
科赛-公开新闻预测A股行业板块动向——亚军方案分享

瞬息万变的A股投资市场,牵绊着中国亿万家庭的万亿财富,而新闻信息则是影响股市走向的重要一环。数据爆炸的当下,每天产生的政治、军事、经济、科技等新闻浩如烟海,如何从杂乱无章的新闻中提取有效信息,进而梳理出对股市影响的清晰逻辑;如何更早更快地挖掘新闻的内在价值,进而高效地辅助机构投资研究;如何将微观变化连线洞察未来趋势,进而指导广大投资者合理资金配置…这都已成为国内外对新闻在证券领域应用的研究前沿。
本次任务旨在对公开新闻预测A股行业动向做探索性的研究,期望引领中国在该领域的关注和进一步发展。
大赛链接:
任务内容
要求开发者利用历史公开新闻数据,完成目标自然语言建模任务
- 公开新闻指和鲸提供的整理好的2014年至今历史新闻联播文本
- 预测目标:中国A股34个申万行业板块
- 预测内容:预测行业板块未来5个交易日收盘价涨的概率
由于本人是属于半道参加比赛,在没有完全弄清楚比赛日程情况下,我总共只有5次测评机会(初赛两次,复赛三次),在这五次机会中,可以说给我修改的机会不多,但不得不提醒大家的是,不要刻意加大模型深度和特征复杂度、不要刻意加大模型深度和特征复杂度、不要刻意加大模型深度和特征复杂度。
初赛和复赛的最大区别就是对模型和特征进行更进一步采集,但万万没想到的是,效果会变差。待会会展示。
一、数据分析
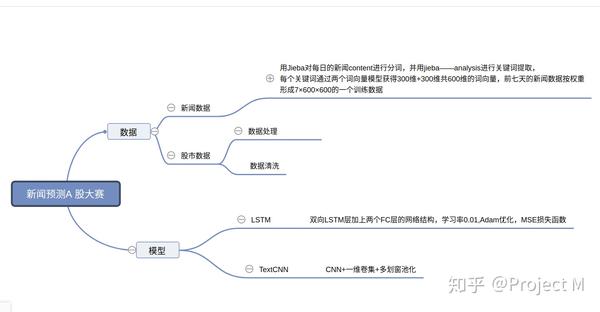

初赛和复赛的数据类型差不多,因为是股市相关预测,所以直接根据每天的实时数据来检验模型的好坏。
官方提供的数据截至到6月12日,后续需要通过官方方法拉取所需新闻信息和股市信息,根据我的经验,股市信息当天晚上7 点左右以后能够拉取,新闻信息则需要更晚的时候拉取。在前期测试中,拉取不到信息会报错,后面拉取不到信息不会报错 ,导致我几次拉了后保存的文件是空文件,疑惑了好久。 因为拉取的股市信息包含的股票数量比我们需要的多,所以我们只按照大赛需求的代码选取其中的部分信息保存 其涨跌的量需要转化为赛题本身的0(跌)或1(涨)两个数据,作为标签值 。
二、算法思路
整个方案分两条路-股市数据预测和新闻数据预测。最后将两个结果进行融合得到最终预测结果。经过我的观察,股市预测 的数据比较中庸,我选择双向LSTM。 最关键的是新闻数据的预测,本方案利用TextCNN作为网络框架。其最终额结果能够直接左右股市预测结果,使其按照新闻 数据的相关趋势进行涨跌量的预测。最终将二者结合起来,得出结果。 1、双向LSTM思路 核心就是用所有历史数据预测,反复迭代。 (1)数据处理 第一步:按照3,5,7,9的划窗宽度,获取简单的移动平均值,最大值,方差,标准差,最小值。 第二步:将新特征与原数据合并后,再处理,思路就是某日以前的数据集合,预测未来三天的股市涨的概率。
def get_new(demo_df,sta_idx):
base_cols = ['ts_code', 'trade_date', 'name'] cols = [col for col in market_train_df.columns if col not in base_cols] mini_total_df = pd.DataFrame() for i in tqdm(range(sta_idx,demo_df.shape[0])):
df = demo_df.loc[:i, cols]
mini_df = pd.DataFrame()
mini_df.loc[0,'target0'] =demo_df.loc[i, 'y']#未来一天的‘有
mini_df.loc[0,'target1'] =demo_df.loc[i+1, 'y']
mini_df.loc[0,'target2'] =demo_df.loc[i+2, 'y']
for col in cols:
mini_df[col+'mini_mean'] = df[col].mean()
mini_df[col+'mini_max'] = df[col].max()
mini_df[col+'mini_min'] = df[col].min()
mini_df[col+'mini_std'] = df[col].std()
mini_df[col+'mini_var'] = df[col].var()#20190601
mini_df[col+'mini_max_min'] = df[col].max()-df[col].min()
mini_total_df = pd.concat([mini_total_df,mini_df])
return mini_total_df`
改进后,增加了数据的傅里叶变换信号,可以对股市走势历史进行更深的信号采集
def get_new2(demo_df,sta_idx):
base_cols = ['ts_code', 'trade_date', 'name']
cols = [col for col in market_train_df.columns if col not in base_cols]
from tqdm import tqdm
mini_total_df = pd.DataFrame()
for i in tqdm(range(sta_idx,demo_df.shape[0])):
# for i in tqdm(range(0,demo_df.shape[0])):
df = demo_df.loc[:i, cols]
mini_df = pd.DataFrame()
mini_df.loc[0,'target0'] =demo_df.loc[i, 'y']
mini_df.loc[0,'target1'] =demo_df.loc[i+1, 'y']
mini_df.loc[0,'target2'] =demo_df.loc[i+2, 'y']
for col in cols:
xc = pd.Series(df[col].values)
zc = np.fft.fft(xc)
realFFT=np.real(zc)
imagFFT = np.imag(zc)
mini_df[col+'Rmean'] = realFFT.mean()
mini_df[col+ 'Rstd'] = realFFT.std()
mini_df[col+ 'Rmax'] = realFFT.max()
mini_df[col+ 'Rmin'] = realFFT.min()
mini_df[col+'Rmean_20'] = realFFT[-20:].mean()#第五轮新增
mini_df[col+ 'Rstd_20'] = realFFT[-20:].std()#第五轮新增
mini_df[col+ 'Rmax_20'] = realFFT[-20:].max()#第五轮新增
mini_df[col+ 'Rmin_20'] = realFFT[-20:].min()#第五轮新增
mini_df[col+'Imean'] = imagFFT.mean()
mini_df[col+ 'Istd'] = imagFFT.std()
mini_df[col+ 'Imax'] = imagFFT.max()
mini_df[col+ 'Imin'] = imagFFT.min()
mini_df[col+'Imean_20'] = imagFFT[-20:].mean()#第五轮新增
mini_df[col+ 'Istd_20'] = imagFFT[-20:].std()#第五轮新增
mini_df[col+ 'Imax_20'] = imagFFT[-20:].max()#第五轮新增
mini_df[col+ 'Imin_20'] = imagFFT[-20:].min()
mini_df[col+'mini_mean'] = df[col].mean()
mini_df[col+'mini_max'] = df[col].max()
mini_df[col+'mini_min'] = df[col].min()
mini_df[col+'mini_std'] = df[col].std()
mini_df[col+'mini_var'] = df[col].var()#20190601
mini_df[col+'mini_max_min'] = df[col].max()-df[col].min()
mini_total_df = pd.concat([mini_total_df,mini_df])
return mini_total_df
`
(2)网络搭建
基于Pytorch搭建一个双向LSTM层加上两个FC层的网络结构,学习率0.01,Adam优化,MSE损失函数。100次迭代,每
次迭代遍历34只股票代码的特征数据。最后利用所有数据对每个代码的未来三天进行预测,将各自的预测概率进行融合
得出各支股票的每日概率。
2、TextCNN思路
(1)数据处理
`
def content_to_words(content,double):
r1 = u'[a-zA-Z0-9’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~]+'
all_word=[]#所有关键词
for sentence in content:
sentence_word=[]
try:
sentence=re.sub(r1, '',sentence)#清洗句子
# words = jieba.cut_for_search(sentence)
words =jieba.analyse.extract_tags(sentence, topK=-1, withWeight=False)#每个句子提取关键词
all_word.extend(word for word in words if word not in stopwords)
except:
continue
counter = Counter(all_word)#词频
if double:
count_pair1 = counter.most_common(len(all_word))#所有词语
count_pair2 = counter.most_common(599)#前599个词语
else:
count_pair = counter.most_common(300)#如果只有一个模型可考虑这个
return all_word,count_pair1,count_pair2
`
用Jieba对每日的新闻content进行分词,并用jieba—analysis进行关键词提取,每个关键词通过两个词向量模型获得
300维+300维共600维的词向量(我用了人民日报词向量和维基百科词向量模型,由于只允许搭载三个文件,不然可以试试
更多的词向量模型),每日新闻我们提取前599个关键词形成599x600的词向量矩阵,再把所有关键词的词向量进行融合为
一个600维的词向量,与前者融合就形成了600×600维的词向量矩阵,前七天的新闻数据按权重形成7×600×600的一个训练
label就是未来三天个代码数据的'y'组成的102维数据。
(2)网络搭建
`
class TextCNN(BasicModule):
def __init__(self, vectors=None):
super(TextCNN, self).__init__()
embedding_dim = 7,
kernel_num = 1024,
kernel_size =7
linear_hidden_size =512
convs = [
nn.Sequential(
nn.Conv1d(in_channels=600,
out_channels=1024,
kernel_size=7),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True),
nn.Conv1d(in_channels=1024,
out_channels=1024,
kernel_size=7),
nn.BatchNorm1d(1024),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=(600 - 7*k + 2))
)
for k in kernal_sizes#池化层划窗
]
self.convs = nn.ModuleList(convs)
self.fc = nn.Sequential(
nn.Linear( 5120, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Linear(512,102)
)
def forward(self, inputs):
conv_out = [conv(inputs) for conv in self.convs]
conv_out = torch.cat(conv_out, dim=1)
flatten = conv_out.view(conv_out.size(0), -1)
logits = self.fc(flatten)
logits = torch.sum(logits, 0, True)#多个预测值合并
return logits
`
网络结构采取textcnn的基本结构,主要是在最后一层池化的范围有所增加,理论上扩大了每个节点的感知域,这一点
让预测结果效果更加明显。模型训练好后,需要用前7天的数据对未来三天进行预测,将概率直接与股市数据预测值进行融合。得出最终
结果。``