编写多进程爬虫

不管是多进程还是多线程,核心的问题都是任务如何分配,爬虫本身倒不是什么重点,本文的示例代码仅仅是讨论多进程爬虫的编写模式,并不是真实的案例代码,希望能够给你一些启发
1、任务分配
多进程爬虫的任务分配,和多线程一样,通过队列进行分配,先在主进程中将任务push到队列中,多进程启动后,每个进程都尝试从队列里获取任务,这里的任务,在实际应用中可能就是一个需要爬取的url。
2、消费者进程如何退出
任务消费结束后,多进程需要终止,在上一篇多线程爬虫文章中,采取的方法是用非阻塞的方法获取任务,引发异常后判断队列是否为空,若为空则退出线程,今天介绍另一种退出方法。
生成任务时,将一个结束标识push到任务队列中,表明这是最后一个任务,一个进程获得这个标识后,可以确定,队列里已经没有任务可以消费了,所有的进程都需要退出,这个进程将结束标识push到队列中,然后退出。
每个进程获得结束标识后都将结束标识再次push到队列中,然后自身退出,这样就能保证所有的进程最终都能顺利退出。
3、爬取的结果如何落库
每个进程之间是互不影响的,爬取数据后写入数据库,由于进程建立各自的连接,因此也不会影响彼此,但有种情况是个例外,如果你想将爬取到的数据写入到一个文件中,那么多个进程同时操作一个文件就会引发问题。
对于这种情况,只需要一个额外的处理爬取结果的进程就可以了。除了任务队列以外,新增一个爬虫结果的队列,进程爬取数据后,将结果写入到结果队列,同时专门安排一个进程处理这个结果队列,这样就避免了多个进程同时操作一个文件的问题。
4、 多进程爬虫架构图
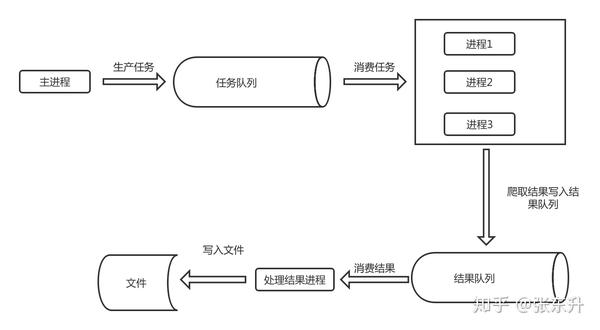

这是一个简单的多进程爬虫的架构图
5、 实例代码
import time, os
from multiprocessing import Process, Queue
def crawl(result_q, task):
"""
真正的爬虫代码在这里写
:param task:
:return:
"""
# sleep模拟处理任务
time.sleep(1)
result_q.put(task)
def worker(task_q, result_q):
while True:
task = task_q.get(True)
if task == 'end':
task_q.put(task)
break
crawl(result_q, task)
pid = os.getpid()
print('进程{pid}获得任务{task}'.format(pid=pid, task=task))
def write_worker(result_q):
while True:
result = result_q.get(True)
if result == 'end':
break
# 将结果写入到文件中
print(result)
# 创建任务队列
task_q = Queue()
for i in range(10):
task_q.put(i)
task_q.put('end')
# 爬虫结果队列
result_q = Queue()
result_process = Process(target=write_worker, args=(result_q, ))
result_process.start()
# 创建多进程
process_lst = []
for i in range(3):
p = Process(target=worker, args=(task_q, result_q))
process_lst.append(p)
# 启动
for p in process_lst:
p.start()
# join
for p in process_lst:
p.join()
result_q.put('end')
result_process.join()
print('执行结束')发布于 2019-08-06 14:02
