
小鹏专业课 | 当我们谈论机器学习的时候我们在谈论什么?(一)

嗨,大家好,在接下来的几个月时间里,我们邀请到了知乎的用户Elims为我们带来一系列关于“机器学习”这个主题的专业内容,敬请大家期待:
整个系列大概会有六篇文章,他们分别是:
第一篇:介绍-当我们谈论机器学习的时候我们在谈论什么?(也就是今天这篇)
第二篇:应用-你看不到的机器学习
第三篇:挑战-好吧,机器学习不过如此
第四篇:学习-从被动学习到主动学习
第五篇:技巧-深度学习的昨天,今天,明天
第六篇:总结-你可能不知道,AI有17种门派
OK,我们开始吧!
机器学习是如今科技领域最酷的仔,你打车路上可能都会跟司机侃几句。
但你真的了解机器学习吗?我们为什么需要机器学习?它除了各种牛逼外有哪些局限?这个圈子里最新的方向是什么?
本文将从这几个方面告诉你,当我们谈论机器学习的时候到底在谈论什么。
* 机器学习是什么
机器学习作为人工智能领域的一个分支,本质上是一类基于数据自动建立分析模型(analytical model)的方法。其核心思想在于,系统通过数学模型从数据里学习有用的信息并存储在模型参数里,进而完成某些预设的任务,例如模式识别、数值预测、分类,等等。如下图,机器学习系统主要分为三个阶段:
一是数据预处理,亦即对收集的数据进行清洗、降维、扩充,等等;
二是模型训练,通常需要人工设计、优化算法模型(然而此步骤近年也有由算法代劳的趋势,亦即用机器学习算法训练机器学习算法,例如Auto-ML,Meta-Learning);
三是应用,把训练好的模型部署到目标任务场景里,在新数据上完成预期任务。


机器学习的诞生源于对机器智能性的探索:机器是否可以自动从以往经验里学到东西。”学到东西”的判断标准是,当输入新的数据时,机器是否仍能有效处理并稳定地完成预期的任务。很长一段时间,由于可用数据量较小,计算机算力不够,导致机器学习的实际应用场景有限。而近二十年来,伴随传感器、通信、芯片等行业的巨大发展,收集、存储、处理海量数据成为可能,机器学习(尤其是深度学习)的研究和应用也迎来爆发式的增长。在学术领域,以机器学习顶级会议之一International Conference on Machine Learning(ICML)为例,过去十年论文投稿量翻了5倍[1]。在工业领域,小到x宝剁手推荐,银行机器人客服,大到自动驾驶,寻找系外行星,机器学习随处可见。
我们都知道机器学习性能依赖大量数据。
然而除此之外,数据的质量也同样重要。好数据不是万能的,没有好数据是万万不能的。俗话说“Junk in, junk out”,如果喂给机器学习系统质量很差的数据,那么得到的模型性能也不会太好。很多不熟悉机器学习的人对其抱有过高的期待,大多是没有意识到,要充分发挥一个机器学习算法的能力,必须先收集足够多的数据并做精细的挑选和处理。这种对数据质量的依赖关系延伸出许多超出机器学习算法本身的问题,例如训练数据可能存在的不平衡性导致系统形成偏见(system bias),或者训练好的模型被要求适应不同的应用场景(transfer learning),等等。

机器学习算法主要分三大类:监督学习,非监督学习,以及半监督学习。
监督学习指算法使用的数据是被标注的,每个输入对应了一个正确的输出。算法通过比较自己的输出值和正确的输出值之间的误差来进行自我迭代,从而使输出达到一定精度。非监督学习所使用的数据是没有标注的,每一个输入没有一个预先设定的所谓正确的输出。这种算法一般通过挖掘数据自身的结构特征提取有用的信息。而半监督学习,则是利用部分标注的数据来训练机器学习算法。通常应对难以取得大量标注数据的情况。其中有一个分支,增强学习(reinforcement learning),近年大热。它在人工智能领域有很好的应用前景。针对具体问题,使用的机器学习算法往往是不同的。这里有一个流程图可以引导你根据需求选择合适的算法:Which machine learning algorithm should I use?[3]。
* 我们为什么需要机器学习
首先,机器学习解决了传统算法的痛点。
后者解决问题的思路是:定义问题,设立有限条数学规则,按步骤执行。然而对于很多现实场景,例如机器视觉或者自然语义处理,我们无法定义出有限且有效的规则。
不妨来想象一下,你需要一个检测人脸的算法,要制定怎样的规则才能准确检测姿态、肤色、大小各异的脸呢?如果我们进一步,要求检测艺术作品里风格多样到夸张的脸呢?甚至再进一步,如何用算法生成一张以假乱真的脸?
传统算法面对这些复杂、多样、开放的问题表现乏力,而机器学习可以做的很好。
例如下方上图真实的人脸检测,和下图计算机生成的人脸(是的你没看错,就是这么清晰且逼真,但仔细看仍会有一些瑕疵,例如第一行中间孩子头发上墨镜的一角)。

通过从数据里隐性地学习特征和规则,机器学习成功延拓了传统算法能力的边界。


从更深层的意义上来说,机器学习大大提高了生产力。
在商业领域,根据2016年MIT Sloan Management Review的报道[4],大数据加机器学习可以帮助企业更好地了解用户行为与偏好(这就是所谓的比你妈还了解你),从而优化销售策略和渠道。其调查的168家年销售额超5亿美金的公司里,76%通过机器学习算法提高了销售额,50%正在用机器学习解决市场推广问题。


在服务业,面向个人或企业的机器人助理已不稀奇。如果你跟我一样觉得在手机上打字费劲且浪费时间,那该了解一下今年5月Google在I/O大会上推出的新一代手机语音助理。它能更高效地响应用户的语音指令。不用动一根手指,你就可以查航班,查天气,回消息,或者发图片。在企业级别,不论是对外的智能客服(例如电商的在线机器人客服),还是对内的行政助理(例如来也科技的吾来),规模化的智能助理节省的人力成本更为可观。

另外,不得不提一下现在人工智能界最火热的话题:自动驾驶。
我们希望有更安全、更便捷的出行方式。没有加塞、酒驾、疲劳驾驶,也没有堵在四环两小时。即便我们对未来交通系统悲观一点,堵在四环的情况依然会发生,那自动驾驶汽车也能解放你的双手双脚,让你看电影玩游戏或者跟老板视频会议。目前落地的主要是L2-L3级别的自动驾驶(例如特斯拉的autopilot,小鹏汽车的xpilot),包括自主跟车,车道居中,自主变道,自动泊车等等。除了解放每个人的通勤时间,自动驾驶还可以大大提高物流运输效率。人类需要休息,机器不用。一些初创公司如图森未来、西井科技已经落地高速路和港口的自动驾驶物流系统。


类似借助机器学习用更少的钱办了更多的事的例子不一而足。从农耕文明,蒸汽文明,电气文明,直到今天的信息文明,推动人类社会进步的核心动力在于生产力的不断提高。这是不可逆的变革。机器学习已经成为这个时代提高生产力最重要的工具的之一。我们需要它,并不断把它范式化,以至于未来会像空气一样存在于我们身边。
* 机器学习的局限
所有硬币都有两面。机器学习牛逼的背后有其内禀的局限。广泛应用的同时也引起了社会伦理方面的担忧。
局限之一是系统性偏见。
我们希望机器学习系统给出的判断是客观的,然而理论上,目前的系统多少都存在偏见。
我们可以几乎保证模型是结构性中立,但无法保证数据也是如此。就像一个毫无主观能动性的孩子,如果喂给他的数据是不完整不真实的,那他形成的三观也必然是倾向性很强甚至错误的。比如我们只告诉他豆花是咸的,粽子是甜的,那他永远不会理解另一半中国人的心头好。在某些领域,这种判断上的偏见会带来更恶劣的影响。2016年微软曾经用推特上的数据训练了一个聊天机器人,结果其种族歧视主义极为严重,一边说“人类特别酷”,一边赞扬希特勒,或者表达对妇女的歧视[5]。
为缓解系统偏见,我们希望收集更完整的数据,但这直接带来了数据隐私问题。当我们安装APP,在不得不同意的权限上打勾,或者在社交平台上分享私人信息的时候,你知道你的信息会被怎样使用吗?恐怕极少有人真正去读又臭又长的隐私协议。2018年5月25日起欧盟区开始执行号称史上最严格的数据保护规则GDPR以确保医疗、金融、互联网等各行业数据收集使用的安全性和透明性。一年内GDPR已经启动超过20万起调查,开出5600万欧元的罚款(其中5000万欧元都是面向Google)[6]。而身处AI风暴中心的三藩市(San Francisco)也在今年5月正式立法禁止警察和其他政府机关在监控里使用人脸识别工具,因为“有可能加剧种族歧视和人权侵犯”[7]。
局限之二是解释性有限。
前文提到机器学习不同于基于规则的传统算法,而是从数据里抽象出特征。其结果通常是,我们无法用足够科学且便于理解的逻辑解释清楚为什么模型做出这样或那样的判断。深度学习便是典型的例子。就像脑科学家无法完全解释人类大脑神经元如何产生意识,我们也无法严谨地说明深度神经网络究竟是怎样工作的。在做牵扯到重大利益甚至生命安全的决策时(例如,银行金融模型判断是否该投资以及投资力度,自动驾驶汽车判断前方是否有障碍是否该刹车),我们希望模型不仅是黑盒,而是至少在某些关键点明确地展示出推理过程和判断依据,否则难以向别人说明这个模型和它做出的判断是靠谱的。
然而,即便能够说明一个机器学习算法如何工作,依然有可能遭遇道德或者法律上的争议。例如,一辆行驶中的自动驾驶汽车突然检测到前方有过马路的行人,神经网络瞬间对情况做出了可靠的判断并给出仅有的两个选择:要么紧急转弯导致车身翻滚司机受伤,但行人安然无恙;要么紧急刹车,司机没事,但势必会碰撞行人。系统该如何选择?谁又该为这个选择负责(自动驾驶系统供应商,车厂,还是司机)?再比如,即便机器学习本身技术中立,但仍可能被用于违法的勾当。例如网上曾盛传一段美国前总统奥巴马咒骂特朗普的视频——实际上完全是用神经网络生成的,以假乱真。而近期更有甚者公开提供软件,用神经网络“脱掉”任何照片里女性的衣服。技术无好无坏,可惜人心不是。每个人都有监督机器学习合理合法性的义务。毕竟每天我们都在提供着数据,并承受新技术带来的影响,没有人可以做局外人。
局限之三是安全性隐患。
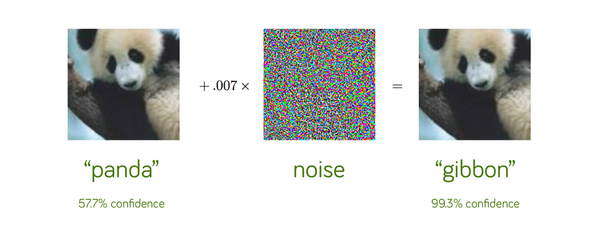
尤其是几十年来最强大的机器学习算法——深度神经网络(DNN)而言。2014年Google和纽约大学的研究人员发现,看似表现良好的DNN很容易被仔细设计但极其微弱的噪声所误导[8]。
例如DNN认为下图左侧图片有57.7%的概率是熊猫,但是加入了一点人为设计的噪声以后(下图中间雪花图,为了视觉上方便画的很明显,但实际极弱),即便肉眼看起来图片毫无变化,在DNN眼里却变成99.3%概率的长臂猿(下图最右)。
这种鲁棒性的缺失带来的是黑客攻击的空间。

另一个更直观的例子是,2017年的一个研究发现,只要在图片中加入一个精心设计的图案(adversarial patch)就可以完全误导DNN把任何图片分类成一个固定的类别 [9]。
例如下图第一行,DNN确信这是一个香蕉。然而在画面中加入一个看起来十分古怪的adversarial patch后,香蕉就被当成了烤面包机。
可以想象一下,如果用类似的方法攻击一个人脸识别门禁系统:不管站在摄像头前的人是谁,都可以通过在相机视野内加入合适的adversarial patch从而让系统误认为是授权的访客。
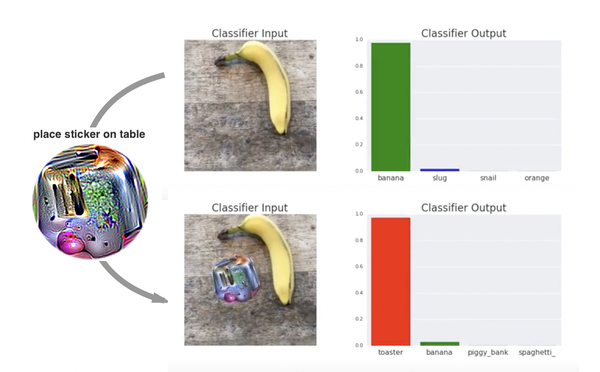

这些研究揭示了DNN的阿喀琉斯之踵。
目前主要有两类预防方法,一种是在训练模型时尽可能加入足够多的攻击性样本(adversarial samples),让网络能够辨识哪些是正常的样本,哪些是疑似攻击性样本,从而提高模型鲁棒性;另一种是借助图像压缩算法,利用网络自身从数据里抽象出的知识提高它对外来攻击的抵抗力。
* 机器学习的研究方向
机器学习有无数激动人心的应用方向,例如3D重建,场景理解,生成模型,等等。但这里我们希望讨论一些更深层的理论上的研究方向。他们有希望塑造机器学习的未来。
首先是元学习(Meta-Learning):
它是一类数据驱动的在不同任务间“学习如何学习(learn to learn)”的算法。近年广泛讨论的迁移学习(transfer learning)和少数学习(few-shot learning)都属于特殊类型的元学习算法。传统机器学习模型(learner)虽然可以从大量数据里学习,但其结果一般不具备迁移能力,学习的过程和结果受限于预设的场景。
例如,用一百万张照片训练的人脸识别系统并不能轻易地转化到自动驾驶汽车上识别红绿灯:我们很可能需要各种修改网络架构,在大量红绿灯数据上重新训练部分或者完整的模型,同时进行人为的参数调优。而元学习的目标是用一个更高层次的模型(meta-learner)学习“如何学习”这件事情:基于以往的学习经验(可以是已经训练过的数据,模型,或参数,不论他们是否来自同一场景或同一功能)快速、低成本地学会新任务。
本质上来说,这种模式更接近人类学习的方式:总结经验+能力迁移。俗称“长记性”。
举个栗子,我们已各有一个人脸识别模型,车牌识别模型和发动机故障检测模型,想做一个自动驾驶车外感知系统(能识别人、车、物、路)。相比于从零开始,我们更希望用上已有的这些模型和数据。元学习的一种思路是,在已有的所有训练数据、模型架构、参数、训练方法、测试结果上预训练出一个能依据场景自动预测最合适的模型结构、参数、训练方式的meta learner,从而大大加速新场景下模型优化的过程[10]。
其次是增强学习(Reinforcement Learning):
这是一种半监督式机器学习算法,研究的是模型在某种既定环境里通过不断探索、试错努力让利益最大化的过程。下图是一种最简单的增强学习算法Q-learning。它体现了增强学习的主要思想:首先初始化一个模型,观察当下的状态,然后采取某种行动,观察行动带来的结果和新的状态,记录行动和状态的历史信息,以最大化累计收益为目标采取新的行动,不断重复。
在这个过程中,通过不断的试错,模型总结出一套最优的行动方案。
著名的应用案例有DeepMind的AlphaGo击败李世石和柯洁,以及OpenAI击败职业Dota2玩家。增强学习所强调的半监督式的探索和从经验里学习的过程被认为是实现通用人工智能(Artificial General Intelligence)的重要基石。这种思想早在几十年前就被提出,但是在计算资源有限、数据匮乏的过去几乎没有用武之地。由于近年深度神经网络的引入,硬件和数据环境的发展,增强学习已经成为机器学习、博弈论、控制理论等等领域最火热的话题之一。


深度学习三巨头之一,2018年图灵奖得主Yoshua Bengio今年6月接受Synced采访时表示,2019年机器学习最重要的趋势之一是从模型被动学习转向主动。
不过他这里所强调的“主动”并不是指增强学习,而是我最后即将介绍的主动学习(active learning)。(采访原文:I see a move from passive machine learning, where the learner gets a big dataset and trains; to active machine learning, where the learner interacts with its environment. It’s not just reinforcement learning. It is active learning, things like dialogue systems where the interaction allows the learner to improve and to seek information.[11])
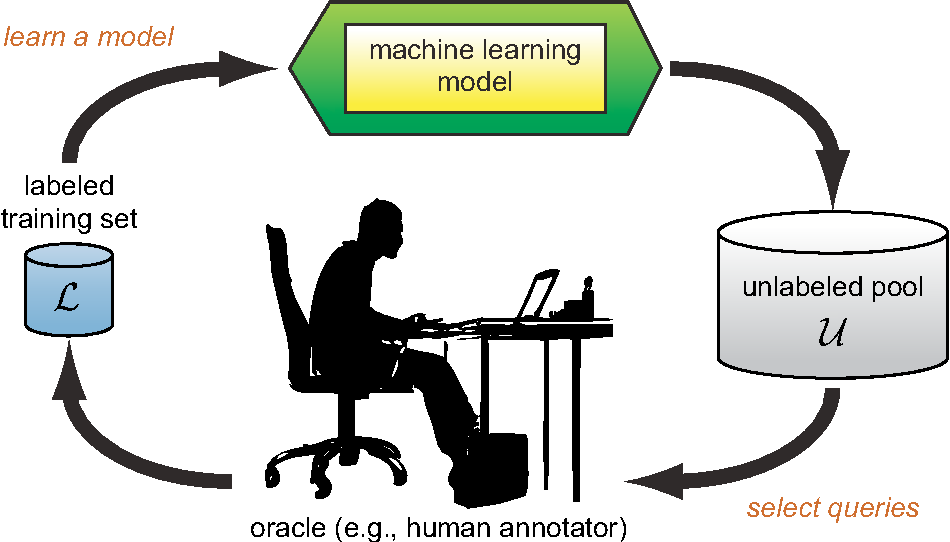
主动学习是一种高效低成本的训练监督式机器学习模型的框架(如下图)。
传统的方法(被动学习)需要大量时间金钱去标注训练数据(实际上这种需求大到孕育了整个数据标注产业)。
然而在主动学习的框架里,模型能够在无监督的情况下自己挑选“最有价值”的数据去标注,从而用尽可能少的标注数据训练出最好的模型。
打个比方,被动学习像是只会死记硬背、被填鸭式教学的孩子,你教他什么他就学什么。而主动学习像是一个懂得提问的孩子。他会针对自己不熟悉的东西提问(select queries),然后你回答他的问题(annotate data)。这种提问-回答的过程不断循环,高效且持续地更新他对世界的认知。

主动学习跟少数学习(Few-Shot Learning,元学习的一种)虽然目标相同(用最少的训练数据获得最好的效果),但方法思想上有本质不同。后者借助一个外部的meta-learner从以往的经验里学习通用的特征表示方法和更好的初始参数,为新模型的训练提供一个好的起点。然而前者关注的是如何在持续学习的过程中,依靠模型自己对数据价值的判断,有选择性地标注,从而降低训练成本。
除以上三点外,还有很多其他有意思的方向,但都处在早期阶段。限于篇幅,简单介绍如下:
图网络(Graph Neural Network),以图为输入和输出,重构传统的神经网络,用图形结构表示关系推理函数,有希望解决深度学习局限于相关关系而无法做因果推理的问题。
双重学习(Dual Learning),一种新的学习范式,利用两个逻辑上共轭的模型相互训练相互提高(类似于左右手互博),从而减少对训练数据量的依赖。
即兴学习(Improvisational Learning),对“智能”做出新的解读:能够即兴且良好地应对意外情况。和增强学习一样,即兴学习也观察环境并和与之互动,但后者不设定具体的目标(例如,增强学习模型预设利益最大化的目标是在围棋对弈中胜利,在Dota2里拆对方的塔,等等),而是追求最小化环境和模型间的相对信息差。
量子机器学习(Quantum Machine Learning)。量子计算机用完全不同于传统计算机的方式处理信息,成功加速了很多经典算法[13]。可以期待量子计算和机器学习的交叉带来后者性能的质变。同时也可以用机器学习分析和优化量子计算系统。
* 结语
机器学习打破了传统算法对规则的依赖,以数据为驱动,从以往经验里学习,从而能完成某些既定的任务。
得益于海量数据和不断增长的计算能力,机器学习是信息智能时代提高生产力最重要的工具之一。在光荣与梦想的背后,机器学习仍然有系统偏见、解释性、鲁棒性等诸多问题,并且在人权、法律等等公共领域引发广泛的讨论。我们呼吁所有人合理地使用、监管机器学习和其他人工智能技术。今天不论是元学习,增强学习,还是其他方向的一大步都只是人类探索人工智能道路上的一小步。
让我们一起,stay hungry, stay foolish。
参考资料:
- ICML 2018: An AI party in our own backyard. https://peltarion.com/article/icml-2018-an-ai-party-in-our-own-backyard
- A Hackers Guide To Deep Learning’s Secret Sauces: Linear Algebra https://medium.com/@LeonFedden/a-hackers-guide-to-deep-learnings-secret-sauces-linear-algebra-555403c3be16ji’qi’xue’x
- Which machine learning algorithm should I use? https://blogs.sas.com/content/subconsciousmusings/2017/04/12/machine-learning-algorithm-use/
- Sales Gets a Machine-Learning Makeover https://sloanreview.mit.edu/article/sales-gets-a-machine-learning-makeover/
- The Risk Of Machine-Learning Bias. https://www.oliverwyman.com/our-expertise/insights/2018/dec/risk-journal-vol-8/rethinking-tactics/the-risk-of-machine-learning-bias-and-how-to-prevent-it.html
- GDPR fines total €56M in first year as Facebook faces 11 investigations https://9to5mac.com/2019/05/28/gdpr-fines/
- San Francisco bans city use of facial recognition technology tools https://www.latimes.com/business/la-fi-san-francisco-facial-recognition-ban-20190514-story.html
- Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).
- Brown, Tom B., et al. "Adversarial patch." arXiv preprint arXiv:1712.09665 (2017).
- Joaquin Vanschoren. 2018. Meta-Learning: A Survey. arXiv preprint arXiv:1810.03548 (2018).
- Yoshua Bengio on the Turing Award, AI Trends, and ‘Very Unfortunate’ US-China Tensions https://syncedreview.com/2019/06/17/yoshua-bengio-on-the-turing-award-ai-trends-and-very-unfortunate-us-china-tensions/
- Settles, Burr. Active learning literature survey. University of Wisconsin-Madison Department of Computer Sciences, 2009.
- Machine Learning: Research hotspots in the next ten years https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/machine-learning-research-hotspots/