为何Keras中的CNN是有问题的,如何修复它们?

在训练了 50 个 epoch 之后,本文作者惊讶地发现模型什么都没学到,于是开始深挖背后的问题,并最终从恺明大神论文中得到的知识解决了问题。
选自Medium,作者:Nathan Hubens,机器之心编译,参与:Nurhachu Null、张倩。
上个星期我做了一些实验,用了在 CIFAR10 数据集上训练的 VGG16。我需要从零开始训练模型,所以没有使用在 ImageNet 上预训练的版本。
我开始了 50 个 epoch 的训练,然后去喝了个咖啡,回来就看到了这些学习曲线:
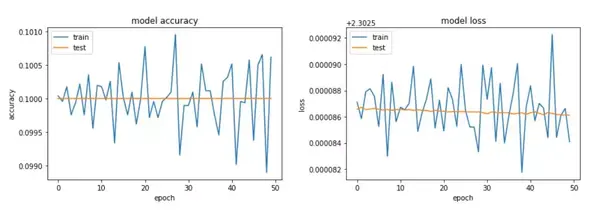

模型什么都没学到!
我见过网络收敛得极其缓慢、振荡、过拟合、发散,但这是我第一次发现这种行为——模型根本就没有起任何作用。
因此我就深挖了一下,看看究竟发生了什么。
实验
这是我创建模型的方法。它遵循了 VGG16 的原始结构,但是,大多数全连接层被移除了,所以只留下了相当多的卷积层。
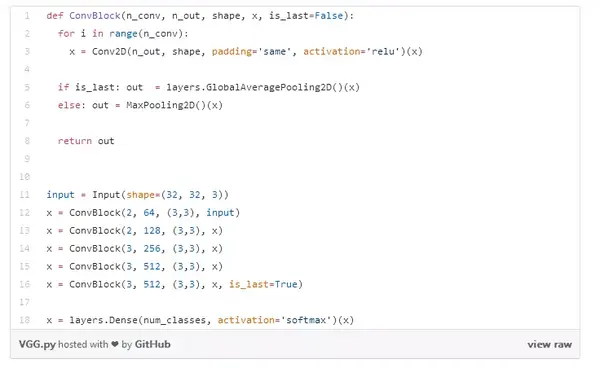

现在让我们了解一下是什么导致了我在文章开头展示的训练曲线。
学习模型过程中出现错误时,检查一下梯度的表现通常是一个好主意。我们可以使用下面的方法得到每层梯度的平均值和标准差:
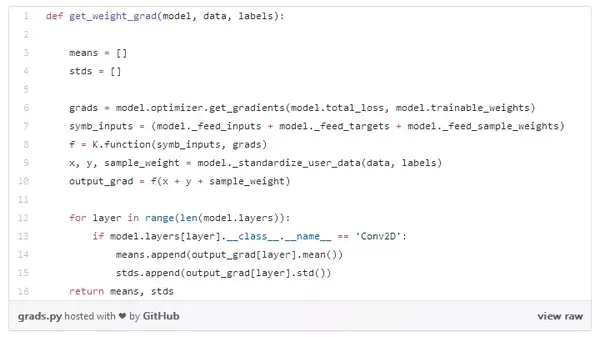

然后将它们画出来,我们就得到了以下内容:


呀... 我的模型中根本就没有梯度,或许应该检查一下激活值是如何逐层变化的。我们可以试用下面的方法得到激活值的平均值和标准差:


然后将它们画出来:
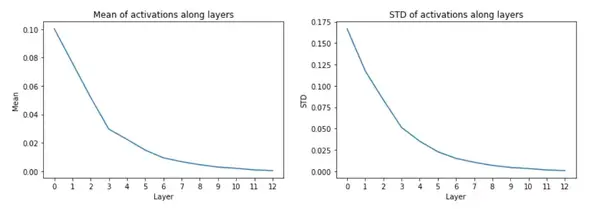

这就是问题所在!
提醒一下,每个卷积层的梯度是通过以下公式计算的:
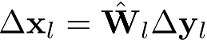
其中Δx 和Δy 用来表示梯度∂L/∂x 和∂L/∂y。梯度是通过反向传播算法和链式法则计算的,这意味着我们是从最后一层开始,反向传递到较浅的层。但当最后一层的激活值接近零时会发生什么呢?这正是我们面临的情况,梯度到处都是零,所以不能反向传播,导致网络什么都学不到。
由于我的网络是相当简约的:没有批归一化,没有 Dropout,没有数据增强,所以我猜问题可能来源于比较糟糕的初始化,因此我拜读了何恺明的论文——《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》
论文链接:https://arxiv.org/pdf/1502.01852.pdf
下面简要描述一下论文内容。
初始化方法
初始化始终是深度学习研究中的一个重要领域,尤其是结构和非线性经常变化的时候。实际上一个好的初始化是我们能够训练深度神经网络的原因。
以下是何恺明论文中的关键思想,他们展示了初始化应该具备的条件,以便使用 ReLU 激活函数正确初始化 CNN。这里会需要一些数学知识,但是不必担心,你只需抓住整体思路。
我们将一个卷积层 l 的输出写成下面的形式:
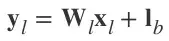
接下来,如果偏置值被初始化为 0,再假设权重 w 和元素 x 相互独立并且共享相同的分布,我们就得到了:
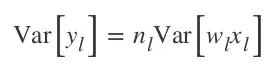
其中 n 是一层的权重数目(例如 n=k²c)。通过独立变量的乘积的方差公式:
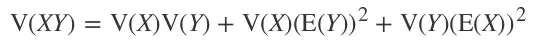

它变成了:
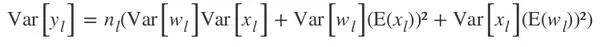

然后,如果我们让权重 w 的均值为 0,就会得到:
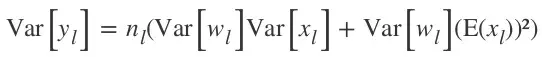

通过 König-Huygens 性质:
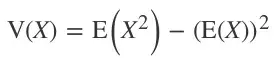
最终得到:

然而,由于我们使用的是 ReLU 激活函数,所以就有了:

因此:
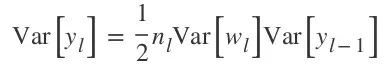
这就是一个单独卷积层的输出的方差,到那时如果我们想考虑所有层的情况,就必须将它们乘起来,这就得到了:
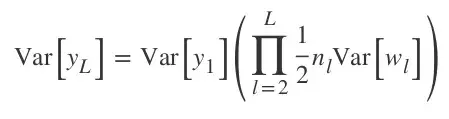

由于我们做了乘积,所以现在很容易看到如果每一层的方差不接近于 1,网络就会快速衰减。实际上,如果它比 1 小,就会快速地朝着零消散,如果比 1 大,激活的值就会急剧增长,甚至变成一个你的计算机都无法表示的数字(NaN)。因此,为了拥有表现良好的 ReLU CNN,下面的问题必须被重视:

作者比较了使用标准初始化(Xavier/Glorot)[2] 和使用它们自己的解初始化深度 CNN 时的情况:
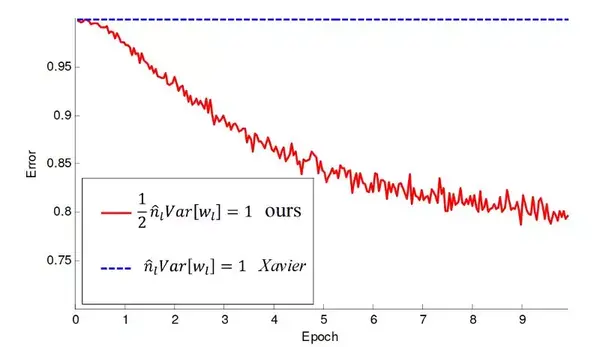

在一个 22 层的 ReLU CNN 上使用 Glorot(蓝色)初始化和 Kaiming 的初始化方法进行训练时的对比。使用 Glorot 初始化的模型没有学到任何东西。
这幅图是不是很熟悉?这就是我在文章开始向你们展示的图形!使用 Xavier/Glorot 初始化训练的网络没有学到任何东西。
现在猜一下 Keras 中默认的初始化是哪一种?
没错!在 Keras 中,卷积层默认是以 Glorot Uniform 分布进行初始化的:

所以如果我们将初始化方法改成 Kaiming Uniform 分布会怎么样呢?
使用 Kaiming 的初始化方法
现在来创建我们的 VGG16 模型,但是这次将初始化改成 he_uniform。
在训练模型之前,让我们来检查一下激活值和梯度。
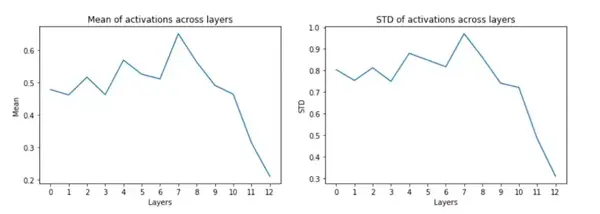

所以现在,使用 Kaiming 的初始化方法时,我们的激活拥有 0.5 左右的均值,以及 0.8 左右的标准差。
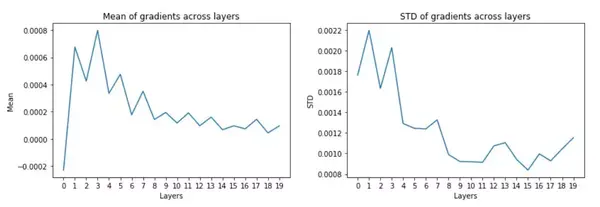

可以看到,现在我们有一些梯度,如果希望模型能够学到一些东西,这种梯度就是一种好现象了。
现在,如果我们训练一个新的模型,就会得到下面的学习曲线:


我们可能需要增加一些正则化,但是现在,哈哈,已经比之前好很多了,不是吗?
结论
在这篇文章中,我们证明,初始化是模型中特别重要的一件事情,这一点你可能经常忽略。此外,文章还证明,即便像 Keras 这种卓越的库中的默认设置,也不能想当然拿来就用。
参考文献和扩展阅读:
[1]: Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification:https://arxiv.org/pdf/1502.01852.pdf
[2]: Understanding the difficulty of training deep feedforward neural networks:http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[3]: 吴恩达课程:https://www.youtube.com/watch?v=s2coXdufOzE
原文地址:https://towardsdatascience.com/why-default-cnn-are-broken-in-keras-and-how-to-fix-them-ce295e5e5f2
