPN之前,大多数的目标检测网络利用特征的最后一层进行检测,层数增加对于分类任务来说是有益的,但是对于位置回归来说,却是一个阻碍。FPN通过上下通路和侧边连接,将分辨率信息和语义信息很好的结合。FPN的出现为各种尺度的目标检测提供了很好的保障,这也使得FPN成了很多目标检测网络的标配。
(3) YOLO(You Only Look Once)
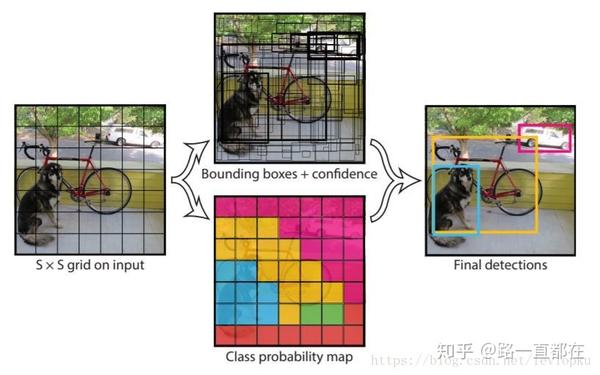
2015年可以说是目标检测的大年,除了Faster R-CNN横空出世,YOLO也是一股不可忽视的新力量。作为深度学习中第一个one-stage目标检测网络,YOLO的速度是及其快的,在VOC07上达到了155fps!随后的YOLO版本在显著提高了mAP的同时,速度也能达到45fps。YOLO是You Only Look Once的缩写,顾名思义,作者彻底抛弃了以前的区域提取+验证(proposal detection + verification)的两段模式,而是直接将图像分割成多个区域,同时预测每个区域的边界框和概率。其核心思想是:把一张原图划分为S*S个栅格(grid cell),其中每个cell有B个bounding box并且负责预测C个类别的概率。每个bounding box预测5个值(x,y,w,h,score),那么,总共的tensor为S*S*(B*5+C)。每个bounding box都对应一个confidence score,如果grid cell里面没有object,confidence就是0,如果有,则confidence score就等于预测的box和ground truth的IOU值,ground truth可简单的看做人工标注的图像区域。如何判断一个grid cell里面有没有包含object呢?判断方法是如果一个object的ground truth的中心点坐标在一个grid cell里面,那么这个grid cell就被认为包含这个object,即这个object的预测就由该grid cell负责,每个grid cell都预测C个概率,表示在一个grid cell包含object的条件下,该object属于某一个类别的概率,那么到底是grid cell中的哪一个bounding box负责预测呢?答案是找IOU最大的那个。而且,由于多尺度的引入,SSD在小目标检测上相比YOLO有很大的提升。
注意:bounding box的confidence与每个类别的score相乘,得到每个bounding box属于哪一类的confidence score,接下来的操作就是20个类别(假设有20类)轮流进行,将得分低于阈值的设置为0,然后按照得分进行排序,最后用NMS去掉重复率较高的bounding box。
这种设计模式必然提高了速度,但是这种原始的想法也降低了准确率,于是随后相继出现了v2,v3版本,通过加入BN层,引入anchor,加入ResNet等策略,在保证速度的同时大幅提升了准确率。YOLO的进步是有目共睹的,但是相比two-stage目标检测网络,精度还是稍有逊色,尤其是对小目标的检测,那么稍后的SSD网络就将注意力集中于此。

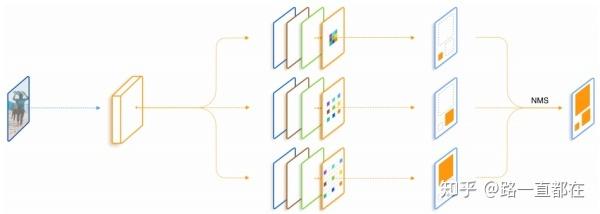
(4)SSD(Single Shot Multiple Detection )
SSD的提出时间比YOLO稍晚,因此针对于YOLO这种one-stage网络加以改进。SSD最主要的贡献在于引入了多目标检测。SSD核心设计理念可以总结为三点:
(1). 采用多尺度特征图用于检测
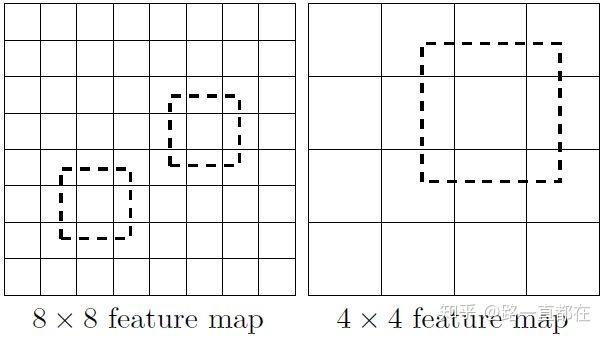
关于多尺度的理解:CNN网络前面的特征图一般比较大,后面会逐渐采用stride=2的卷积或者池化来降低特征图的大小,如下图所示,一个较大的特征图和一个较小的特征图,都是用来进行检测。这样的好处是比较大的特征图可以用来检测相对比较小的目标,因为较大的特征图可以划分为更多的小单元,每个小单元的先验框尺度比较小,正好用来检测小物体;而小的特征图负责检测大物体。

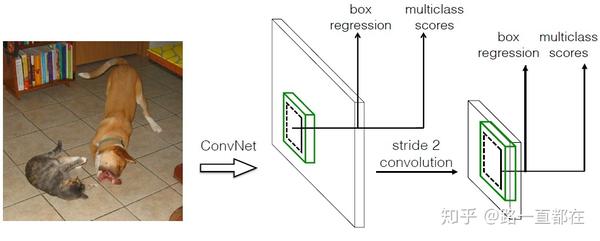
(2).采用卷积进行检测
与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图进行提取检测结果,对于形状为MxNxP的特征图,只需要采用3x3xp这样比较小的卷积核就能得到检测值
(3).设置先验框
SSD借鉴了Faster R-CNN中anchor的概念,每个单元设置尺度或者长宽比不同的先验框,预测的bounding-box就是以这些先验框为基准的。在下图中可以看到,每个单元使用了4个不同的先验框,图中的猫和狗分别采用了最适合它们形状的先验框进行训练,后面会讲到关于训练过程中的先验框匹配原则。
对于每个单元的先验框,SSD都输出一套独立的检测值,对应一个边界框,主要分为两部分:
(1)各个类别的置信度得分,注意的是SSD将背景作为特殊的一类,如果检测目标共有C个类别,SSD需要预测c+1个置信度得分,反之,如果SSD预测了c个置信度,其实物体的预测类别只有c-1。在预测过程中,置信度得分最高的类别作为该边界框所属的类别,特别的,当第一个置信度最高时,表示该边界框内没有目标,或者边界框内属于背景内容。
(2)边界框的位置信息,包含4个值,(cx,cy,w,h),分别表示边界框的中心坐标和宽高,其实真实值是相对于先验框的转换值或者偏移值。

在训练过程中首先确定训练图片中的ground truth与哪个先验框进行匹配,与之匹配的先验框的边界框就将负责预测。在YOLO中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框将负责预测它,而在SSD中则完全是新的模式,在SSD中的创新主要在两点:对于图中的每一个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样可以保证每一个ground truth一定有先验框与其匹配,一个图片中先验框很多但是ground truth比较有限,会造成负样本数量过多,导致正负样本不平衡,导致训练困难,因此加入第二条限制:对于剩余的未匹配的先验框,若某个ground truth 的IOU大于某个阈值(一般是0.5),那么该先验框也和这个ground truth相匹配,这样能够比较好的平衡正负样本的数量,注意第二个原则是在第一个原则的基础上进行的,
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(5)RetinaNet
长久以来,one-stage的精度都不如two-stage。在2017发表的Retina论文中,比较深入的讨论了造成这样的原因。作者认为,前景背景间的极度不平衡是罪魁祸首,在训练过程中存在太多的背景框,这些背景会主导训练,让训练轨迹“跑偏”。此外,还存在易区分和难区分样本的问题。因此,又一个重要的损失函数被提出,这就是focal loss。focal loss通过引入几个参数让训练重心专注于那些含有目标且难区分的样本上。focal loss的引入,让one-stage的精度和two-stage旗鼓相当。
关于RetinaNet的详细介绍,在我的专栏里有专门的文章,可跳转查看

(6)TridentNet
2019提出的TridentNet,注意到了目标检测中的尺度变化问题,通过实验,作者阐述了不同感受野的优势和不足,并设计了一个三叉戟网路,在基础目标检测器上,将常规卷积替换成空洞卷积,改变不同分支的感受野大小,将不同感受野的优势结合,扬长避短,不同尺度的目标送到不同分支进行训练,实现了性能的提升。
关于TridentNet的详细解读,可跳转查看

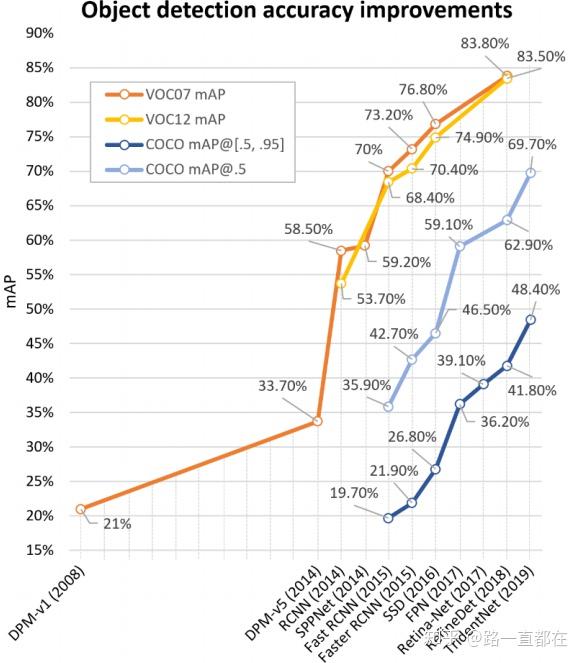
下图列出了几个代表性算法在VOC和COCO上的性能表现

- Object Detection Datasets(数据集)
构建一个图像更丰富,噪声越小的数据集,是提升目标检测性能的重要内容。在过去的10年间,有几个经典的数据集相继问世,之所以经典,一方面是因为数据集的质量过硬;另一方面,如果你的算法没有经过这些数据集的训练,测试,那么你的工作是没有说服力的。下面重点介绍PASCAL VOC,MS-COCO。
(1)PASCAL VOC
VOC数据集是计算机视觉领域最重要的数据集之一。在VOC上有很多任务,诸如图像分类,目标检测,语音分割等,最经典的VOC版本是VOC07(5K训练图像,12k目标标注信息)和VOC12(11k训练图像,27k目标标注信息)。VOC包含20类生活常见目标。


(2)MS-COCO
现在,MS-COCO是目标检测领域最具挑战性的数据集。MS-COCO-17包括164k图像,897K目标标注信息。共80个类别。与VOC相比,COCO数据集包含更多的类别,且小物体的数量更多,这使得COCO数据集更接近真实世界的场景。COCO已经成为了目标检测的标杆。
COCO在训练时,最重要的两个文件时放原图像的文件夹以及annotations下存放标注信息的json文件

下图是常见数据集的信息。


- Object Detection Metrics(度量标准)
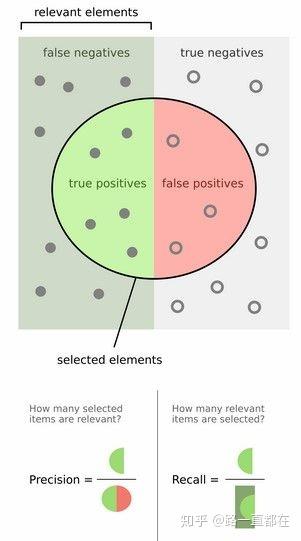
有了数据集进行训练和测试,那么,我们应该用哪几个指标进行度量目标检测器的好坏呢,在VOC2007上引入了“Average Precision”也就是我们论文中常见的AP概念,在介绍AP之前,先要理解两个概念,(查准率)Precison和(召回率)Recall。如下图所示,左半部分的矩形中的实心点是正样本,只不过有的被错误的判定为负样本(False negatives),有的被正确判定(true positives);右半部分矩形中的空心点为负样本,只不过有的被错误的判定为正样本(false positives),有的被正确判定(true negatives)。
那么查准率(Precision)的意义是在所有被判定为正例的样本中(不管判断正确与否),正确判定的正样本所占的比例。
召回率(Recall) 的意义是所有真正的正样本中,被正确判定出来的正样本所占的比例。
用公式可以表示为:


其中,TP(True positives),FP(False Positives),FN(False Negatives),TN(True Negatives)
理解了上面那些,就可以愉快的介绍AP,mAP啦
AP定义为不同召回情况下的平均检测精度,针对的对象是某一类。距离来看,如下图所示,绿色框代表GT bounding box,红色代表预测bounding box,每个预测框都有置信度,且规定若IOU大于0.3即被认为是正例


那么针对所有的bounding box信息,按照置信度排名,可以整理成一个表格,如下图所示:
以第一行为例,图片5中的R框,置信度为95%,且是TP,那么根据precision的计算公式,precision=1/(1+0)=1,Recall=1/15=0.0666,15是正样本绿框数量。所有的计算如此,得到下列表格。


然后以Recall为横轴,Precision为纵轴,就可以画出一条PR曲线如下所示:
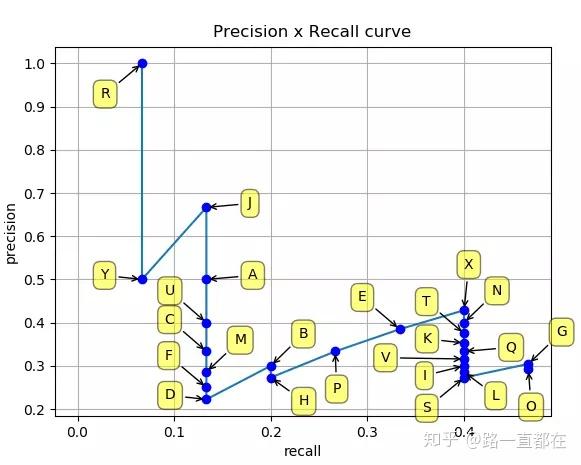

P-R曲线围成的面积就是AP,即:
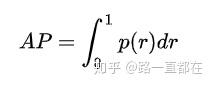
下图蓝色曲线为precision,为了让曲线更平滑,符合逻辑,采用一些小策略(对每一个precision点,取右侧最大值替代),变成了下图红色虚线
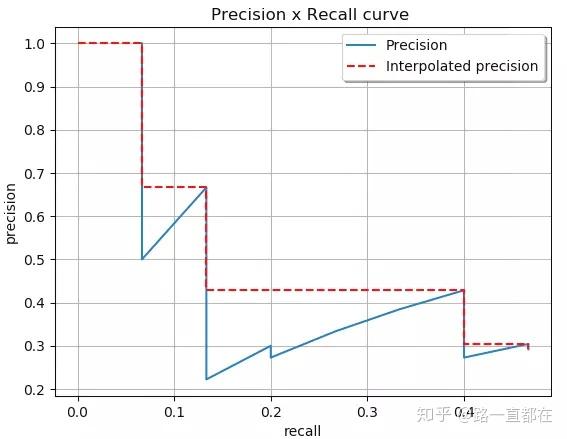

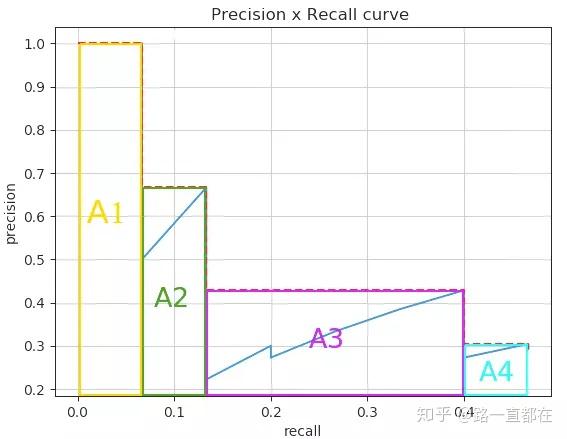
那么,最终AP的计算是算面积,如下图,将曲线划分为四块,进行面积计算再相加。



有了AP的概念之后,mAP就很简单啦,AP是针对某一类的,mAP是将所有类AP相加,然后除以类别数,即:

- Technical Evolution in Object Detection(相关技术)
(1)多尺度目标检测
不同尺寸、不同长宽比的多尺度目标检测是目标检测的主要技术挑战之一。如下图所示,多尺度检测的发展经历几个时期:特征金字塔和滑窗(feature pyramids and sliding windows),基于区域的目标检测(detection with object proposlas),多分辨率检测(multi-resolution detection)等。
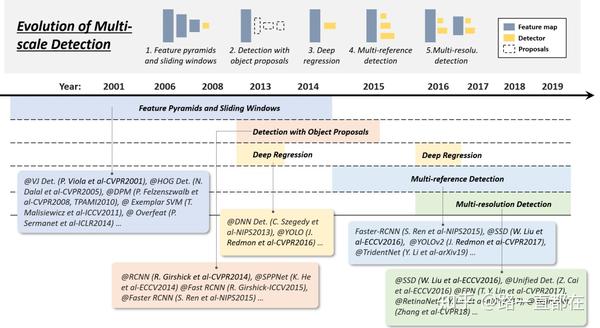

下面,着重介绍两个关于多尺度目标检测的算法:
Detection with object proposals
什么是object proposal?object proposal 指的是所有可能包含检测对象的候选框,这些框是类别无关的。这种方法的提出相比sliding window能够更高效,精确。一个object proposal算法必须满足以下几点:高召回率,高定位精度,高速度。
Multi-resolution detection
多参考检测,是主流的目标检测算法,主要算法思想是预定义一些尺度的参考框,最常用的就是anchor,这些参考框有不同的尺度和长宽比例,遍布整张图片的所有位置,然后基于这些参考框的预测结果,进行下一步检测框的预测。一个典型的损失函数设计包含两部分:基于交叉熵的分类损失函数和基于L1,L2或smooth L1的位置回归损失函数,可以用下列公式表示:
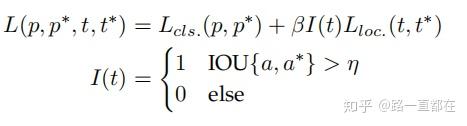

其中t和t分别代表预测bounding box和GT bounding box的位置,p和p是相对应的类别置信度,IOU{a,a*}是在anchor a和ground-truth a*之间计算IOU,η是对应阈值。如果一个anchor没有覆盖任何目标,那么这个anchor产生的loss不会回传。
多分辨率检测,是近两年来很受欢迎的目标检测算法,在网络不同层上进行不同尺度物体的检测,由于CNN在正向传播过程中自然形成了一个特征金字塔,所以更容易在较深的层中检测到较大的目标,在较浅的层中检测到较小的目标。
多参考和多分辨率是目前目标检测算法的主流方法。
(2)Bounding Box Regression
目标检测需要知道what和where的问题,因此,bounding box的回归对于目标的定位至关重要,回归的目标是根据候选区域 proposal或者anchor进行位置调整。
现在主流的回归损失函数是smooth L1,形式如下所示:
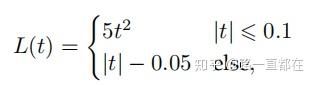
关于回归和损失的详细解释,我在专栏文章中有说明,在此附上链接,不再赘述
(3)Non-Maximum Suppression/soft-Non-Maximum Suppression
NMS非极大值抑制,是去掉冗余候选框的常用技巧。它的算法流程为
假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于某类的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
Soft-NMS,相比非极大值抑制,更加平缓,用稍低一点的分数来代替原有的分数,而不是直接置零。另外由于Soft NMS可以很方便地引入到object detection算法中,不需要重新训练原有的模型,因此这是该算法的一大优点。
(4) Hard Negative Mining
通常来说,目标检测在训练时会产生正负样本比例失衡的问题,当前的目标检测算法通常需要对候选框的长宽比,尺寸进行预设,这些都导致背景数量远远大于前景数量,如果继续利用产生的所有数据进行训练,那么整个训练过程都会被负样本主导,网络性能会很差,HNM(Hard Negative Mining)旨在解决训练过程中的样本失衡问题,在负样本的选择上不是all in,而是通过一定的选取策略,获得合适质量,数量的负样本,送入训练。
3. RECENT ADVANCES IN OBJECT DETECTION
(1)Detection With Better Backbones
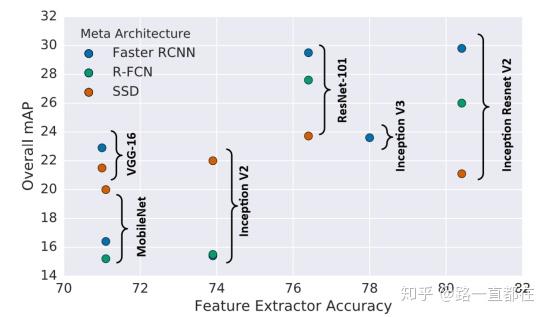
卷积网络在目标检测中发挥了重要作用,目标检测网络准确率的提升很大程度上依赖于前期的特征提取,也就是主干网络(backbone networks)。下图列举了在Faster R-CNN,R-FCN,SSD中,不同backbone的表现。

接下来介绍几种常见,经典的backbone:
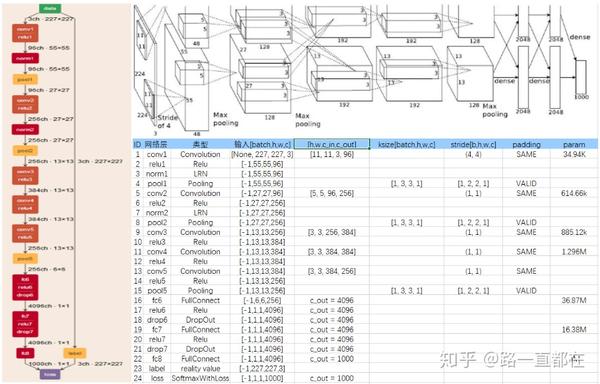
AlexNet
2012 ImageNet冠军,总体结构为5Conv+3Pool

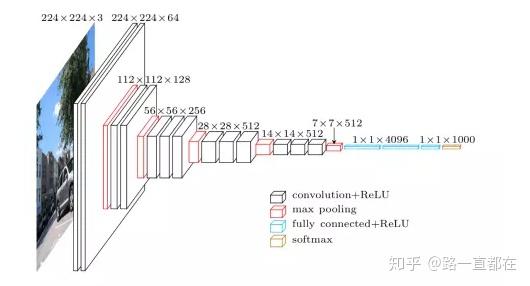
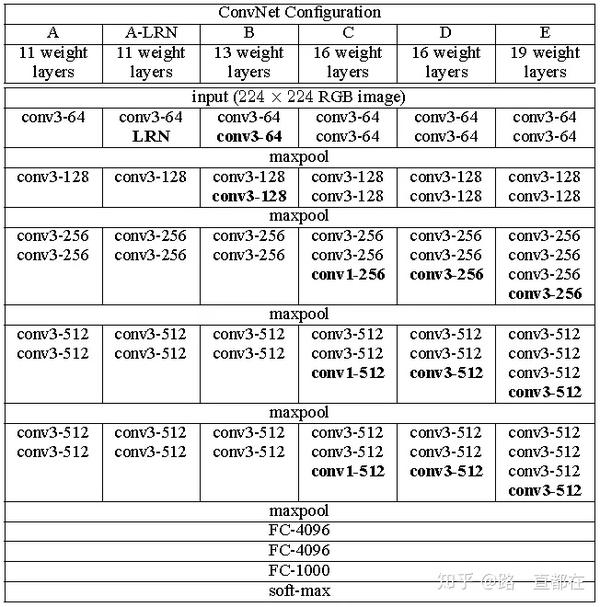
VGG
2014牛津大学团队提出,当年ImageNet竞赛的第二名。VGG加深了网络层数至16-19层,用3x3的小卷积代替了AlexNet中的5x5和7x7卷积。在有些卷积层中使用了1x1卷积


GoogLenet
2014谷歌团队提出,当年ImageNet竞赛冠军。在模型的深度(22层)和宽度上都进行了增加,此外还引入了BN


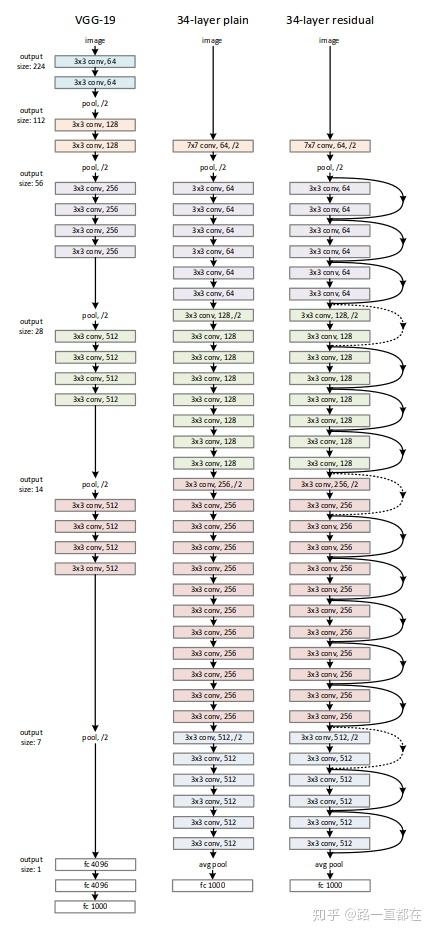
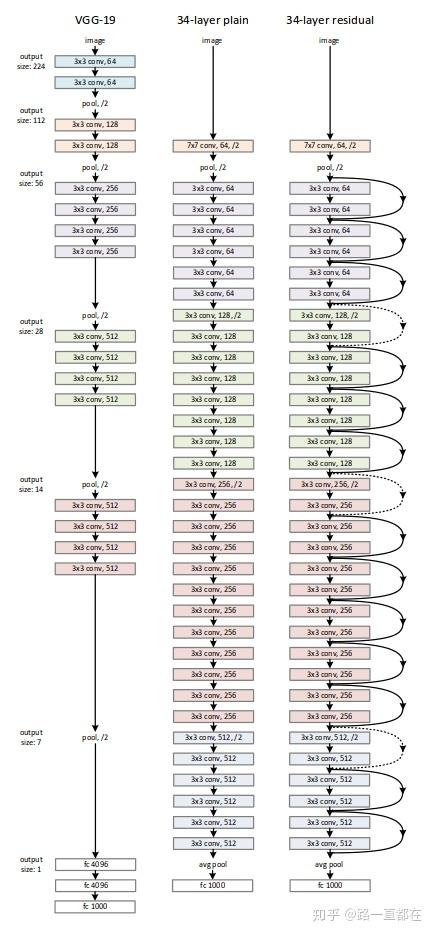
ResNet
2015残差网络横空出世,何恺明的大作。通过shortcut的设计,将模型的深度增加到152层,在2015的竞赛中,ResNet所向披靡,获得包括ImageNet detection, ImageNet localization,COCO detection, and COCO segmentation在内的多个冠军。
(2)Detection with Better Features
对目标检测而言,特征的提取质量至关重要,其中最重要的两点是:特征融合和如何学习高分辨率的特征和大的感受野。下面分别介绍一下:
特征融合
不变性和同变性(Invariance and equivariance)是图像特征表示中两个重要属性。一个目标检测器中,通常包括分类和定位两个子网,因此保持不变性和同变性对网络性能至关重要。分类任务需要不变的特征表示,因为它的目的是学习高级语义信息,图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的。而目标的定位需要的是同变性,也就是说当目标的位置发生变化时,输出的位置坐标也会发生相应变化。
卷积网络包含多层的卷积,池化操作,具有不变性,如下图所示,红色点代表的特征,在原图的左上角位置,在经过卷积,池化后,在特征图中仍然在左上方的位置。而如果红色点在原图中出现在左下角,那么经过卷积池化后,在特征图中也是出现在左下角位置。深层CNN这种很强的不变性对于分类是有好处的,但是却会损害目标定位的精度。相反,较浅层次的特征不利于学习语义,但它有助于对象定位,因为它包含更多关于边缘和轮廓的信息。因此,深层特征和浅层特征的融合就特别重要。
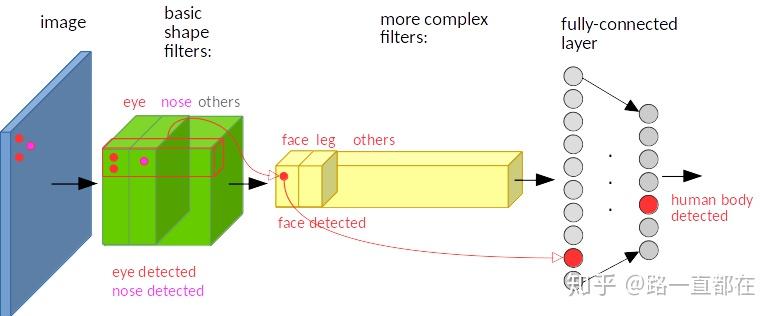

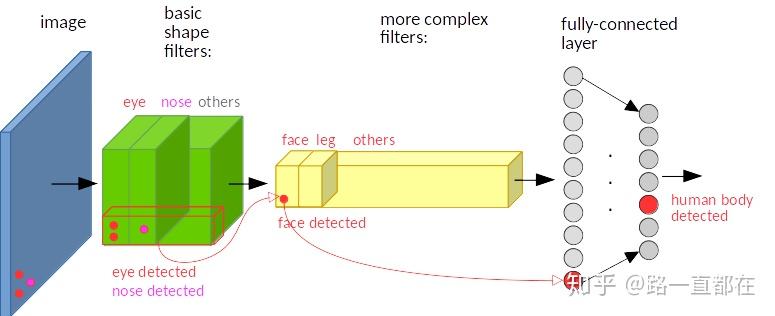

那么如何实现特征融合呢,主要有两个方面,流程创新和元素间的操作
Processing flow
目标检测中的特征融合方法可以划分为两大类:bottom-up fusion和top-down fusion。如下图所示,(a)为bottom-up fusion也就是从底向上的特征融合,通过引入跳转连接skip layers,将浅层的特性传递给更深层。(b)为top-down fusion也就是自顶向下的特征融合,自顶向下的融合将更深层次的特征反馈给更浅层次,然后多层输出预测结果。
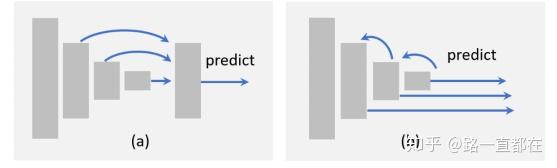

无论是(a)还是(b)的融合方式,不同层的尺度,维度都是必须要考虑的问题,我们可能需要调整feature map,比如调整通道的数量、上采样低分辨率映射或下采样高分辨率映射,使大小合适,其中最简单的方法就是双线性插值这些方法,当然,反卷积也是可以考虑的。本文不再展开讲。
Element-wise opration
从局部的角度看,特征融合可以看作是不同特征映射之间的元素操作。如下图所示,元素间的操作可以分为三类:元素加操作(element-wise sum),元素乘操作(element-wise product),张量拼接(concatenation)
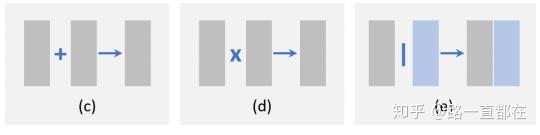

其中,(c)是对应元素相加,可以理解为特征融合和增强,应用比较广泛,(d)是对应元素相乘,与相加唯一的不同是将加法变为乘法,它可以用来抑制或突出某一区域的特征,这可能进一步有利于小目标检测。(e)是张量拼接,是完全不一样的套路,它的操作对象不再是元素之间,而是维度上的增加,拼接的优势在于集成不同区域的上下文信息,缺点是内存会显著增加。
高分辨率及感受野学习
特征分辨率和感受野是基于CNN的目标检测中两个重要特性。前者是指用于计算输出的单个像素的输入像素的空间范围,后者对应于输入与特征图之间的下采样率。具有较大感受野的网络能够捕获更大范围的上下文信息,而具有较小感受野的网络则可能更专注于局部细节。
我们知道,特征分辨率越低,对于小物体的检测越困难。一个最直接的办法就是通过移除池化层或者减少卷积的下采样率来提高特征分辨率,但是这样会使得感受野变小,换句话说,这样会让检测器的视野受到阻挡和限制,可能会错过一些大目标。还有一个同时增加感受野和特征分辨率的方法是空洞卷积(dilated convolution),空洞卷积,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(正常的 convolution 是 dilatation rate 1),从原图的角度。本质是改变在原图上的采样方式,当dalited-rate是1的时候,就是常规卷积的采样,当dalited-rate大于1,比如是2,那么相当于在原图上隔1个像素进行采样,这样,采样点的位置会发生变化,然后用新的采样点进行卷积操作,也是增加了感受野。
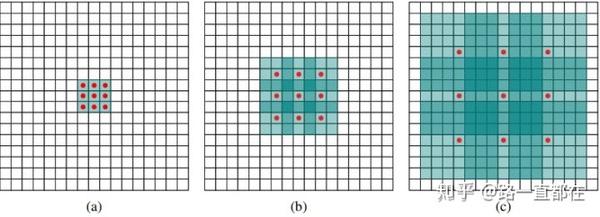

(3)Improvements of Localization
为了提升目标定位的准确性,主要从下列两方面入手:候选框bounding box的微调,新的损失函数的设计。下面来分别介绍:
Bounding Box Refinement
为了提升目标定位的精度,最直观的方法就是进行bounding box refinement,也就是对候选框进行微调,是对检测结果进行的后续处理。尽管位置回归已经成了当今目标检测算法的标配,但在实际项目中,仍然有些非常规尺寸的物体,即使有一些预设的anchor,也不能覆盖到,那么此时的候选框微调就十分必要。
Improving Loss Functions for Accurate Localization
在大多数目标检测中,目标定位被认为是一个坐标回归问题。然而这种模式有两个缺点:首先,回归的损失函数与评估结果并不对应,我们不能保证一个较低的回归误差总是会产生较高的IOU,特别是当目标具有非常大的纵横比时,其次,传统的bounding box回归方法不能提供定位的置信度。当多个候选框相互重叠时,可能会导致利用NMS失败。那么,在损失函数上是否可以进行创新设计呢?最直观的损失函数设计是用IOU进行衡量,还有一些方法从边界框的概率分布入手。
4 . 文章参考
关于目标检测,我附上几篇自己写的解读,如果您感兴趣,也可以去我的专栏主页查看
推荐歌曲啦,谭校长89演唱会的歌曲,变奏
