![内存分配[一] - 空闲链表和内存池](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
内存分配[一] - 空闲链表和内存池

一个内存分配方法的好坏,一是体现在分配的速度上,其重要性在内存容量较大时会显得尤其明显,二是体现在对内存这种有限资源的使用率上。如果空闲内存被分割成了许多无法利用的小内存块(也就是俗称的内存碎片),那么即便系统中空闲内存的总量还很多,也可能无法满足程序内存分配的需求。
本系列文章将由浅入深,介绍内存分配常见的几种实现方式及其各自的应用场景。
空闲链表(free list)
将内存中所有的空闲内存块通过链表的形式组织起来,就形成了最基础的free list。内存分配时,扫描free list的各个空闲内存块,从中找到一个大小满足要求的内存块,并将该内存块从free list中移除。内存释放时,释放的内存块被重新插入到free list中。
假设现在内存的使用情况是这样的:
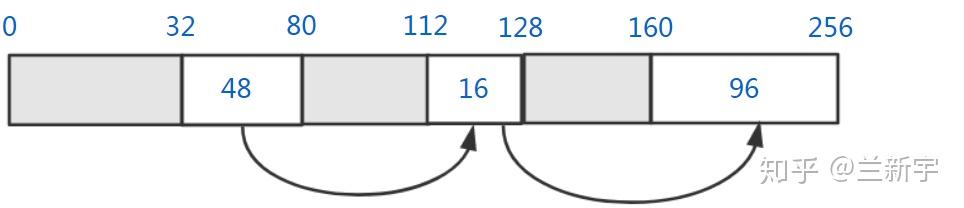

灰色部分代表已经被分配的内存块,白色部分代表空闲的内存块,大小分别是48字节,16字节和96字节。如果此时内存分配的申请是12个字节,那么将有几下三种策略可以选择:
- First fit(最先适配),就是从free list头部开始扫描,直到遇到第一个满足大小的空闲内存块,这里第一个48字节的内存块就可以满足要求。这种方法的优点是相对快一些,尤其是满足要求的空闲内存块位于链表前部的时候,但是在控制碎片数量上不是最优的。
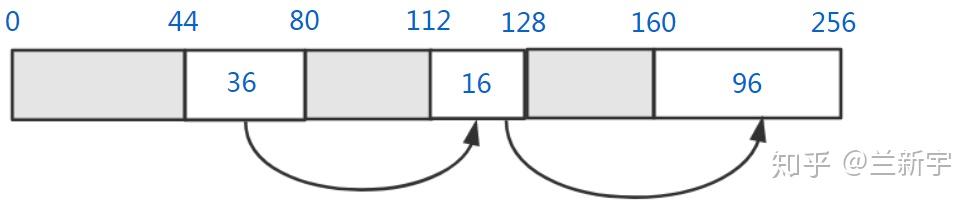

- Best fit(最佳适配),就是遍历free list的所有空闲内存块,从中找到和所申请的内存大小最接近的空闲内存块,这里第二个16字节的内存块是最接近12字节的。


- Worst fit(最差适配),也是遍历free list的所有空闲内存块,如果找不到大小刚好匹配的,就从最大的空闲内存块中分配。初看起来很反直觉是不是?但假设接下来的内存申请是64个字节,那只有worst fit的这种方法才能满足需求,所以其价值体现在:分配之后剩下的空闲内存块很可能仍然足够大。
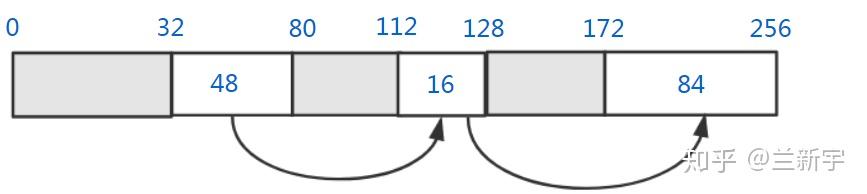

以上讨论的是内存分配的情况,接下来看看内存释放的操作是怎样的。假设从第80字节到第100字节中间的20字节内存被释放了,那么它将和前面相邻的空闲内存块合并:
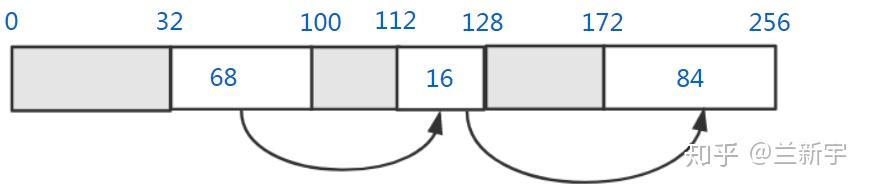

接下来从第100字节到第112字节中间的12字节内存也被释放了,那么它将同时和前后相邻的空闲内存块合并:
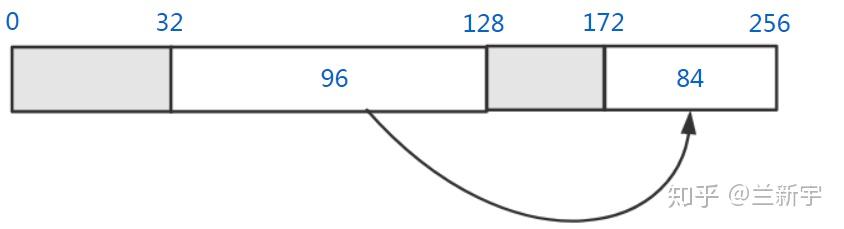

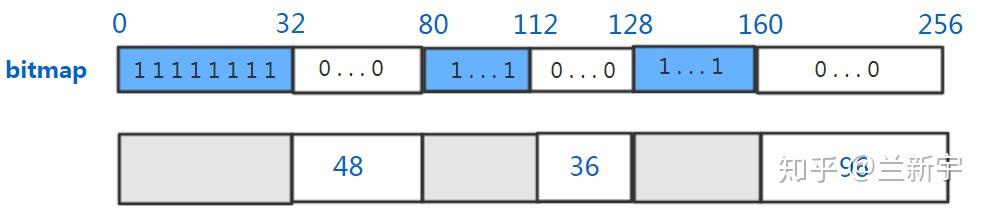
不过,既然用到了链表,那就需要指针,而指针本身也是要占用内存空间的。而且在内存释放时,要判断被释放的内存块前后的内存块是不是也是空闲的,这就需要每个内存块有一个空闲状态的标志位。可以采用的一种方式是bitmap,假设以4个字节为最小分配单位,那么每4字节需要一个bit,因此额外消耗的内存为1/32。

内存池(memory pool)
空闲链表的分配方式简单,但分配效率不高,运行一段时间后容易产生大量的内存碎片,从而恶化了内存利用率。
如果能将一大块内存分成多个小内存(称为内存池),不同的内存池又按照不同的「尺寸」分成大小相同的内存块(比如分别按照32, 64, 128……字节),同一内存池中的空闲内存块按照free list的方式连接。
每次分配的时候,选择和申请的的内存在「尺寸」上最接近的内存池,比如申请60字节的内存,就直接从单个内存块大小为64字节的内存池的free list上分配。


这样减少了free list链表的长度,能够缩短每次内存分配所需的线性搜索的时间,特别适合对实时性要求比较高的系统(比如RTOS)。但要想取得好的效果,需要结合系统实际的内存分配需求,对内存池的大小进行合理的划分。比如一个系统常用的是256字节以下的内存申请,那设置过多的256字节以上的内存池,就会造成内存资源的闲置和浪费。
似乎不是很好把控到底怎样划分内存池最为合适?下文将要介绍的Linux中的buddy分配系统,将基于普通的内存池进行优化,以更贴合大型操作系统对内存管理的需求。
参考:
https://en.wikipedia.org/wiki/Memory_pool
《深入理解UNIX系统内核》第12.3和12.4节
原创文章,转载请注明出处。
